Spell correction, also known as:
- Auto correction
- Text correction
- Fixing spelling errors
- Typo tolerance
- "Did you mean?"
and so on, is a software functionality that suggests alternatives to or makes automatic corrections of the text you have typed in. The concept of correcting typed text dates back to the 1960s when computer scientist Warren Teitelman, who also invented the "undo" command, introduced a philosophy of computing called D.W.I.M., or "Do What I Mean." Instead of programming computers to accept only perfectly formatted instructions, Teitelman argued that they should be programmed to recognize obvious mistakes.
The first well-known product to provide spell correction functionality was Microsoft Word 6.0, released in 1993.
There are a few ways spell correction can be done, but it's important to note that there is no purely programmatic way to convert your mistyped "ipone" into "iphone" with decent quality. Mostly, there has to be a dataset the system is based on. The dataset can be:
- A dictionary of properly spelled words, which in turn can be:
- Based on your real data. The idea here is that, for the most part, the spelling in the dictionary made up of your data is correct, and the system tries to find a word that is most similar to the typed word (we'll discuss how this can be done with Manticore shortly).
- Or it can be based on an external dictionary unrelated to your data. The issue that may arise here is that your data and the external dictionary can be too different: some words may be missing in the dictionary, while others may be missing in your data.
- Not just dictionary-based, but also context-aware, e.g., "white ber" would be corrected to "white bear," while "dark ber" would be corrected to "dark beer." The context might not just be a neighboring word in your query, but also your location, time of day, the current sentence's grammar (to change "there" to "their" or not), your search history, and virtually any other factors that can affect your intent.
- Another classic approach is to use previous search queries as the dataset for spell correction. This is even more utilized in autocomplete functionality but makes sense for autocorrect too. The idea is that users are mostly right with spelling, so we can use words from their search history as a source of truth, even if we don't have the words in our documents or use an external dictionary. Context-awareness is also possible here.
Manticore provides the fuzzy search option and the commands CALL QSUGGEST and CALL SUGGEST that can be used for automatic spell correction purposes.
The Fuzzy Search feature allows for more flexible matching by accounting for slight variations or misspellings in the search query. It works similarly to a normal SELECT SQL statement or a /search JSON request but provides additional parameters to control the fuzzy matching behavior.
NOTE: The
fuzzyoption requires Manticore Buddy. If it doesn't work, make sure Buddy is installed.
NOTE: The
fuzzyoption is not available for multi-queries.
SELECT
...
MATCH('...')
...
OPTION fuzzy={0|1}
[, distance=N]
[, preserve={0|1}]
[, layouts='{be,bg,br,ch,de,dk,es,fr,uk,gr,it,no,pt,ru,se,ua,us}']
}Note: When conducting a fuzzy search via SQL, the MATCH clause should not contain any full-text operators except the phrase search operator and should only include the words you intend to match.
- SQL
- SQL with additional filters
- JSON
- SQL with preserve option
- JSON with preserve option
SELECT * FROM mytable WHERE MATCH('someting') OPTION fuzzy=1, layouts='us,ua', distance=2;Example of a more complex Fuzzy search query with additional filters:
SELECT * FROM mytable WHERE MATCH('someting') OPTION fuzzy=1 AND (category='books' AND price < 20);POST /search
{
"table": "test",
"query": {
"bool": {
"must": [
{
"match": {
"*": "ghbdtn"
}
}
]
}
},
"options": {
"fuzzy": true,
"layouts": ["us", "ru"],
"distance": 2
}
}SELECT * FROM mytable WHERE MATCH('hello wrld') OPTION fuzzy=1, preserve=1;POST /search
{
"table": "test",
"query": {
"bool": {
"must": [
{
"match": {
"*": "hello wrld"
}
}
]
}
},
"options": {
"fuzzy": true,
"preserve": 1
}
}+------+-------------+
| id | content |
+------+-------------+
| 1 | something |
| 2 | some thing |
+------+-------------+
2 rows in set (0.00 sec)+------+-------------+
| id | content |
+------+-------------+
| 1 | hello wrld |
| 2 | hello world |
+------+-------------+
2 rows in set (0.00 sec)POST /search
{
"table": "table_name",
"query": {
<full-text query>
},
"options": {
"fuzzy": {true|false}
[,"layouts": ["be","bg","br","ch","de","dk","es","fr","uk","gr","it","no","pt","ru","se","ua","us"]]
[,"distance": N]
[,"preserve": {0|1}]
}
}Note: If you use the query_string, be aware that it does not support full-text operators except the phrase search operator. The query string should consist solely of the words you wish to match.
