Выпуск: 30 марта 2026 года
Этот выпуск приносит более широкий пересмотр упаковки, новые опции API_URL и API_TIMEOUT для авто-встраивания моделей, гибридный поиск, поддержку резервного копирования и восстановления, совместимую с S3, более быстрое обслуживание RT-таблиц с N-сторонними слияниями и параллельным OPTIMIZE, префильтрацию KNN и подготовленные выражения, совместимые с MySQL.
- ⚠️ v25.0.0 PR #123 Критическое изменение: обновлён MCL до версии 13.0.0, добавлены
API_URLиAPI_TIMEOUTдля авто-встраивающих моделей. Это затрагивает вас, если вы используете авто-встраивающие модели или управляете MCL отдельно от демона, потому что Manticore 25.0.0 требует MCL 13.0.0 и не совместим со старыми версиями MCL; обновите демон и MCL вместе, и откат безопасен только если вы также восстановите соответствующую старую версию MCL. - ⚠️ v24.0.0 Issue #4343 Критическое изменение: внутренняя версия протокола репликации увеличена, и добавлено отслеживание эпохи кластера, чтобы восстанавливающиеся узлы могли обнаруживать, когда членство таблиц в кластере изменилось, пока они были отключены, и использовать SST вместо сбоя во время восстановления IST. Это затрагивает вас только если вы используете кластеры репликации: кластеры репликации со смешанными версиями не совместимы через это изменение, поэтому обновите узлы кластера вместе, и откат безопасен только до того, как новый протокол репликации будет использован в кластере.
- ⚠️ v23.0.0 Issue #4364 Критическое изменение: введена версия формата индекса 69 для поддержки новых опций токенизации биграмм, включая режимы
bigram_delimiterи цифро-зависимые режимыbigram_index. Это затрагивает вас, если вы используете эти опции биграмм или если вы перестраиваете индексы и позже вам нужно открыть перезаписанные индексы в старой версии Manticore: существующие старые индексы остаются читаемыми, но индексы, перестроенные или вновь записанные в формате 69, не совместимы со старыми версиями Manticore, поэтому откат безопасен только до того, как такие индексы будут перезаписаны. - ⚠️ v22.0.0 Issue #4301 Критическое изменение: генерация встраиваний для RT-таблиц вынесена из фазы коммита и реплицируется как векторные данные. Это затрагивает вас, если вы используете кластеры репликации с RT-таблицами, у которых есть
model_name: это сохраняет векторы, предоставленные пользователем, предотвращает регенерацию разных встраиваний на репликах и улучшает производительность авто-встраиваний при использовании с репликацией, но кластеры репликации со смешанными версиями не совместимы через это изменение. Обновите узлы кластера вместе; откат безопасен только до того, как новый протокол репликации будет использован в кластере. - ⚠️ v21.0.0 PR #138 Критическое изменение: обновлён MCL до версии 12.0.0 и увеличено требование к KNN API для поддержки адаптивного раннего завершения KNN во время обхода HNSW. Это затрагивает вас, если вы управляете MCL отдельно от демона или выполняете KNN-запросы, которые полагаются на предыдущее поведение исследования кандидатов или выбор пограничных результатов: Manticore 21.0.0 требует MCL 12.0.0 с новым интерфейсом KNN, и с этой библиотекой поиск KNN может остановиться раньше, как только будет найдено достаточно кандидатов, что может изменить, какие кандидаты исследуются и возвращаются. Существующие данные остаются совместимыми, и специальная миграция не требуется, но обновите демон и MCL вместе; откат безопасен только если вы также восстановите соответствующую старую версию MCL.
- ⚠️ v19.0.0 Issue #4103 Критическое изменение: добавлена префильтрация KNN. Это затрагивает вас, если вы выполняете KNN-запросы вместе с фильтрами атрибутов, потому что фильтры теперь могут применяться во время поиска KNN вместо только после выбора кандидатов. Это изменяет поведение выбора результатов для отфильтрованных KNN-запросов, отдавая приоритет отфильтрованным ближайшим соседям; специальная миграция не требуется, но запросы, полагающиеся на предыдущее поведение результатов после фильтрации, могут возвращать другие результаты после обновления. Откат возможен, так как эта функция не вносит изменений в формат индекса или протокола.
- ⚠️ v18.0.0 Issue #4261 Критическое изменение: введена версия формата индекса 68 для исправления обработки макета словаря
hitless_words. Это затрагивает вас, если вы перестраиваете или вновь записываете индексы и позже вам нужно открыть их в старой версии Manticore: существующие старые индексы остаются читаемыми, но любые индексы, перестроенные или вновь записанные в новом формате, не совместимы со старыми версиями Manticore, поэтому откат безопасен только до того, как такие индексы будут перезаписаны.
- 🆕 v25.0.0 PR #4357 Изменение упаковки:
manticoreтеперь является пакетом-сборкой для deb и rpm. Он включает демон, инструменты, конвертер, заголовки для разработки, данные ICU, пакеты зависимостей (manticore-columnar-lib,manticore-backup,manticore-buddy,manticore-executor,manticore-load,manticore-galeraиmanticore-tzdata, где применимо), а также встроенные языковые пакеты для немецкого, английского и русского языков вместе с поддержкой Jieba. Украинский лемматизатор не включен; установите его отдельно, следуя инструкциям для Debian/Ubuntu или RHEL/CentOS. При обновлении с предыдущей структуры пакетов обычно можно просто установить пакетmanticore. Если старые разделенные пакеты вызывают конфликты, удалите их с помощьюapt remove 'manticore*'илиyum remove 'manticore*', а затем установитеmanticore. Эта очистка не удаляет ваши существующие данные или конфигурацию.
- 🆕 v24.4.0 PR #4091 Улучшена компактизация RT-таблиц путем добавления N-way объединений дисковых чанков и параллельных задач
OPTIMIZE, сокращая время, необходимое для объединения многих дисковых чанков, и вводя новые параметрыmerge_chunks_per_jobиparallel_chunk_merges. - 🆕 v24.3.0 PR #133 Обновлён Manticore Backup до версии 1.10.0, добавлена поддержка резервного копирования и восстановления в S3-совместимые хранилища, включая AWS S3, MinIO, Wasabi и Cloudflare R2.
- 🆕 v24.2.0 Issue #2079 Добавлен гибридный поиск с Reciprocal Rank Fusion (
fusion_method='rrf'), позволяющий SQL и JSON запросам объединять полнотекстовые и KNN результаты, ранжировать их с помощьюhybrid_score()и поддерживать несколько KNN подзапросов в одном объединенном наборе результатов. - 🆕 v24.1.0 PR #141 Обновлён MCL до версии 12.4.1, добавлена поддержка GGUF-квантованных локальных моделей эмбедингов, моделей кодировщика T5 и управляемых моделей Hugging Face через скачивание с токенной авторизацией.
- 🆕 v23.2.0 PR #4372 Обновлён Buddy до версии 3.44.0, добавлена поддержка нечеткого поиска для запросов, затрагивающих несколько таблиц.
- 🆕 v23.1.0 PR #4357 Добавлен новый пакет-сборка Manticore для deb и rpm, заменяющий предыдущий метапакет для упрощения установки и распространения входящих компонентов.
- 🆕 v21.1.0 PR #4352 Обновлён MCL до версии 12.1.0, улучшена производительность раннего завершения KNN и добавлено более эффективное кодирование 64–битных значений.
- 🆕 v19.2.0 PR #4306 Обновлён MCL до версии 11.1.0, добавлена поддержка кеша кодеков.
- 🆕 v19.1.0 PR #4271 Обновлён Buddy до версии 3.43.0, включая улучшенную обработку метрик.
- 🆕 v19.0.3 Issue #4303 Добавлена отдельная обработка
interactive_timeoutиwait_timeoutдля SQL соединений, чтобы интерактивные клиенты и неинтерактивные клиенты могли использовать различные интервалы ожидания в простое, как в MySQL. - 🆕 v17.6.0 Issue #1124 Добавлена поддержка подготовленных выражений, совместимых с MySQL, включая обработку prepare/execute через бинарный протокол и проверку привязки параметров.
- 🪲 v24.2.3 Issue #4375 Исправлены ложные полнотекстовые совпадения, когда
max_query_timeпрерывает запросы с использованием операторов, таких какNOTNEAR,MAYBEили отрицание, поэтому прерванные поиски больше не возвращают строки, которые фактически не удовлетворяют запросу. - 🪲 v24.2.2 Issue #4398 Исправлена статистика времени запросов, чтобы журнал запросов, глобальные счётчики и тайминги
SHOW STATUSдля каждой таблицы оставались согласованными, а внутренние запросы Buddy больше не искажают статистику демона, видимую пользователю. - 🪲 v24.2.1 PR #653 Обновлён Buddy до версии 3.44.1, исправлена некорректная обработка пустых полезных нагрузок запросов по умолчанию.
