Manticore Search 是一款面向搜索和分析场景打造的高性能多存储数据库,提供极速全文检索、实时索引,以及向量搜索和列式存储等高级功能,便于高效进行数据分析。它既能处理小规模数据集,也能应对大规模数据集,为现代应用提供无缝扩展能力和强大的洞察力。
作为一款开源数据库(可在 GitHub 获取),Manticore Search 于 2017 年创建,作为 Sphinx Search 引擎的延续。我们的开发团队继承了 Sphinx 的所有最佳特性,并在此基础上大幅增强了功能,同时修复了数百个 bug(详见我们的 Changelog)。Manticore Search 是一款现代、快速、轻量的数据库,拥有出色的全文检索能力,并且几乎是对其前身的彻底重写。
Manticore Search 支持将由你的机器学习模型生成的嵌入添加到每个文档中,然后对其进行 nearest-neighbor search。这使你可以构建相似度搜索、推荐、语义搜索、conversational search 和基于 NLP 算法的相关性排序等功能,其中还包括图像、视频和声音搜索。
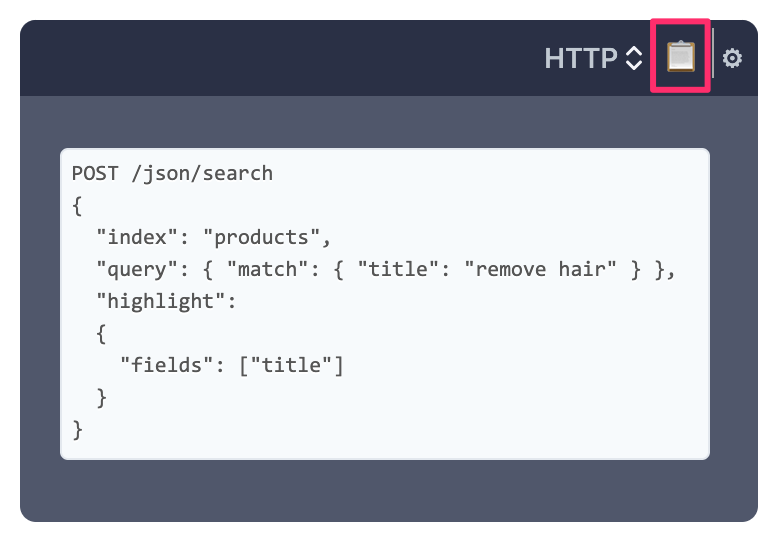
Manticore Search 支持在现有的向量化表上进行 conversational search。它会使用 KNN 搜索检索最相关的行,将这些行与对话历史一起作为 LLM 的上下文,并且可以通过 SQL CALL CHAT 或 HTTP JSON /search 端点进行应答。
Manticore Search 支持通过 SQL 和 JSON 执行 JOIN 查询,让你可以把多个表中的数据组合起来。
Manticore Search 采用智能查询并行化,以降低响应时间,并在需要时充分利用所有 CPU 核心。
基于代价的查询优化器会使用关于已索引数据的统计信息,评估给定查询的不同执行计划的相对成本。这样优化器就能在综合考虑已索引数据规模、查询复杂度和可用资源等因素后,确定检索目标结果时最有效的执行方案。
Manticore 提供 行式和列式存储选项,以适配不同规模的数据集。传统且默认的行式存储适用于各种规模的数据集 - 小型、中型和大型;而列式存储则通过 Manticore Columnar Library 提供,面向更大的数据集。这些存储方式的关键区别在于,行式存储为了获得最佳性能,需要将所有属性(全文字段除外)保留在 RAM 中,而列式存储则不需要,因此 RAM 占用更低,但性能可能会略慢一些(https://db-benchmarks.com/ 上的统计数据也证明了这一点)。
Manticore Columnar Library 使用 Piecewise Geometric Model index,它利用索引键与其在内存中位置之间的学习映射。这种映射十分紧凑,再加上独特的递归构建算法,使 PGM-index 在空间占用上远超传统索引,同时仍能提供一流的查询和更新性能。所有数值字段和字符串字段默认都开启二级索引,json 属性也可以启用。
Manticore 的原生语法是 SQL,并支持通过 HTTP 和 MySQL 协议使用 SQL,因此可以在任何编程语言中通过常见的 mysql 客户端进行连接。
对于更偏编程化的数据和 schema 管理方式,Manticore 提供 HTTP JSON 协议,类似 Elasticsearch 的方式。
Manticore 支持 type='sharding' 表,可以在单节点或复制集群中透明地将读写分发到多个物理分片,从而提升写入扩展性,同时简化路由、故障切换和运维管理。
Manticore 为 MySQL、HTTP/HTTPS、分布式远程代理以及复制相关操作提供内置的 身份验证和授权,支持用户、Bearer token 和细粒度权限控制。
你可以执行与 Elasticsearch 兼容的 insert 和 replace JSON 查询,这样就能将 Manticore 与 Logstash(版本 < 7.13)、Filebeat 以及 Beats 家族中的其他工具一起使用。
可在线或通过配置文件轻松创建、更新和删除表。