fuzzy: Turn fuzzy search on or off.distance: Set the Levenshtein distance for matching. The default is2.preserve:0or1(default:0). When set to1, keeps words that don't have fuzzy matches in the search results (e.g., "hello wrld" returns both "hello wrld" and "hello world"). When set to0, only returns words with successful fuzzy matches (e.g., "hello wrld" returns only "hello world"). Particularly useful for preserving short words or proper nouns that may not exist in Manticore Search.layouts: Keyboard layouts for detecting typing errors caused by keyboard layout mismatches (e.g., typing "ghbdtn" instead of "привет" when using wrong layout). Manticore compares character positions across different layouts to suggest corrections. Requires at least 2 layouts to effectively detect mismatches. No layouts are used by default. Use an empty string''(SQL) or array[](JSON) to turn this off. Supported layouts include:be- Belgian AZERTY layoutbg- Standard Bulgarian layoutbr- Brazilian QWERTY layoutch- Swiss QWERTZ layoutde- German QWERTZ layoutdk- Danish QWERTY layoutes- Spanish QWERTY layoutfr- French AZERTY layoutuk- British QWERTY layoutgr- Greek QWERTY layoutit- Italian QWERTY layoutno- Norwegian QWERTY layoutpt- Portuguese QWERTY layoutru- Russian JCUKEN layoutse- Swedish QWERTY layoutua- Ukrainian JCUKEN layoutus- American QWERTY layout
- This demo demonstrates the fuzzy search functionality:
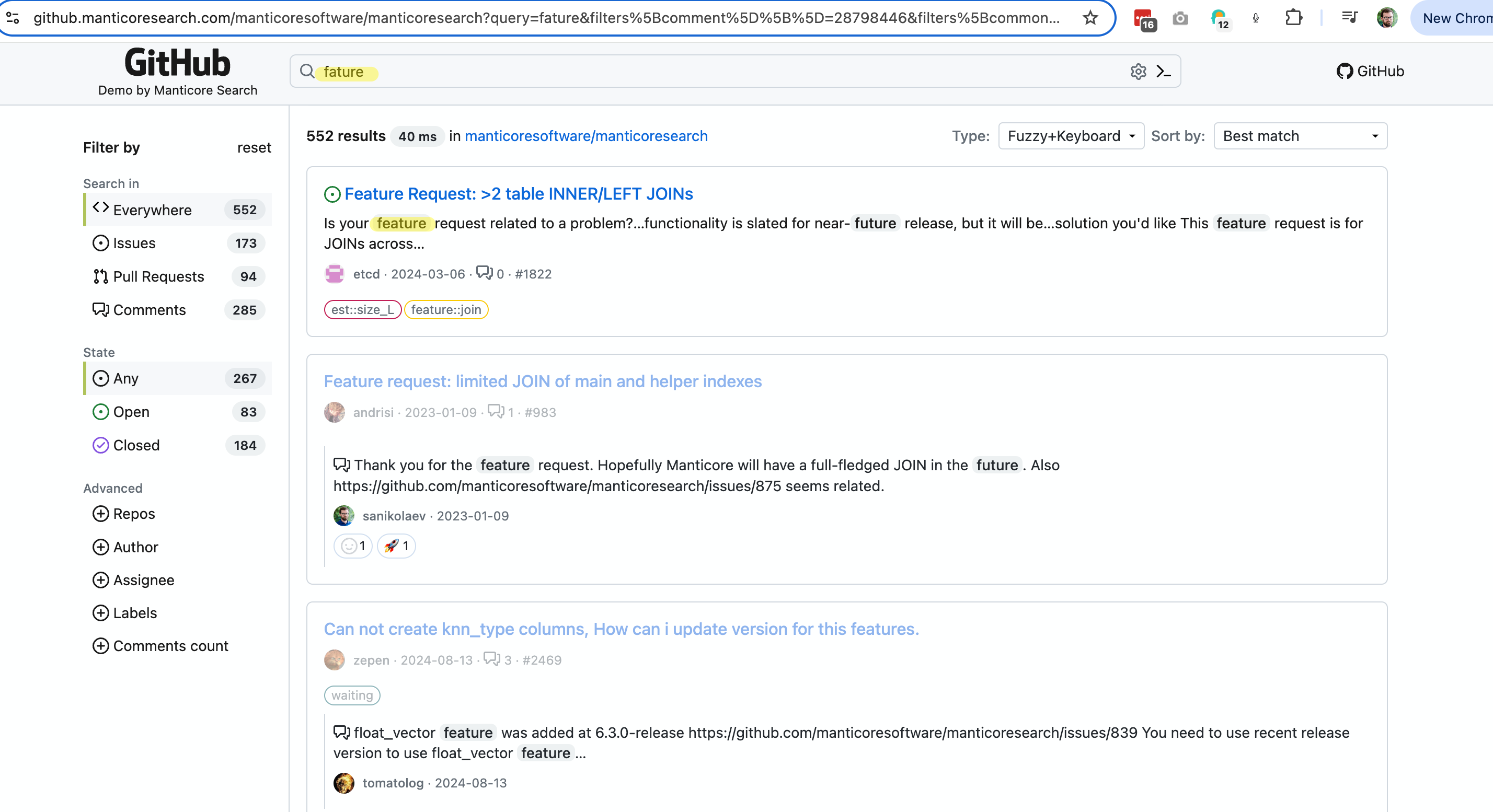
- Blog post about Fuzzy Search and Autocomplete - https://manticoresearch.com/blog/new-fuzzy-search-and-autocomplete/
Both commands are accessible via SQL and support querying both local (plain and real-time) and distributed tables. The syntax is as follows:
CALL QSUGGEST(<word or words>, <table name> [,options])
CALL SUGGEST(<word or words>, <table name> [,options])
options: N as option_name[, M as another_option, ...]These commands provide all suggestions from the dictionary for a given word. They work only on tables with infixing enabled and dict=keywords. They do not work on tables that use dict=keywords_32k. They return the suggested keywords, Levenshtein distance between the suggested and original keywords, and the document statistics of the suggested keyword.
If the first parameter contains multiple words, then:
CALL QSUGGESTwill return suggestions only for the last word, ignoring the rest.CALL SUGGESTwill return suggestions only for the first word.