- 🪲 v24.1.3 PR #4396 Исправлен ручной запуск
searchdна macOS, чтобы SQL-команды с поддержкой Buddy больше не завершались ошибкой из-за загрузки старой системнойlibcurl; теперь при запуске автоматически предпочитается curl от Homebrew, аMANTICORE_CURL_LIBпо-прежнему доступна для явного переопределения. - 🪲 v24.1.2 PR #4394 Исправлены сборки пакетов для macOS, чтобы SQL-команды с поддержкой Buddy больше не завершались ошибкой из-за того, что
searchdлинкуется с несовместимойlibcurl; пакет теперь предпочитает curl от Homebrew и поддерживает переопределениеMANTICORE_CURL_LIBво время выполнения. - 🪲 v24.1.1 Issue #4388 Исправлена репликация в кластерах, когда транзакция содержит дублирующиеся идентификаторы документов, чтобы реплики больше не теряли строки, в то время как донор корректно удаляет дубликаты.
- 🪲 v24.0.1 Issue #4354 Исправлена обработка
UPDATE, когда изменённый атрибут также должен отключить свой вторичный индекс, предотвращая некорректные предупреждения и несогласованное состояние вторичного индекса. - 🪲 v23.0.2 PR #4370 Обновлён MCL до версии 12.1.1, исправлены сбои при генерации авто-эмбеддингов, когда текст содержит некорректный UTF-8, включая вставки в таблицы с
html_strip=1. - 🪲 v23.0.1 PR #4371 Исправлено отсутствие блокировки сегментов RT во время валидации эмбеддингов, предотвращая сбои и состояния гонки в операциях, связанных с эмбеддингами.
- 🪲 v21.0.3 Issue #4315 Исправлены вставки в таблицы с колонками авто-эмбеддингов, чтобы значения MVA сохранялись, а не хранились пустыми.
- 🪲 v21.0.2 PR #4277 Обновлён Buddy до версии 3.43.1, исправлена обработка автодополнения и нечёткого поиска для терминов с числовыми префиксами и подстановочными звёздочками.
- 🪲 v21.0.1 PR #4349 Исправлен сбой при генерации эмбеддингов для таблиц, использующих колоночное хранилище.
- 🪲 v19.2.5 PR #4333 Обновлён Executor до версии 1.4.1, переход на загрузку исходников PHP с GitHub вместо php.net для избежания ссылок, защищённых CAPTCHA, и обновление встроенного PHP до 8.4.18.
- 🪲 v19.2.4 Issue #4314 Исправлены колонки
float_vectorна основе моделей для поддержки явного пустогоFROM='', что теперь корректно означает «использовать все текстовые/строковые поля». - 🪲 v19.2.3 Issue #4315 Исправлены вставки в таблицы с колонками авто-эмбеддингов
float_vector, чтобы значения MVA сохранялись, а не хранились пустыми. - 🪲 v19.2.2 Issue #4297 Исправлена команда
IMPORT TABLEдля корректного копирования внешних файлов, включаяhitless_words, чтобы импортированные таблицы больше не ссылались на отсутствующие внешние файлы после импорта. - 🪲 v19.2.1 Issue #4229 Исправлены результаты
LEFT JOINдля выдачи корректных значений MySQLNULLвместо строкиNULL, улучшая совместимость с нативными клиентами и драйверами MySQL. - 🪲 v19.0.4 Issue #4308 Исправлены сбои демона, вызванные фильтрацией по сохранённым/полнотекстовым полям, таким как
WHERE title='test'; эти запросы теперь возвращают ошибку вместо сбоя. - 🪲 v19.0.2 PR #4311 Исправлены сбои в HTTP-запросах
/sql?mode=rawс несколькими инструкциями, использующих.@files, за которыми следуетSHOW META. - 🪲 v19.0.1 Issue #4103 Обновлён MCL до версии 11.0.0 для поддержки предфильтрации KNN.
- 🪲 v18.0.1 Issue #4293 Исправлена команда
ALTER TABLE ... ADD COLUMNдля колонок авто-эмбеддинговfloat_vector, чтобыmodel_nameиFROMсохранялись корректно, а не заменялись наknn_dims='0'. - 🪲 v17.6.6 Issue #4264 Исправлена обработка EOF kqueue на macOS для предотвращения ложных предупреждений о получении HTTP, таких как
Resource temporarily unavailable, во время обработки запросов. - 🪲 v17.6.5 PR #4296 Исправлены оценка количества документов и стоимости для полнотекстовых узлов
AND, улучшая решения планировщика запросов для пересекающихся полнотекстовых условий. - 🪲 v17.6.4 Issue #4274 Исправлена ошибка
indextool --check, не открывающего файлыhitless_wordsдисковых чанков, путём разрешения их путей относительно директории индекса. - 🪲 v17.6.3 Issue #4284 Исправлены сбои на узлах-репликах при вставке в кластеризованные таблицы с авто-эмбеддингами путём сохранения исходного текста, необходимого для генерации эмбеддингов во время реплицируемых коммитов.
- 🪲 v17.6.2 Issue #4257 Исправлено недопустимое чтение, обнаруженное Valgrind при выполнении подготовленных выражений, путём обеспечения корректного завершения буфера ввода парсера.
- 🪲 v17.6.1 Issue #4207 Добавлено исправление регрессии и покрытие тестами для гонки сохранения дискового чанка RT, которая могла приводить к потере удалений документов и появлению дублирующихся строк после слияний.
- 🪲 v17.5.10 Issue #4207 Обновлён MCL до версии 10.2.2, исправлены сбои при выполнении поисков во время вставки данных в таблицы с локальными моделями эмбеддингов путём добавления защиты от параллелизма при использовании локальных моделей.
- 🪲 v17.5.9 PR #4247 Исправлена гонка во время сохранения дискового чанка RT, которая могла приводить к потере удалений документов и появлению дублирующихся строк после слияний или сохранений.
- 🪲 v17.5.8 PR #4241 Исправлена некорректная оценка атрибутов после лимита в присоединённых таблицах, включая запросы
LEFT JOINпосле сброса RAM-чанков на диск. - 🪲 v17.5.7 PR #4239 Уточнены определения времени запроса и реального времени в документации по логированию и статусу.
- 🪲 v17.5.6 PR #4245 Исправлены глобальные метрики
search_stats_ms_*, которые завышали время поиска из-за двойного учёта локального времени выполнения; теперь эти статистики соответствуют фактическому времени выполнения запроса. - 🪲 v17.5.5 Issue #858 Исправлены функция
HIGHLIGHT()и генерация сниппетов для текста CJK, добавляющие ненужные пробелы между словами; выделенные отрывки теперь сохраняют исходное расстояние между словами вместо токенизированного. - 🪲 v17.5.4 Issue #1166 Исправлен сбой при INSERT после
TRUNCATE TABLE ... WITH RECONFIGUREдля RT-таблиц сindex_field_lengths=1, особенно когда поля и строковые атрибуты смешаны; атрибуты длины поля теперь корректно настраиваются во время переконфигурации. - 🪲 v17.5.3 Исправлено повреждённое содержимое документации Wordforms в руководстве.
- 🪲 v17.5.2 Issue #3213 Исправлены JOIN-запросы с фильтрацией по выражениям, построенным из псевдонимов колонок присоединённой таблицы, например
SELECT t2.i al, (al*0.1) pct ... WHERE pct > 0, которые могли завершаться ошибкойincoming-schema expression missing evaluator; теперь эти фильтры корректно вычисляются после соединения.
Выпущена: 7 февраля 2026 г.
Если вы следуете официальному руководству по установке, вам не нужно об этом беспокоиться.
❤️ Мы хотели бы поблагодарить @pakud за их работу над PR #4075.
- ⚠️ v17.0.0 Issue #4120 MCL 10.0.0: Добавлена поддержка
DROP CACHE. Это обновляет интерфейс между демоном и MCL. Более старые версии Manticore Search не поддерживают новую MCL. - ⚠️ v16.0.0 Issue #4019 JSON-ответы на перколяционные запросы теперь возвращают
_idи_scoreсовпадений как числа вместо строк, соответствуя обычному поиску; это критическое изменение для клиентов, которые полагались на строковый тип для этих полей.
- 🆕 v17.5.0 PR #130 MCL обновлена до версии 10.2.0: Исправлена поддержка модели QWEN и добавлена поддержка дополнительных моделей.
- 🆕 v17.3.0 PR #4186 Executor обновлен до версии 1.4.0, включая обновленную версию PHP и расширение llm-php-ext.
- 🆕 v17.2.0 PR #4195 Обновлена MCL до версии 10.1.0; Добавлена поддержка локальных моделей эмбеддингов Qwen.
- 🆕 v17.1.0 Issue #3826 Экземпляры морфологии Jieba теперь используются совместно между таблицами с одинаковой конфигурацией (режим, флаг HMM, путь к пользовательскому словарю), что значительно снижает использование памяти, когда многие таблицы используют Jieba (например, многие пустые таблицы больше не вызывают использование ~20 ГБ).