Manticore Search 守护进程使用 C++ 开发,启动速度快,内存利用率高。底层优化进一步增强了性能。另一个关键组件 Manticore Buddy 使用 PHP 编写,用于那些不需要闪电般响应速度或极高处理能力的高层功能。尽管为 C++ 代码做贡献可能更具挑战,但使用 Manticore Buddy 添加新的 SQL/JSON 命令应该是一个相对直接的过程。
新添加或更新的文档可以立即读取。
我们提供 免费的交互式课程,让学习变得轻松无负担。
虽然 Manticore 并不完全符合 ACID,但它支持用于原子性变更的隔离事务,以及用于安全写入的二进制日志。
数据可以分布到各个服务器和数据中心,任意一个 Manticore Search 节点都可以同时作为负载均衡器和数据节点。Manticore 使用 Galera library 实现几乎同步的多主 复制,从而确保所有节点的数据一致性,防止数据丢失,并提供出色的复制性能。
Manticore 配备了外部工具 manticore-backup,以及 BACKUP SQL 命令,以简化数据备份和恢复流程。或者,你也可以使用 mysqldump 来 制作逻辑备份。
Manticore 的 indexer 工具和完整的配置语法,可以轻松同步来自 MySQL、PostgreSQL、ODBC 兼容数据库、XML 和 CSV 等来源的数据。
你可以通过 FEDERATED engine 或 ProxySQL 将 Manticore Search 与 MySQL/MariaDB 服务器集成。
你可以使用 Apache Superset 和 Grafana 可视化存储在 Manticore 中的数据。还可以使用多种 MySQL 工具交互式开发 Manticore 查询,例如 HeidiSQL 和 DBForge。
你也可以将 Manticore Search 与 Kibana 一起使用。
Manticore 提供一种特殊的表类型,即“percolate”表,它允许你搜索查询而不是数据,因此非常适合用于过滤全文数据流。只需把查询存入表中,将每批文档发送给 Manticore Search 处理数据流,就能只接收与已存查询匹配的结果。
Manticore Search 用途广泛,可应用于多种场景,包括:
-
全文检索:
- 非常适合电商平台,借助自动补全和模糊搜索等功能,提供快速而准确的商品搜索。
- 非常适合内容密集型网站,让用户能够快速找到相关的文章或文档。
-
数据分析:
- 使用 Beats/Logstash、Vector.dev、Fluentbit 将数据导入 Manticore Search。
- 借助 Manticore 的列式存储和 OLAP 能力,高效分析大规模数据集。
- 以极低延迟对 TB 级数据执行复杂查询。
- 使用 Kibana、Grafana 或 Apache Superset 可视化数据。
-
会话与 AI 搜索:
- 在现有向量化内容之上构建问答和助手体验。
- 使用 KNN 检索和对话历史,通过 conversational search 为答案提供依据。
-
分面搜索:
- 允许用户按价格、品牌或日期等类别筛选搜索结果,获得更精细的搜索体验。
-
地理空间搜索:
- 利用 Manticore 的地理空间能力实现基于位置的搜索,例如查找附近的餐厅或商店。
-
拼写纠错:
- 自动纠正用户在搜索查询中的拼写错误,以提升搜索准确性和用户体验。
-
自动补全:
- 在用户输入时实时提供建议,提升搜索可用性和速度。
-
数据流过滤:
- 使用 percolate 表高效过滤和处理实时数据流,例如社交媒体流或日志数据。
- 架构:arm64 或 x86_64
- 操作系统:基于 Debian 的系统(例如 Debian、Ubuntu、Mint)、基于 RHEL 的系统(例如 RHEL、CentOS、Alma、Oracle Linux、Amazon Linux)、Windows 或 MacOS。
- Manticore Columnar Library,它提供 列式存储 和 二级索引,要求 CPU 支持 SSE >= 4.2。
- 不需要特定的磁盘空间或 RAM 要求。一个空的 Manticore Search 实例只会占用大约 40MB 的 RSS 内存。