That's the only difference between them. Several options are supported for customization:
| Option | Description | Default |
|---|---|---|
| limit | Returns N top matches | 5 |
| max_edits | Keeps only dictionary words with a Levenshtein distance less than or equal to N | 4 |
| result_stats | Provides Levenshtein distance and document count of the found words | 1 (enabled) |
| delta_len | Keeps only dictionary words with a length difference less than N | 3 |
| max_matches | Number of matches to keep | 25 |
| reject | Rejected words are matches that are not better than those already in the match queue. They are put in a rejected queue that gets reset in case one actually can go in the match queue. This parameter defines the size of the rejected queue (as reject*max(max_matched,limit)). If the rejected queue is filled, the engine stops looking for potential matches | 4 |
| result_line | alternate mode to display the data by returning all suggests, distances and docs each per one row | 0 |
| non_char | do not skip dictionary words with non alphabet symbols | 0 (skip such words) |
| sentence | Returns the original sentence along with the last word replaced by the matched one. | 0 (do not return the full sentence) |
| force_bigrams | Forces the use of bigrams (2-character n-grams) instead of trigrams for all word lengths, which can improve matching for words with transposition errors | 0 (use trigrams for words ≥6 characters) |
| search_mode | Refines suggestions by performing searches on the index. Accepts 'phrase' for exact phrase matching or 'words' for bag-of-words matching. When enabled, adds a found_docs column showing document counts and re-ranks results by found_docs descending, then by distance ascending. |
N/A (disabled by default) |
To show how it works, let's create a table and add a few documents to it.
create table products(title text) min_infix_len='2';
insert into products values (0,'Crossbody Bag with Tassel'), (0,'microfiber sheet set'), (0,'Pet Hair Remover Glove');As you can see, the mistyped word "crossbUdy" gets corrected to "crossbody". By default, CALL SUGGEST/QSUGGEST return:
distance- the Levenshtein distance which means how many edits they had to make to convert the given word to the suggestiondocs- number of documents containing the suggested word
To disable the display of these statistics, you can use the option 0 as result_stats.