- 🆕 v17.0.7 Issue #2046 В режиме RT стоп-слова, словоформы, исключения и hitless_words теперь можно задавать непосредственно в
CREATE TABLE(значения, разделенные точкой с запятой; словоформы/исключения используют>или=>для пар, с экранированием через\), что позволяет создавать таблицы без внешних файлов;SHOW CREATE TABLEвозвращает эти встроенные значения. - 🆕 v16.3.0 Поиск KNN теперь по умолчанию использует oversampling=3 и rescore=1, а также поддерживает опускание k, так что лимит запроса используется в качестве эффективного k; это уменьшает ненужное передискретизирование и улучшает поведение при использовании
SELECT *с KNN на колоночных таблицах. - 🆕 v16.2.0 PR #4088 Добавлен флаг
--quiet(-q) для searchd, чтобы подавлять вывод при запуске (баннер и сообщения о предварительном кэшировании), выводя только ошибки; полезно при запуске и остановке searchd в цикле или из скриптов. - 🆕 v16.0.1 Issue #3336 HTTP-соединения теперь по умолчанию являются постоянными при использовании HTTP/1.1: клиентам больше не нужно явно отправлять заголовок
Keep-Alive, что снижает случайные сбои соединений в API-клиентах (например, PHP, Go). Чтобы закрыть соединение, клиент отправляетConnection: close. HTTP/1.0 по-прежнему требуетConnection: keep-aliveдля постоянства соединения.
- 🪲 v17.5.1 Issue #3498 Исправлены результаты JOIN, возвращающие пустые или дублированные значения, когда столбец был одновременно строковым атрибутом и хранимым полем; теперь значение атрибута возвращается корректно.
- 🪲 v17.4.2 Issue #2559 Исправлены JOIN по строковым атрибутам JSON (например,
j.s), которые не возвращали совпадений; теперь они работают как JOIN по обычным строковым атрибутам. - 🪲 v17.4.1 Исправлена невычисляемость хранимых атрибутов в финальной стадии при установленном cutoff.
- 🪲 v17.2.10 Issue #425 Автоматическое создание таблиц (автосхема) теперь работает для
REPLACE INTO, а также дляINSERT INTO, поэтому таблицы создаются по требованию при их отсутствии. - 🪲 v17.2.9 Issue #3226 Исправлены некорректные результаты
GROUP BYдля колоночных MVA с несколькими столбцамиGROUP BY, отклоняя такие запросы с той же ошибкой, что и для построчных ("MVA values can't be used in multiple group-by"). - 🪲 v17.2.7 Issue #1737 Исправлена функция
highlight()сhtml_strip_mode=strip, которая портила содержимое, декодируя сущности и изменяя теги; исходная форма сущностей теперь сохраняется в выделенном выводе. - 🪲 v17.2.6 Issue #3203 Исправлен сбой
ALTER TABLE REBUILD SECONDARYс ошибкойfailed to rename … .tmp.spjidx, когда таблица имела несколько дисковых чанков. - 🪲 v17.2.5 Issue #3226 Исправлены некорректные результаты GROUP BY для колоночных MVA с несколькими столбцами GROUP BY, отклоняя такие запросы с той же ошибкой, что и для построчных ("MVA values can't be used in multiple group-by").
- 🪲 v17.2.4 Issue #4148 Исправлены распределенные запросы, возвращающие хранимые поля из неправильного локального индекса, когда таблицы агентов содержат дублирующиеся идентификаторы документов; хранимые поля теперь следуют порядку индексов, и для дубликатов используется первый совпадающий индекс.
- 🪲 v17.2.3 Issue #4176 Исправлено нарушение работы таблиц, использующих внешние стоп-слова, словоформы или исключения, при переименовании таблицы:
ATTACH TABLEтеперь мигрирует эти файлы в новый чанковый формат и обновляет заголовки дисковых чанков, поэтому послеALTER TABLE RENAMEдемон больше не сообщает об отсутствующих внешних файлах при перезапуске. - 🪲 v17.2.2 Issue #1065 Добавлена опция поиска expand_blended, чтобы токенизация запроса применяла правила смешения таблицы и расширяла смешанные варианты (например, "well-being" → "well-being" | "wellbeing" | "well" "being"), позволяя одному запросу находить документы, проиндексированные в любой из этих форм.
- 🪲 v17.1.3 Issue #1618 Обновлен Buddy до версии 3.40.7. Поддержка использования Manticore с HikariCP и JPA/MyBatis (Spring Boot) предоставляется через Manticore Buddy, который реализует необходимое поведение протокола MySQL.
- 🪲 v17.1.2 Issue #4128 Исправлен MATCH с OR для одной и той же фразы в разных полях (например,
(@name ="^New York$") | (@ascii_name ="^New York$")), который возвращал совпадения из других полей; булево упрощение больше не снимает ограничения полей в этом случае. - 🪲 v17.1.1 Issue #4131 Исправлен сбой
ALTER TABLEс настройками уровня таблицы (например,html_strip='1') на таблицах с авто-эмбеддингами с ошибкой "knn_dims can't be used together with model_name"; сериализация теперь опускает knn_dims, когда установлен model_name. - 🪲 v17.0.12 PR #4188 Исправлена некорректная оценка фильтра и дерева фильтров в объединенных запросах.
- 🪲 v17.0.11 Issue #3661 Исправлены периодические сбои при использовании колоночных атрибутов MVA64 (например, во время слияния/оптимизации или при выборе хранимых/колоночных атрибутов), путем исправления обработки данных колоночных MVA64 в docstore и blob-pool.
- 🪲 v17.0.10 Issue #3944
HIGHLIGHTи генерация сниппетов теперь поддерживаютREGEXв строке запроса, поэтому совпаденияREGEXкорректно выделяются, когда тот же запросREGEXиспользуется вMATCHиHIGHLIGHT. - 🪲 v17.0.8 Issue #4159 Исправлена функция
HISTOGRAM(), возвращавшая некорректные значения (например, ноль), когда первый аргумент является выражением с плавающей точкой, таким какprice*100; гистограмма теперь использует бакетирование с плавающей точкой для аргументов типа float, поэтому результаты выражений группируются правильно. - 🪲 v17.0.5 Issue #4148 Исправлены распределенные запросы, возвращавшие неправильное хранимое поле, когда агент имеет несколько локальных индексов с дублирующимися идентификаторами документов; хранимое поле теперь берется из совпадающего индекса в соответствии с порядком индексов (первое совпадение побеждает), и поведение задокументировано.
- 🪲 v17.0.3 Issue #4115
HIGHLIGHT()и генерация сниппетов теперь поддерживают явный оператор OR (|) внутри выражений в кавычках, используя то же преобразование запроса, что и поиск. - 🪲 v17.0.1 Issue #4118 В простом режиме KNN-атрибуты с model_name (авто-эмбеддинги) больше не требуют явного свойства dims; таблица обслуживается с использованием размерностей модели.
- 🪲 v16.3.4 PR #4121 Улучшена производительность для запросов, использующих хранимые колоночные атрибуты (ранний выход и кэшированные проверки зависимостей атрибутов, снижены накладные расходы читателя docstore), и добавлена команда
DROP CACHEдля очистки кэшей запросов, docstore, skip и вторичных индексов. - 🪲 v16.3.3 Issue #3928 Исправлена постраничная навигация scroll, когда
ORDER BYвключал строковый столбец: токен scroll теперь применяется корректно и возвращает следующую страницу вместо повторения первой. - 🪲 v16.3.2 Issue #4040 Исправлена ошибка сегментации во время запуска, когда измерение стека не удавалось в некоторых средах (например, AlmaLinux 10, Docker/VM): мокирование стека теперь сравнивает дельту кадра с оставшимся размером стека вместо использования суммы, которая могла переполниться или быть неверной, поэтому измерение больше не переходит в недопустимое состояние, и searchd больше не падает после предупреждения "Something wrong measuring stack".
- 🪲 v16.3.1 Issue #4062 JOIN-запросы теперь последовательно сообщают об ошибке, когда атрибуты левой таблицы имеют префикс в фильтрах
WHERE; ранее в некоторых случаях (например, когда правая таблица не имела полнотекстового поля) запрос выполнялся без ошибки и возвращал пустой набор результатов. - 🪲 v16.2.6 Issue #1827 Зарезервированные ключевые слова в обратных кавычках (например, order, year, facet) теперь принимаются в качестве имен атрибутов и столбцов в
CREATE TABLEи в выражениях, поэтому таблицы и запросы могут использовать зарезервированные слова в качестве идентификаторов при экранировании обратными кавычками. - 🪲 v16.2.5 Issue #4107 Исправлен парсер SphinxQL, чтобы выражения, заканчивающиеся именем столбца в обратных кавычках, разбирались корректно вместо вызова синтаксической ошибки.
- 🪲 v16.2.4 Issue #4106
SHOW CREATE TABLEтеперь выводит имена столбцов, которые являются зарезервированными или специальными (например, knn), в обратных кавычках, чтобыCREATE TABLE ... LIKEи повторное выполнение показанного DDL работали, когда исходная таблица имеет такие столбцы. - 🪲 v16.2.3 Issue #3661 Исправлено количество хранимых атрибутов в docstore во время
ALTER, чтобы переименование несуществующего.spdsбольше не происходило, и сохранены существующие данные blob в пуле blob при добавлении колоночных атрибутов, чтобы ошибки "Blob offset out of bounds" и сбои запросов/слияний больше не возникали. - 🪲 v16.2.1 PR #4083 Исправлены некорректные отображения, связанные с диакритическими знаками, в таблицах символов CJK, японского и корейского языков, чтобы базовые и озвученные/диакритические формы символов нормализовались корректно для индексации и поиска.
- 🪲 v16.1.4 PR #4084 Исправлена утечка памяти состояния приемника репликации на узлах-присоединителях, когда не нужно было отправлять файлы; добавлена команда API кластера для очистки состояния recv на присоединителях, чтобы оно освобождалось, когда донор обнаруживает, что все узлы уже синхронизированы.
- 🪲 v16.1.3 Issue #615 Обновлен Buddy до версии 3.40.5. Исправлены ошибки недопустимого JSON в плагине KNN, когда строки результатов содержали поля bigint: строковые значения сериализовались без кавычек (например, строки, похожие на числа, такие как
0000000000), создавая недопустимый JSON; строковые атрибуты теперь всегда сериализуются как строки JSON в кавычках. - 🪲 v16.1.2 PR #4077 Исправлен вывод и разбор JSON для больших значений double: вывод набора результатов теперь использует резервный формат, когда значение превышает буфер по умолчанию, а целочисленные литералы, переполняющие int64, разбираются как double вместо некорректных целых чисел.
- 🪲 v16.1.1 Issue #2628 Улучшено восстановление после ошибок KNN-индекса: когда RT-индекс не может загрузить KNN-индекс, частично загруженные данные HNSW теперь очищаются, поэтому демон больше не падает при удалении дискового чанка.
- 🪲 v16.0.13 PR #4076 Добавлена опция
searchd.attr_autoconv_strict(по умолчанию 0) для управления преобразованием строк в числа приINSERT/REPLACEв RT-таблицы: при включении недопустимые значения (пустая строка, нечисловые, завершающие символы, переполнение) возвращают ошибки вместо тихого преобразования в 0. - 🪲 v16.0.12 Issue #1751 Исправлен
must_notв JSON-поиске, чтобы он вел себя как логическое НЕ (возвращая все документы, которые не соответствуют внутреннему запросу); также исправленWHERE NOT ...в SphinxQL для выражений-фильтров. - 🪲 v16.0.11 PR #2990 Обновлен Libstemmer до версии, включающей исправление ошибки греческого стеммера (
libstemmer_el) #204, предотвращая сбой сервера, который мог происходить с определенным греческим текстом при использованииmorphology='libstemmer_el'(см. issue #2888). - 🪲 v16.0.10 Вычисление хранимых атрибутов перемещено на стадию postlimit, где это возможно, что улучшает производительность.
- 🪲 v16.0.9 Issue #3905 Исправлен периодический сбой, когда ротация индекса совпадала с SIGHUP (например, перезагрузка конфигурации) на главном узле: при динамической конфигурации fork() дублировал сокеты, и epoll мог позже сообщить о fd, чьи связанные данные уже были освобождены. Сокеты теперь удаляются из списка интересов epoll с помощью EPOLL_CTL_DEL перед закрытием, предотвращая использование после освобождения в
LazyNetEvents_c::EventTick(). - 🪲 v16.0.8 Issue #3418 Обновлено требование к Buddy до версии 3.40.4, которая включает улучшенный формат журналов ошибок обработки: когда запрос завершается неудачей (например, "unknown local table(s) 'index'"), Buddy теперь записывает причину сбоя от демона вместо только "Failed to handle query" без контекста.
- 🪲 v16.0.7 Issue #2281 Устранены несоответствия в именах типов для многозначных атрибутов в перколяционных таблицах: mva и mva64 теперь принимаются как синонимы для multi и multi64 в
CREATE TABLE, поэтому любое именование может использоваться при определении таблиц (например,CREATE TABLE t (id bigint, tags mva64, ...) type='pq'). Вывод схемы (например,DESC table) продолжает использовать существующие имена типов для совместимости. - 🪲 v16.0.4 PR #4047 Обновлена версия MCL до 9.0.1. Исправлена обработка векторов с плавающей точкой KNN, когда block_size равен 1, путем отключения сжатия таблицы в этом случае (сжатие не используется для размера блока 1).
- 🪲 v16.0.3 Issue #4042 Исправлен сбой повторно присоединившегося узла, когда
ALTER CLUSTER ... ADD TABLEвыполнялся на другом узле после того, как присоединитель перезапустился и повторно присоединился. - 🪲 v15.1.5 Issue #4009 Исправлено использование кэша запросов, когда вторичный индекс был принудительно включен через подсказки; кэш теперь отключается, чтобы принудительный SI всегда учитывался.
- 🪲 v15.1.4 Issue #2591 Исправлен полнотекстовый оператор
NOTNEAR, чтобы он корректно исключал совпадения, когда правый термин появляется в пределах указанного расстояния либо до, либо после левого термина (симметричное/обратное сопоставление). Ранее NOTNEAR рассматривал правый термин только тогда, когда он появлялся после левого термина, поэтому, например,d NOTNEAR/3 aмог некорректно соответствовать документу, содержащему "a b c d". NEAR теперь также возвращает ошибку, когда расстояние равно 0. - 🪲 v15.1.3 Issue #507 Обновлен Buddy до версии 3.40.3. Исправлены многозапросные запросы, использующие нечеткий поиск (
OPTION fuzzy=1), за которыми следует show meta на/cliи/sql?mode=raw. - 🪲 v15.1.1 Issue #4009 Исправлены некорректные результаты с подсказкой SecondaryIndex и кэшем запросов, сделав SI и кэш запросов взаимоисключающими для каждого запроса и добавив предупреждение, когда принудительный SI игнорируется из-за попадания в кэш.
Выпущено: 7 декабря 2025
Если вы следуете официальному руководству по установке, вам не о чем беспокоиться.
- ⚠️ v15.0.0 PR #4003 Обновлено требование к MCL до версии 9.0.0, добавлено хранение с плавающей точкой без сжатия для векторов, изменение размера блока для KNN-векторов и небуферизованное чтение. Это обновление изменяет формат данных. Старые версии MCL не смогут читать новые данные, но новая версия может без проблем читать ваши существующие колоннарные таблицы.
- 🆕 v15.1.0 PR #3990 Улучшены записи логов сброса чанков на диск с разбивкой общего времени на более ясные части.
- 🆕 v14.7.0 Issue #3860 Обновлено требование к Buddy до версии 3.40.1, включающее улучшение автодополнения: нормализованы символы-разделители биграмм в пробелы и отфильтрованы дублирующиеся или некорректные сочетания предложений для повышения их качества. Также исправлены ошибки invalid JSON в представлениях Kafka и исправлено автодополнение — сортировка сочетаний больше не вызывает ошибок при отсутствии некоторых ключей в score map.
- 🆕 v14.6.0 Issue #615 Обновлено требование к Manticore Buddy до версии 3.39.1, исправляющей ошибки invalid JSON в плагине KNN и позволяющей обработчикам Buddy переопределять HTTP
Content-Type, так что/metricsтеперь возвращает текстовый формат Prometheus (text/plain; version=0.0.4) вместо JSON, устраняя ошибки при сборе метрик. - 🆕 v14.4.0 PR #3942 Обновлено требование к Manticore Buddy до 3.38.0, отфильтрованы предложения с нулевым количеством документов, улучшена обработка строковых ключей с Ds\Map, изменён формат отчёта об использовании памяти в Buddy с килобайтов на байты для большей точности, а также повышена производительность, стабильность и поддерживаемость.
- 🆕 v14.5.0 Issue #3329 Удаление лишних пробелов и символов новой строки в JSON-пейлоадах при логировании запросов — пропуск начальных и конечных пробелов, чтобы избежать записи некорректного JSON.
- 🆕 v14.3.0 PR #3932 Улучшена обработка
LOCK TABLES/UNLOCK TABLES: блокировки на запись теперь возвращают предупреждения вместо ошибок, блокировки на чтение корректно отображаются вSHOW LOCKS, логика блокировок стала более последовательной. - 🆕 v14.2.0 Issue #3891 Добавлена поддержка произвольных выражений фильтрации в
JOIN ON(не только проверок на равенство), позволяющая делать запросы вида... ON t1.id = t2.t1_id AND t2.value = 5.
- 🪲 v15.0.6 Issue #3601 Исправлена регрессия, при которой нативная служба Windows не запускалась при установке с пользовательским путем конфигурации.
- 🪲 v15.0.5 Issue #3864 Исправлена обработка "объединённых полей" в источниках на основе SQL так, чтобы "маркер конца" корректно устанавливался при переборе объединённых результатов.