- Example
call suggest('crossbudy', 'products');+-----------+----------+------+
| suggest | distance | docs |
+-----------+----------+------+
| crossbody | 1 | 1 |
+-----------+----------+------+If the first parameter is not a single word, but multiple, then CALL SUGGEST will return suggestions only for the first word.
- Example
call suggest('bagg with tasel', 'products');+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| bag | 1 | 1 |
+---------+----------+------+If the first parameter is not a single word, but multiple, then CALL SUGGEST will return suggestions only for the last word.
- Example
CALL QSUGGEST('bagg with tasel', 'products');+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| tassel | 1 | 1 |
+---------+----------+------+Adding 1 as sentence makes CALL QSUGGEST return the entire sentence with the last word corrected.
- Example
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence);+-------------------+----------+------+
| suggest | distance | docs |
+-------------------+----------+------+
| bag with tassel | 1 | 1 |
+-------------------+----------+------+The 1 as result_line option changes the way the suggestions are displayed in the output. Instead of showing each suggestion in a separate row, it displays all suggestions, distances, and docs in a single row. Here's an example to demonstrate this:
CALL QSUGGEST('bagg with tasel', 'products', 1 as result_line);+----------+--------+
| name | value |
+----------+--------+
| suggests | tassel |
| distance | 1 |
| docs | 1 |
+----------+--------+The force_bigrams option can help with words that have transposition errors, such as "ipohne" vs "iphone". By using bigrams instead of trigrams, the algorithm can better handle character transpositions.
CALL SUGGEST('ipohne', 'products', 1 as force_bigrams);+--------+----------+------+
| suggest| distance | docs |
+--------+----------+------+
| iphone | 2 | 1 |
+--------+----------+------+The search_mode option enhances suggestions by performing actual searches on the index to count how many documents contain each suggested phrase or combination of words. This helps rank suggestions based on real document relevance rather than just dictionary statistics.
The option accepts two values:
'phrase'- Performs exact phrase searches. For example, when suggesting "bag with tassel", it searches for the exact phrase"bag with tassel"and counts documents containing these words as an adjacent phrase.'words'- Performs bag-of-words searches. For example, when suggesting "bag with tassel", it searches forbag with tassel(without quotes) and counts documents containing all these words, regardless of order or intervening words.
NOTE: The
search_modeoption only works whensentenceis enabled (i.e., when the input contains multiple words). For single-word queries,search_modeis ignored.
NOTE: Performance consideration: Each suggestion candidate triggers a separate search query against the index. If you need to evaluate many candidates, consider using a lower
limitvalue to reduce the number of searches performed.
When search_mode is enabled, results include a found_docs column showing the document count for each suggestion, and results are re-ranked by found_docs descending, then by distance ascending.
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence, 'phrase' as search_mode);+-------------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+-------------------+----------+------+-------------+
| bag with tassel | 1 | 13 | 10 |
| bag with tazer | 2 | 27 | 3 |
+-------------------+----------+------+-------------+-- With phrase matching: finds exact phrases only
CALL QSUGGEST('test carp', 'products', 1 as sentence, 'phrase' as search_mode);
-- With words matching: finds documents with all words regardless of order
CALL QSUGGEST('test carp', 'products', 1 as sentence, 'words' as search_mode);-- Phrase mode results:
+----------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+----------------+----------+------+-------------+
| test car | 1 | 17 | 5 |
| test carpet | 2 | 19 | 4 |
+----------------+----------+------+-------------+
-- Words mode results (more matches for "test carpet" due to word separation):
+----------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+----------------+----------+------+-------------+
| test carpet | 2 | 19 | 19 |
| test car | 1 | 17 | 5 |
+----------------+----------+------+-------------+Understanding the difference:
- Phrase matching (
'phrase'): Searches for exact sequences. The query"test carpet"matches only documents where these words appear together in that exact order (e.g., "test carpet cleaning" matches, but "test the carpet" or "carpet test" do not). - Bag-of-words matching (
'words'): Searches for all words to exist in the document, order doesn't matter. The querytest carpetmatches any document containing both "test" and "carpet" anywhere (e.g., "test the carpet", "test red carpet", "carpet test" all match).
- This interactive course shows how
CALL SUGGESTworks in a little web app.