- 🪲 v15.0.4 Issue #4004 Исправлена регрессия, при которой HTTP-ответы
/sqlот демона некорректно использовали заголовокContent-Type: text/htmlвместоapplication/json. - 🪲 v15.0.3 Issue #2727 Исправлена проблема, когда группировка через
GROUP BY/FACETпо атрибутам, созданным с помощью JSON-to-attribute mapping, не работала. - 🪲 v15.0.2 Issue #3962 Обновлено требование Buddy до версии 3.40.2, которая добавляет поддержку нечеткого поиска для
/sqlи включает другие исправления для нечеткого поиска. - 🪲 v15.0.1 PR #3922 Обновлена документация и тесты, связанные с поддержкой Logstash 9.2.
- 🪲 v14.7.6 PR #4002 Исправлено поведение KNN при оверсэмплинге: больше не вычисляется повторно оценённое расстояние KNN, если переоценка не запрашивается, и передаются подсказки по доступу к float-векторам в слой колонного хранения.
- 🪲 v14.7.5 PR #3999 Исправлена модель “test_298” для устранения ошибки в тесте, связанной с KNN.
- 🪲 v14.7.4 Issue #3977 Тесты на Windows иногда создавали дампы с расширением .mdmp — исправлено, теперь "ubertests" не оставляют minidumps после завершения.
- 🪲 v14.7.3 Issue #3832 Исправлена ошибка, при которой мульти-запросы через
/cli_json, содержащие точку с запятой (например, объединение SQL-запросов), не выполнялись — теперь точки с запятой не заменяются на нулевые символы перед обработкой. - 🪲 v14.7.2 Issue #1613 Документирована внутренняя 32-битная маска, используемая при подсчёте ранжирующих факторов для операторов Phrase/Proximity/NEAR, и объяснено, как она может недосчитывать термины после 31-го ключевого слова.
- 🪲 v14.7.1 PR #3992 Исправлены отсутствующие сообщения об ошибках для HTTP-запросов UPDATE и DELETE по распределённым таблицам, обрабатываемым агентами, теперь клиенты корректно получают ошибки в случае неудачи операций.
- 🪲 v14.6.4 Issue #3478 Улучшена проверка обновлений: теперь проверяется, что обновляемые атрибуты не конфликтуют с полями полнотекстового поиска; обновления отклоняются при попытке модифицировать полнотекстовые поля.
- 🪲 v14.6.3 Issue #2352 Исправлена внутренняя ошибка при использовании распределённых таблиц с
persistent_connections_limit. - 🪲 v14.6.2 Issue #3757 Исправлена ошибка, при которой счётчики состояния таблиц с суффиксом "_sec" (например,
query_time_1min) фактически показывали миллисекунды вместо секунд. - 🪲 v14.6.1 Issue #3979 Исправлена ошибка, при которой статистика времени поиска
SHOW INDEX <name> STATUS(search_statsms*) не совпадала со значениями из логов запросов; теперь отображаются реальные зарегистрированные времена. - 🪲 v14.5.8 Issue #3517 Обновлена обработка HTTP-заголовков, чтобы интеграции Buddy могли определять или переопределять заголовки, вместо того чтобы всегда навязывать
application/json. - 🪲 v14.5.7 Исправлен тест 226 для обеспечения стабильного порядка результатов, а также исправлена модель GTest для обработки смешанных JSON-массивов.
- 🪲 v14.5.6 Исправлена сборка Windows путём коррекции несоответствия типов в
binlog.cpp, теперьDoSaveMeta()корректно компилируется для Windows. - 🪲 v14.5.5 Issue #805 Issue #807 Issue #3924 Исправлено неконсистентное поведение фасетирования по JSON-атрибутам: использование псевдонимов JSON-массива в FACET теперь ведёт себя так же, как фасетирование по самому массиву.
- 🪲 v14.5.4 Issue #3927 Исправлен сбой в поиске KNN векторов путём пропуска поиска по пустым индексам HNSW.
- 🪲 v14.5.2 Issue #3669 Исправлен разбор
MATCH(), теперь пустые группы, например(), не вызывают ошибку (например, запросы видаcamera()теперь работают корректно). - 🪲 v14.5.1 PR #3961 Обновлена документация по резервному копированию в режиме репликации mysqldump: объяснено использование
--skip-lock-tablesпри дампе реплицируемых таблиц и исправлены несколько повреждённых ссылок в руководстве. - 🪲 v14.3.2 Issue #2772 Исправлена ошибка, когда некоторые команды, выполненные через MySQL клиент 9, вызывали ошибку "unexpected $undefined near '$$'" в логе запросов.
- 🪲 v14.3.1 PR #3934 Обновлено требование Manticore Buddy с 3.37.0 до 3.37.2, убраны избыточные проверки
LOCK/UNLOCK TABLES(теперь это обрабатывает демон), а также исправлен разбор автодополнения, чтобы запросы с экранированными кавычками (например,\"или\') обрабатывались корректно, без ошибок. - 🪲 v14.2.1 Issue #3602 Исправлен сбой при использовании
knn_dist()в пользовательском ранжировщике с запросами KNN+MATCH; теперь такие запросы возвращают понятную ошибку вместо сбоя. - 🪲 v14.1.1 docs: исправлены мелкие проблемы с переводом.
Выпущено: 7 ноября 2025 г.
❤️ Мы хотим искренне поблагодарить @ricardopintottrdata за их работу над PR #3792 и PR #3828 — решение проблем с подсчетами HAVING total и ошибкой filter with empty name — а также @jdelStrother за их вклад с PR #3819, который улучшает обработку ParseCJKSegmentation, когда поддержка Jieba недоступна.
Ваши усилия помогают сделать проект сильнее — большое спасибо!
Если вы следуете официальному руководству по установке, вам не о чем беспокоиться.
Версия v14.0.0 обновляет протокол репликации. Если вы работаете с кластером репликации, вам нужно:
- Сначала корректно остановить все ваши узлы
- Затем запустить последний остановленный узел с параметром
--new-cluster, используя инструментmanticore_new_clusterв Linux. - Подробнее о перезапуске кластера.
- 🆕 v14.1.0 Issue #3047 Добавлена поддержка операторов
LOCK TABLES, генерируемых mysqldump, что улучшает безопасность логических бэкапов. - ⚠️ v14.0.0 PR #3896 Добавлен индикатор прогресса для донорских и присоединяющихся узлов в репликации SST, отображаемый в SHOW STATUS.
- 🆕 v13.16.0 PR #3894 Обновлен buddy с версии 3.36.1 до 3.37.0, добавляющей опцию "quorum".
- 🆕 v13.15.0 PR #3842 Опция force_bigrams для плагинов fuzzy и autocomplete.
- 🪲 Issue #4299 Добавлено тестирование для Grafana версии 12.4.
- 🪲 Issue #3994 Добавлено тестирование версии Grafana 12.3.
- 🪲 v14.0.1 Issue #3844 Исправлен сбой, вызванный использованием
max(ft field). - 🪲 v13.15.13 PR #3828 Исправлена ошибка при использовании пустого имени фильтра.
- 🪲 v13.15.12 PR #3873 Обновлен buddy с 3.36.0 до 3.36.1 с проверкой режима RT в плагине EmulateElastic.
- 🪲 v13.15.11 PR #3857 Добавлено тестирование версии Filebeat 9.2.
- 🪲 v13.15.10 PR #3880 Протестирован автоматический перевод документации после исправлений.
- 🪲 v13.15.9 Issue #3783 Исправлена проблема, препятствующая нативной компиляции FreeBSD.
- 🪲 v13.15.8 Исправлены переводы документации.
- 🪲 v13.15.7 PR #3868 Обновлен executor с 1.3.5 до 1.3.6, добавлена поддержка расширения iconv.
- 🪲 v13.15.6 Исправлена проблема сборки фуззера, связанная с issue 3817.
- 🪲 v13.15.5 Issue #3644 Исправлен сбой, вызванный определёнными полнотекстовыми запросами.
- 🪲 v13.15.4 Issue #3686 Исправлена проблема, из-за которой полнотекстовый запрос
"(abc|def)"не работал как ожидалось. - 🪲 v13.15.3 Issue #3428 Добавлена возможность получить общее количество результатов для запросов с использованием
HAVING. - 🪲 v13.15.2 Issue #3817 Добавлена опция searchd.expansion_phrase_warning.
- 🪲 v13.15.1 PR #3848 Исправлена генерация ключей транзакций репликации и обработка конфликтующих транзакций.
- 🪲 v13.14.0 Issue #3806 Исправлен
CALL SUGGEST, не совпадавший с триграммами. - 🪲 v13.13.8 PR #3839 Обновлен buddy с 3.35.4 до 3.35.5 для корректировки регулярного выражения для сопоставления соединений в SQL-запросах.
- 🪲 v13.13.7 Issue #3815 Обновлен buddy с 3.35.3 до 3.35.4 для исправления проблемы с отрицательными ID в REPLACE.
- 🪲 v13.13.6 PR #3830 Обновлен buddy с 3.35.1 до 3.35.3.
- 🪲 v13.13.5 PR #3823 Добавлен интеграционный тест для Grafana.
- 🪲 v13.13.4 PR #3819 Исправлен
ParseCJKSegmentationпри отсутствии поддержки Jieba. - 🪲 v13.13.3 PR #3808 Исправлена обработка ошибок при использовании фильтров в JSON-запросах с правым соединением.