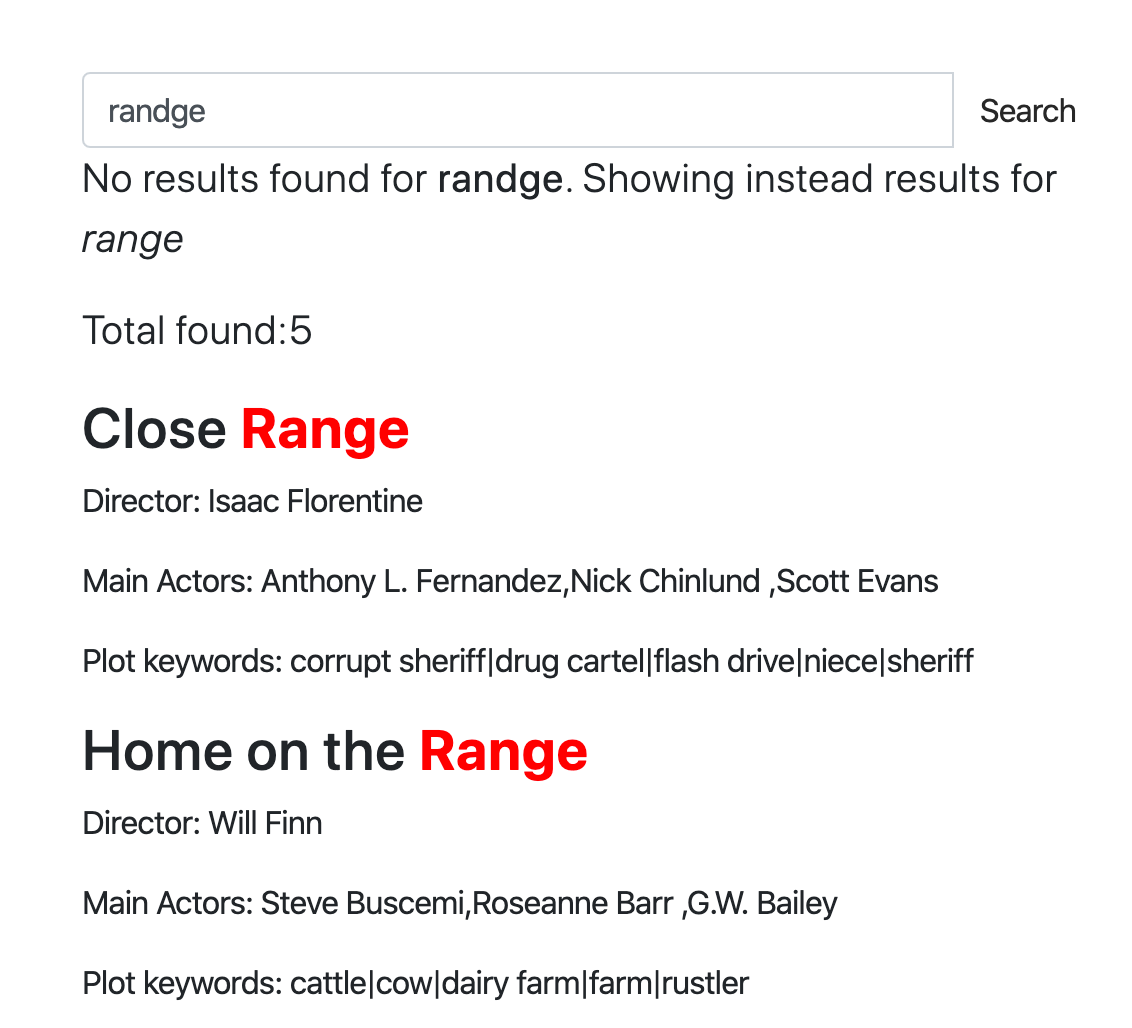
Query cache stores compressed result sets in memory and reuses them for subsequent queries when possible. You can configure it using the following directives:
- qcache_max_bytes, a limit on the RAM usage for cached query storage. Defaults to 16 MB. Setting
qcache_max_bytesto 0 completely disables the query cache. - qcache_thresh_msec, the minimum wall query time to cache. Queries that complete faster than this will not be cached. Defaults to 3000 msec, or 3 seconds.
- qcache_ttl_sec, cached entry TTL, or time to live. Queries will stay cached for this duration. Defaults to 60 seconds, or 1 minute.