- 🪲 v13.13.2 PR #3789 Проверены параметры KNN.
- 🪲 v13.13.1 Issue #3800 Исправлены проблемы сборки при компиляции без поддержки cjk/jieba.
Выпущено: 7 октября 2025
Если вы следуете официальному руководству по установке, вам не о чем беспокоиться.
Поскольку конфигурационный файл был обновлен, во время обновления на Linux вы можете увидеть предупреждение с вопросом, сохранить ли вашу версию или использовать новую из пакета. Если у вас есть пользовательская (не по умолчанию) конфигурация, рекомендуется сохранить вашу версию и обновить путь pid_file на /run/manticore/searchd.pid. Однако, даже если вы не измените путь, все должно работать нормально.
- 🆕 v13.13.0 Добавлена поддержка MCL 8.1.0 с SI блок-кешем.
- 🆕 v13.12.0 Реализована опция secondary_index_block_cache, обновлено API вторичного индекса и встроены методы доступа к сортировке.
- 🪲 v13.11.8 Проблема #3791 Исправлено состояние гонки между проверкой и вызовом сработавшего таймера.
- 🪲 v13.11.7 Проблема #1045 Исправлено предупреждение systemctl на RHEL 8 при обновлении systemd путем замены устаревшего пути
/var/run/manticoreна правильный/run/manticoreв конфигурации. Поскольку конфигурационный файл был обновлен, во время обновления вы можете увидеть предупреждение с вопросом, сохранить ли вашу версию или использовать новую из пакета. Если у вас есть пользовательская (не по умолчанию) конфигурация, рекомендуется сохранить вашу версию и обновить путьpid_fileна/run/manticore/searchd.pid. - 🪲 v13.11.6 PR #3766 Добавлена поддержка версии MCL 8.0.6.
- 🪲 v13.11.5 PR #3767 Улучшены переводы документации на китайский язык и обновлены подмодули.
- 🪲 v13.11.4 PR #3765 Исправлена обработка присвоенных псевдонимов атрибутов соединения.
- 🪲 v13.11.3 PR #3763 Исправлен сбой, который мог возникать при пакетных соединениях по строковым атрибутам, а также устранена проблема, при которой фильтры иногда не работали с LEFT JOIN.
- 🪲 v13.11.2 Проблема #3065 Исправлен сбой при вставке данных в колонковую таблицу с включенным параметром index_field_lengths.
- 🪲 v13.11.1 Проблема #3751 Исправлен сбой, возникающий при удалении документа с включёнными встраиваниями.
Выпущена: 13 сентября 2025
- 🪲 v13.11.1 Проблема #3751 Исправлен сбой, возникающий при удалении документа с включёнными встраиваниями.
Выпущена: 13 сентября 2025
Главной особенностью этого релиза является Auto Embeddings — новая функция, которая делает семантический поиск таким же простым, как SQL. Не требуются внешние сервисы или сложные пайплайны: просто вставьте текст и производите поиск на естественном языке.
- Автоматическое создание эмбеддингов напрямую из вашего текста
- Запросы на естественном языке, которые понимают смысл, а не только ключевые слова
- Поддержка нескольких моделей (OpenAI, Hugging Face, Voyage, Jina)
- Бесшовная интеграция с SQL и JSON API
Если вы следуете официальному руководству по установке, вам не о чем беспокоиться.
Рекомендуемая версия MCL: 8.0.1 Рекомендуемая версия Buddy: 3.34.2
- 🆕 v13.11.0 PR #3746 Добавлена поддержка "query" в JSON-запросах для генерации эмбеддингов.
- 🆕 v13.10.0 Проблема #3709 RPM-пакет manticore-server больше не владеет
/run. - 🆕 v13.9.0 PR #3716 Добавлена поддержка
boolean_simplifyв конфигурации. - 🆕 v13.8.0 Проблема #3253 Установлена конфигурация sysctl для повышения vm.max_map_count для больших наборов данных.
- 🆕 v13.7.0 PR #3681 Добавлена поддержка
alter table <table> modify column <column> api_key=<key>.
- 🪲 v13.10.5 PR #3737 Опция scroll теперь корректно возвращает все документы с большими 64-битными ID.
- 🪲 v13.10.4 PR #3736 Исправлен сбой при использовании KNN с фильтр-деревом.
- 🪲 v13.10.3 Issue #3520 В эндпоинте
/sqlбольше нельзя использовать команду SHOW VERSION. - 🪲 v13.10.2 PR #3637 Обновлен скрипт установщика для Windows.
- 🪲 v13.10.1 Исправлено определение локального часового пояса на Linux.
- 🪲 v13.9.2 PR #3726 Дублирующиеся ID в колонковом режиме теперь корректно вызывают ошибку.
- 🪲 v13.9.1 PR #3333 Руководство теперь автоматически переводится.
- 🪲 v13.8.6 PR #3715 Исправлена ошибка генерации эмбеддингов, когда все документы в пакете были пропущены.
- 🪲 v13.8.5 PR #3711 Добавлены модели эмбеддингов Jina и Voyage, а также другие автоматические изменения, связанные с эмбеддингами.
- 🪲 v13.8.4 PR #3710 Исправлен сбой в объединённых запросах с несколькими фасетами.
- 🪲 v13.8.3 Исправлена проблема, когда коммиты удаления/обновления в транзакции с несколькими операторами в _bulk эндпоинте не учитывались как ошибки.
- 🪲 v13.8.2 PR #3705 Исправлен сбой при объединении по неколонковым строковым атрибутам, улучшено отображение ошибок.
- 🪲 v13.8.1 PR #3704 Исправлен сбой в эмбеддингах запросов при отсутствии указанной модели; добавлена строка эмбеддингов в коммуникацию master-agent; добавлены тесты.
- 🪲 v13.7.2 PR #Buddy#589 Убрана стандартная уловка с IDF для нечеткого поиска.
- 🪲 v13.7.1 Issue #3454 Исправлено некорректное декодирование scroll с большими 64-битными ID.
- 🪲 v13.6.9 Issue #3674 Исправлена проблема с драйвером JDBC+MySQL и пулом соединений при установке transaction_read_only.
- 🪲 v13.6.8 PR #3676 Исправлен сбой на пустом наборе результатов, возвращаемом моделью эмбеддингов.
Выпущена: 8 августа 2025 года
Рекомендуемая версия MCL: 8.0.1
Рекомендуемая версия Buddy: 3.34.2
Если вы следуете официальному руководству по установке, беспокоиться не о чем.
- 🆕 v13.6.0 Issue #2226 Поддержка явного оператора '|' (ИЛИ) в PHRASE, PROXIMITY и QUORUM.
- 🆕 v13.5.0 PR #3591 Автоматическая генерация эмбеддингов в запросах (Работа в процессе, пока не готово для продакшена).
- 🆕 v13.4.0 PR #3585 Исправлена логика предпочтения количества потоков buddy из конфигурации buddy_path, если указано, вместо использования значения демона.
- 🆕 v13.3.0 PR #3577 Поддержка join с локальными распределёнными таблицами.
- 🆕 #3647 Добавлена поддержка Debian 13 "Trixie"
- 🪲 v13.6.7 Issue #3524 Исправлена проблема с сохранением сгенерированных эмбеддингов в построчном хранении.
- 🪲 v13.6.6 Issue #3563 Исправлены ошибки в Sequel Ace и других интеграциях, возникавшие из-за ошибок "unknown sysvar".
- 🪲 v13.6.5 Issue #3467 Исправлены ошибки в DBeaver и других интеграциях, возникавшие из-за ошибок "unknown sysvar".
- 🪲 v13.6.4 Issue #3524 Исправлена проблема с конкатенацией эмбеддингов из нескольких полей; также исправлена генерация эмбеддингов из запросов.
- 🪲 v13.6.3 Issue #3641 Исправлен баг в версии 13.6.0, при котором фраза теряла все ключевые слова в скобках, кроме первого.
- 🪲 v13.6.2 Исправлена утечка памяти в transform_phrase.
- 🪲 v13.6.1 Исправлена утечка памяти в версии 13.6.0.
- 🪲 v13.5.2 Issue #3651 Исправлены дополнительные проблемы, связанные с фузз-тестированием полнотекстового поиска.
- 🪲 v13.5.1 Issue #3560 Исправлена ситуация, когда OPTIMIZE TABLE мог зависать бесконечно при работе с данными KNN.
- 🪲 v13.4.2 Issue #2544 Исправлена проблема, при которой добавление столбца float_vector могло привести к повреждению индексов.
- 🪲 v13.4.1 Issue #3651 Добавлено фузз-тестирование полнотекстового парсинга и исправлены несколько обнаруженных в ходе тестирования проблем.
- 🪲 v13.3.1 Issue #3583 Исправлен сбой при использовании сложных булевых фильтров с подсветкой.
- 🪲 v13.2.7 Issue #3481 Исправлен сбой при использовании HTTP-обновления, распределённой таблицы и неправильного кластера репликации одновременно.
- 🪲 v13.2.6 PR #3567 Обновлена зависимость manticore-backup до версии 1.9.6.
- 🪲 v13.2.5 PR #3565 Исправлена настройка CI для улучшения совместимости с Docker-образами.
- 🪲 v13.2.4 Исправлена обработка длинных токенов. Некоторые специальные токены (например, шаблоны регулярных выражений) могли создавать слишком длинные слова, теперь они укорачиваются перед использованием.
Выпущено: 8 июля 2025
- ⚠️ PR #3586 Снята поддержка Debian 10 (Buster). Debian 10 достиг конца срока поддержки 30 июня 2024 года. Пользователям рекомендуется обновиться до Debian 11 (Bullseye) или Debian 12 (Bookworm).
- ⚠️ v13.0.0 Обновлено API библиотеки KNN для поддержки пустых значений float_vector. Это обновление не меняет формат данных, но повышает версию API Manticore Search / MCL.
- ⚠️ v12.0.0 PR #3516 Исправлен баг с неправильными ID исходных и целевых строк при обучении и построении KNN индекса. Это обновление не меняет формат данных, но повышает версию API Manticore Search / MCL.
- ⚠️ v11.0.0 Добавлена поддержка новых функций поиска по векторам KNN, таких как квантование, рескоринг и оверсэмплинг. Эта версия изменяет формат данных KNN и синтаксис SQL KNN_DIST(). Новая версия может читать старые данные, но старые версии не смогут читать новый формат.
- 🆕 v13.2.0 PR #3549 Исправлена проблема с
@@collation_database, вызывавшая несовместимость с некоторыми версиями mysqldump - 🆕 v13.1.0 Issue #3489 Исправлена ошибка в Fuzzy Search, препятствовавшая парсингу некоторых SQL-запросов
- 🆕 v12.1.0 Issue #3426 Добавлена поддержка операционных систем RHEL 10
- 🆕 v11.1.0 Добавлена поддержка пустых векторов с плавающей точкой в KNN поиске
- 🆕 v10.2.0 Issue #3252 log_level теперь также регулирует уровень логирования Buddy
- 🪲 v13.2.3 PR #3556 Исправлен парсинг опции "oversampling" в JSON-запросах
- 🪲 v13.2.2 Исправлено логирование крашей в Linux и FreeBSD путём удаления использования Boost stacktrace
- 🪲 v13.2.1 Issue #3298 Исправлено логирование крашей при запуске внутри контейнера
- 🪲 v12.0.2 Повышена точность статистики по таблицам за счёт учёта микросекунд
- 🪲 v12.0.1 PR #3522 Исправлен краш при фасетировании по MVA в объединённом запросе
- 🪲 v11.0.3 Issue #3502 Исправлен краш, связанный с Квантованием Векторного Поиска
- 🪲 v11.0.2 Issue #3493 Изменён
SHOW THREADSдля отображения загрузки CPU в виде целого числа - 🪲 v11.0.1 Исправлены пути для колонковых и вторичных библиотек
- 🪲 v10.2.7 Добавлена поддержка MCL 5.0.5, включая исправление имени файла библиотеки эмбеддингов
- 🪲 v10.2.6 Issue #3469 Применено дополнительное исправление, связанное с issue #3469
- 🪲 v10.2.4 Issue #3469 Исправлена проблема, при которой HTTP-запросы с Bool-запросами возвращали пустые результаты
- 🪲 v10.2.5 Изменено имя файла библиотеки эмбеддингов по умолчанию и добавлены проверки поля 'from' в KNN векторах
- 🪲 v10.2.3 PR #3464 Обновлён Buddy до версии 3.30.2, включающей PR #565 о памяти и логировании ошибок
- 🪲 v10.2.2 Issue #3470 Исправлены фильтры JSON-строк, Null-фильтры и проблемы сортировки в JOIN запросах
- 🪲 v10.2.1 Исправлена ошибка в
dist/test_kit_docker_build.sh, из-за которой отсутствовал коммит Buddy - 🪲 v10.1.4 Исправлен краш при группировке по MVA в объединённом запросе
- 🪲 v10.1.3 Issue #3434 Исправлена ошибка с фильтрацией пустых строк
- 🪲 v10.1.2 PR #3452 Обновлён Buddy до версии 3.29.7, в которой устранены Buddy #507 - ошибка с мультизапросами при fuzzy search и Buddy #561 - исправление метрики rate, необходимо для Helm Release 10.1.0
- 🪲 v10.1.1 Обновлён Buddy до версии 3.29.4, решающий #3388 - "Неопределённый ключ массива 'Field'" и Buddy #547 - layouts='ru' может не работать
Выпущена: 9 июня 2025
Эта версия представляет обновление с новыми возможностями, одним изменением, нарушающим обратную совместимость, и многочисленными улучшениями стабильности и исправлениями ошибок. Изменения направлены на расширение возможностей мониторинга, улучшение функций поиска и исправление различных критических проблем, влияющих на стабильность и производительность системы.
Начиная с версии 10.1.0, поддержка CentOS 7 больше не осуществляется. Пользователям рекомендуется перейти на поддерживаемую операционную систему.
- ⚠️ v10.0.0 Issue #540 КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: установлено значение
layouts=''по умолчанию для нечеткого поиска
- 🆕 v10.1.0 Issue #537 Добавлен встроенный экспортер Prometheus
- 🆕 v9.8.0 Issue #3409 Добавлена команда ALTER TABLE tbl REBUILD KNN
- 🆕 v9.7.0 Issue #1778 Добавлена автоматическая генерация эмбеддингов (пока не объявлено официально, так как код в основной ветке, но требует дополнительного тестирования)
- 🆕 v9.6.0 Обновлена версия API KNN для поддержки авто-эмбеддингов
- 🆕 v9.5.0 Issue #1894 Улучшено восстановление кластера: периодическое сохранение
seqnoдля более быстрого перезапуска узла после сбоя - 🆕 v9.4.0 Issue #2400 Добавлена поддержка последних версий Logstash и Beats
- 🪲 v10.0.1 Исправлена обработка форм слов: пользовательские формы теперь переопределяют автоматически сгенерированные; добавлены тестовые случаи в тест 22
- 🪲 v9.8.2 Исправление: снова обновлён deps.txt для включения исправлений упаковки в MCL, связанных с библиотекой embeddings
- 🪲 v9.8.1 Исправление: обновлён deps.txt с исправлениями упаковки для MCL и библиотеки embeddings
- 🪲 v9.7.3 Issue #3306 Исправлен сбой с сигналом 11 при индексации
- 🪲 v9.7.2 Issue #3109 Исправлена проблема, когда несуществующие
@@variablesвсегда возвращали 0 - 🪲 v9.7.1 Issue #3377 Исправлен сбой, связанный с remove_repeats()
- 🪲 v9.6.3 PR #3411 Исправление: использование динамического определения версий для телеметрических метрик
- 🪲 v9.6.2 Исправление: небольшая корректировка вывода в SHOW VERSION
- 🪲 v9.6.1 Исправление: сбой при создании таблицы с KNN-атрибутом без модели
- 🪲 v9.5.16 Issue #3342 Исправлена проблема, когда
SELECT ... FUZZY=0не всегда отключал нечёткий поиск - 🪲 v9.5.15 PR #3397 Добавлена поддержка MCL 4.2.2; исправлены ошибки с более старыми форматами хранения
- 🪲 v9.5.14 Issue #3392 Исправлена некорректная обработка строк в HTTP JSON ответах
- 🪲 v9.5.13 Issue #3356 Исправлен сбой в сложных случаях полнотекстового запроса (common-sub-term)
- 🪲 v9.5.12 Исправлена опечатка в сообщении об ошибке автосброса дискового чанка
- 🪲 v9.5.11 Issue #3195 Улучшен автосброс дисковых чанков: пропуск сохранения, если идёт оптимизация
- 🪲 v9.5.10 Issue #3313 Исправлена проверка на дубликат ID для всех дисковых чанков в RT таблице с использованием indextool
- 🪲 v9.5.9 Issue #3132 Добавлена поддержка сортировки
_randomв JSON API - 🪲 v9.5.8 Issue #3382 Исправлена проблема: нельзя было использовать uint64 ID документа через JSON HTTP API
- 🪲 v9.5.7 Issue #3385 Исправлены некорректные результаты при фильтрации по
id != value - 🪲 v9.5.6 PR #538 Исправлена критическая ошибка с нечётким сопоставлением в некоторых случаях
- 🪲 v9.5.5 Issue #3199 Исправлено декодирование пробелов в параметрах HTTP-запроса Buddy (например,
%20и+) - 🪲 v9.5.4 Issue #3133 Исправлена некорректная сортировка по
json.fieldв фасетном поиске - 🪲 v9.5.3 Issue #3091 Исправлены несоответствующие результаты поиска для разделителей в SQL и JSON API
- 🪲 v9.5.2 Issue #2819 Улучшена производительность: заменён
DELETE FROMнаTRUNCATEдля распределённых таблиц - 🪲 v9.5.1 Issue #3080 Исправлен сбой при фильтрации алиасного
geodist()с JSON-атрибутами
Выпущена: 2 мая 2025 года
Этот релиз включает множество исправлений ошибок и улучшений стабильности, лучшее отслеживание использования таблиц и улучшения управления памятью и ресурсами.