These settings can be changed on the fly using the SET GLOBAL statement:
mysql> SET GLOBAL qcache_max_bytes=128000000;These changes are applied immediately, and cached result sets that no longer satisfy the constraints are immediately discarded. When reducing the cache size on the fly, MRU (most recently used) result sets win.
Query cache operates as follows. When enabled, every full-text search result is completely stored in memory. This occurs after full-text matching, filtering, and ranking, so essentially we store total_found {docid,weight} pairs. Compressed matches can consume anywhere from 2 bytes to 12 bytes per match on average, mostly depending on the deltas between subsequent docids. Once the query is complete, we check the wall time and size thresholds, and either save the compressed result set for reuse or discard it.
Note that the query cache's impact on RAM is not limited byqcache_max_bytes! If you run, for example, 10 concurrent queries, each matching up to 1M matches (after filters), then the peak temporary RAM usage will be in the range of 40 MB to 240 MB, even if the queries are fast enough and don't get cached.
Queries can use cache when the table, full-text query (i.e.,MATCH() contents), and ranker all match, and filters are compatible. This means:
- The full-text part within
MATCH()must be a bytewise match. Add a single extra space, and it's now a different query as far as the query cache is concerned. - The ranker (and its parameters, if any, for user-defined rankers) must be a bytewise match.
- The filters must be a superset of the original filters. You can add extra filters and still hit the cache. (In this case, the extra filters will be applied to the cached result.) But if you remove one, that will be a new query again.
Cache entries expire with TTL and also get invalidated on table rotation, or on TRUNCATE, or on ATTACH. Note that currently, entries are not invalidated on arbitrary RT table writes! So a cached query might return older results for the duration of its TTL.
You can inspect the current cache status with SHOW STATUS through the qcache_XXX variables:
mysql> SHOW STATUS LIKE 'qcache%';
+-----------------------+----------+
| Counter | Value |
+-----------------------+----------+
| qcache_max_bytes | 16777216 |
| qcache_thresh_msec | 3000 |
| qcache_ttl_sec | 60 |
| qcache_cached_queries | 0 |
| qcache_used_bytes | 0 |
| qcache_hits | 0 |
+-----------------------+----------+
6 rows in set (0.00 sec)Collations primarily impact string attribute comparisons. They define both the character set encoding and the strategy Manticore employs for comparing strings when performing ORDER BY or GROUP BY with a string attribute involved.
String attributes are stored as-is during indexing, and no character set or language information is attached to them. This is fine as long as Manticore only needs to store and return the strings to the calling application verbatim. However, when you ask Manticore to sort by a string value, the request immediately becomes ambiguous.
First, single-byte (ASCII, ISO-8859-1, or Windows-1251) strings need to be processed differently than UTF-8 strings, which may encode each character with a variable number of bytes. Thus, we need to know the character set type to properly interpret the raw bytes as meaningful characters.
Second, we also need to know the language-specific string sorting rules. For example, when sorting according to US rules in the en_US locale, the accented character ï (small letter i with diaeresis) should be placed somewhere after z. However, when sorting with French rules and the fr_FR locale in mind, it should be placed between i and j. Some other set of rules might choose to ignore accents altogether, allowing ï and i to be mixed arbitrarily.
Third, in some cases, we may require case-sensitive sorting, while in others, case-insensitive sorting is needed.
Collations encapsulate all of the following: the character set, the language rules, and the case sensitivity. Manticore currently provides four collations:
libc_cilibc_csutf8_general_cibinary
The first two collations rely on several standard C library (libc) calls and can thus support any locale installed on your system. They provide case-insensitive (_ci) and case-sensitive (_cs) comparisons, respectively. By default, they use the C locale, effectively resorting to bytewise comparisons. To change that, you need to specify a different available locale using the collation_libc_locale directive. The list of locales available on your system can usually be obtained with the locale command:
$ locale -a
C
en_AG
en_AU.utf8
en_BW.utf8
en_CA.utf8
en_DK.utf8
en_GB.utf8
en_HK.utf8
en_IE.utf8
en_IN
en_NG
en_NZ.utf8
en_PH.utf8
en_SG.utf8
en_US.utf8
en_ZA.utf8
en_ZW.utf8
es_ES
fr_FR
POSIX
ru_RU.utf8
ru_UA.utf8The specific list of system locales may vary. Consult your OS documentation to install additional needed locales.
utf8_general_ci and binary locales are built-in into Manticore. The first one is a generic collation for UTF-8 data (without any so-called language tailoring); it should behave similarly to the utf8_general_ci collation in MySQL. The second one is a simple bytewise comparison.
Collation can be overridden via SQL on a per-session basis using the SET collation_connection statement. All subsequent SQL queries will use this collation. Otherwise, all queries will use the server default collation or as specified in the collation_server configuration directive. Manticore currently defaults to the libc_ci collation.
Collations affect all string attribute comparisons, including those within ORDER BY and GROUP BY, so differently ordered or grouped results can be returned depending on the collation chosen. Note that collations don't affect full-text searching; for that, use the charset_table.
When Manticore executes a fullscan query, it can either use a plain scan to check every document against the filters or employ additional data and/or algorithms to speed up query execution. Manticore uses a cost-based optimizer (CBO), also known as a "query optimizer" to determine which approach to take.
The CBO can also enhance the performance of full-text queries. See below for more details.
The CBO may decide to replace one or more query filters with one of the following entities if it determines that doing so will improve performance:
- A docid index utilizes a special docid-only secondary index stored in files with the
.sptextension. Besides improving filters on document IDs, the docid index is also used to accelerate document ID to row ID lookups and to speed up the application of large killlists during daemon startup. - A columnar scan relies on columnar storage and can only be used on a columnar attribute. It scans every value and tests it against the filter, but it is heavily optimized and is typically faster than the default approach.
- Secondary indexes are generated for all attributes (except JSON) by default. They use the PGM index along with Manticore's built-in inverted index to retrieve the list of row IDs corresponding to a value or range of values. Secondary indexes are stored in files with the
.spidxand.spjidxextensions. For information on how to generate secondary indexes over JSON attributes, see json_secondary_indexes.
The optimizer estimates the cost of each execution path using various attribute statistics, including:
- Information on the data distribution within an attribute (histograms, stored in
.sphifiles). Histograms are generated automatically when data is indexed and serve as the primary source of information for the CBO. - Information from PGM (secondary indexes), which helps estimate the number of document lists to read. This assists in gauging doclist merge performance and in selecting the appropriate merge algorithm (priority queue merge or bitmap merge).
- Columnar encoding statistics, employed to estimate columnar data decompression performance.
- A columnar min-max tree. While the CBO uses histograms to estimate the number of documents left after applying the filter, it also needs to determine how many documents the filter had to process. For columnar attributes, partial evaluation of the min-max tree serves this purpose.
- Full-text dictionary. The CBO utilizes term stats to estimate the cost of evaluating the full-text tree.
The optimizer computes the execution cost for every filter used in a query. Since certain filters can be replaced with several different entities (e.g., for a document id, Manticore can use a plain scan, a docid index lookup, a columnar scan (if the document id is columnar), and a secondary index), the optimizer evaluates all available combinations. However, there is a maximum limit of 1024 combinations.
To estimate query execution costs, the optimizer calculates the estimated costs of the most significant operations performed when executing the query. It uses preset constants to represent the cost of each operation.
The optimizer compares the costs of each execution path and chooses the path with the lowest cost to execute the query.
When working with full-text queries that have filters by attributes, the query optimizer decides between two possible execution paths. One is to execute the full-text query, retrieve the matches, and use filters. The other is to replace filters with one or more entities described above, fetch rowids from them, and inject them into the full-text matching tree. This way, full-text search results will intersect with full-scan results. The query optimizer estimates the cost of full-text tree evaluation and the best possible path for computing filter results. Using this information, the optimizer chooses the execution path.
Another factor to consider is multithreaded query execution (when pseudo_sharding is enabled). The CBO is aware that some queries can be executed in multiple threads and takes this into account. The CBO prioritizes shorter query execution times (i.e., latency) over throughput. For instance, if a query using a columnar scan can be executed in multiple threads (and occupy multiple CPU cores) and is faster than a query executed in a single thread using secondary indexes, multithreaded execution will be preferred.
Queries using secondary indexes and docid indexes always run in a single thread, as benchmarks indicate that there is little to no benefit in making them multithreaded.
At present, the optimizer only uses CPU costs and does not take memory or disk usage into account.