❤️ Особая благодарность @cho-m за исправление совместимости сборки с Boost 1.88.0 и @benwills за улучшение документации по stored_only_fields.
-
🪲 v9.3.2 Исправлена проблема, при которой в столбце "Show Threads" активность ЦП отображалась в виде числа с плавающей точкой вместо строки; также исправлена ошибка разбора набора результатов PyMySQL, вызванная неправильным типом данных.
-
🪲 v9.3.1 Issue #3343 Исправлено оставшиеся файлы
tmp.spidx, когда процесс оптимизации был прерван. -
🆕 v9.3.0 PR #3337 Добавлен счетчик команд по каждой таблице и подробная статистика использования таблиц.
-
🪲 v9.2.39 Issue #3236 Исправление: предотвращение повреждения таблиц путем удаления сложных обновлений чанков. Использование wait-функций внутри последовательного воркера нарушало последовательную обработку, что могло повредить таблицы. Реализован заново автосброс. Удалена внешняя очередь опроса для избежания ненужных блокировок таблиц. Добавлено условие "малой таблицы": если количество документов ниже 'малого лимита таблицы' (8192) и не используется Вторичный индекс (SI), сброс пропускается.
-
🪲 v9.2.38 Исправление: пропуск создания Вторичного индекса (SI) для фильтров, использующих
ALL/ANYна списках строк, без влияния на атрибуты JSON. -
🪲 v9.2.37 Issue #2898 Добавлена поддержка обратных кавычек для системных таблиц.
-
🪲 v9.2.36 Исправление: использование заполнителя для операций с кластерами в устаревшем коде. В парсере теперь явно разделяются поля для имен таблиц и кластеров.
-
🪲 v9.2.35 Исправление: сбой при удалении кавычек с одиночной
'. -
🪲 v9.2.34 Issue #3090 Исправление: обработка больших идентификаторов документов (ранее могла не находить их).
-
🪲 v9.2.33 Исправление: использование беззнаковых целых чисел для размеров битовых векторов.
-
🪲 v9.2.32 Исправление: снижение пикового использования памяти при слиянии. Поиск соответствия docid-коду строки теперь использует 12 байт на документ вместо 16 байт. Например: 24 ГБ ОЗУ для 2 миллиардов документов вместо 36 ГБ.
-
🪲 v9.2.31 Issue #3238 Исправление: неправильное значение
COUNT(*)в больших таблицах реального времени. -
🪲 v9.2.30 Исправление: неопределенное поведение при обнулении строковых атрибутов.
-
🪲 v9.2.29 Небольшое исправление: улучшен текст предупреждения.
-
🪲 v9.2.28 Issue #3290 Улучшение: усовершенствован
indextool --buildidf -
🪲 v9.2.27 Issue #3032 С интеграцией Kafka теперь можно создавать источник для конкретного раздела Kafka.
-
🪲 v9.2.26 Issue #3301 Исправление:
ORDER BYиWHEREпоidмогли вызвать ошибки OOM (Out Of Memory). -
🪲 v9.2.25 Issue #3171 Исправление: сбой из-за ошибки сегментации при использовании grouper с несколькими JSON-атрибутами в RT таблице с несколькими дисковыми чанками
-
🪲 v9.2.24 Issue #3246 Исправление: запросы
WHERE string ANY(...)не срабатывали после сброса RAM-чанка. -
🪲 v9.2.23 PR #518 Небольшие улучшения синтаксиса авто-шардинга.
-
🪲 v9.2.22 Issue #2763 Исправление: глобальный idf-файл не загружался при использовании
ALTER TABLE. -
🪲 v9.2.21 Исправление: глобальные idf-файлы могут быть большими. Теперь мы раньше освобождаем таблицы, чтобы избежать удержания ненужных ресурсов.
-
🪲 v9.2.20 PR #3277 Улучшение: лучшая проверка опций шардинга.
-
🪲 v9.2.19 PR #3275 Исправление: совместимость сборки с Boost 1.88.0.
-
🪲 v9.2.18 Issue #3228 Исправление: сбой при создании распределенной таблицы (ошибка с недопустимым указателем).
-
🪲 v9.2.17 PR #3272 Исправление: проблема с многострочным нечетким
FACET. -
🪲 v9.2.16 Issue #3063 Исправление: ошибка в расчете расстояния при использовании функции
GEODIST. -
🪲 v9.2.15 Issue #3027 Незначительное улучшение: поддержка формата фильтра
query_stringот Elastic.
Выпущена: 28 марта 2025
- Коммит Реализован флаг
--mockstackдля расчета требований к стеку рекурсивных операций. Новый режим--mockstackанализирует и сообщает о необходимых размерах стека для рекурсивной оценки выражений, операций сопоставления с образцом, обработки фильтров. Рассчитанные требования к стеку выводятся в консоль для целей отладки и оптимизации. - Issue #3058 Параметр boolean_simplify включен по умолчанию.
- Issue #3172 Добавлена новая опция конфигурации:
searchd.kibana_version_string, которая может быть полезна при использовании Manticore с определенными версиями Kibana или OpenSearch Dashboards, которые ожидают конкретную версию Elasticsearch. - Issue #3211 Исправлена работа CALL SUGGEST со словами из 2 символов.
- Issue #490 Улучшен нечеткий поиск: ранее он иногда не мог найти "defghi" при поиске "def ghi", если существовал другой подходящий документ.
- ⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ Issue #3165 Изменено
_idнаidв некоторых HTTP JSON ответах для единообразия. Убедитесь, что обновили ваше приложение соответствующим образом. - ⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ Issue #3186 Добавлена проверка
server_idпри присоединении к кластеру, чтобы гарантировать уникальность ID каждого узла. ОперацияJOIN CLUSTERтеперь может завершиться ошибкой с сообщением о дублировании server_id, когда присоединяющийся узел имеет тот жеserver_id, что и существующий узел в кластере. Чтобы решить эту проблему, убедитесь, что каждый узел в репликационном кластере имеет уникальный server_id. Вы можете изменить значение по умолчанию для server_id в разделе "searchd" вашего конфигурационного файла на уникальное значение перед попыткой присоединения к кластеру. Это изменение обновляет протокол репликации. Если вы используете репликационный кластер, вам необходимо:- Сначала корректно остановить все ваши узлы
- Затем запустить узел, который был остановлен последним, с опцией
--new-cluster, используя инструментmanticore_new_clusterв Linux. - Прочтите о перезапуске кластера для получения более подробной информации.
- Коммит 6fda Исправлен сбой, вызванный потерей планировщика после ожидания; теперь специфические планировщики, такие как
serializer, корректно восстанавливаются. - Коммит c333 Исправлена ошибка, при которой веса из правой присоединенной таблицы не могли использоваться в предложении
ORDER BY. - Issue #2644 gcc 14.2.0: исправлена ошибка вызова
lower_boundсconst knn::DocDist_t*&. ❤️ Спасибо @Azq2 за PR. - Issue #3018 Исправлена проблема с обработкой имен таблиц в верхнем регистре при автоматических вставках схемы.
- Issue #3119 Исправлен сбой при декодировании некорректного ввода base64.
- Issue #3121 Исправлены две связанные проблемы с KNN индексом при
ALTER: векторы с плавающей точкой теперь сохраняют свои исходные размерности, и KNN индексы теперь корректно генерируются. - Issue #3123 Исправлен сбой при построении вторичного индекса на пустой JSON колонке.
- Issue #3138 Исправлен сбой, вызванный дублирующимися записями.
- Issue #3151 Исправлено: опция
fuzzy=1не могла использоваться сrankerилиfield_weights. - Issue #3163 Исправлена ошибка, при которой
SET GLOBAL timezoneне имел эффекта. - Issue #3181 Исправлена проблема, при которой значения текстовых полей могли теряться при использовании ID больше 2^63.
- Issue #3189 Исправлено: операторы
UPDATEтеперь корректно учитывают настройкуquery_log_min_msec. - Issue #3247 Исправлено состояние гонки при сохранении дисковых чанков реального времени, которое могло приводить к сбою
JOIN CLUSTER.
Выпущена: 28 февраля 2025
- Issue #832 Интеграция с Kibana для более простой и эффективной визуализации данных.
- Issue #1727 Исправлены различия в точности чисел с плавающей запятой между arm64 и x86_64.
- Issue #2995 Реализованы оптимизации производительности для пакетной обработки join.
- Issue #3039 Реализованы оптимизации производительности для EstimateValues в гистограммах.
- Issue #3099 Добавлена поддержка Boost 1.87.0. ❤️ Спасибо, @cho-m за PR.
- Issue #77 Оптимизировано повторное использование блоков данных при создании фильтров с несколькими значениями; добавлены min/max в метаданные атрибутов; реализована предварительная фильтрация значений фильтра на основе min/max.
- Commit 73ac Исправлена обработка выражений в объединённых запросах, когда используются атрибуты из обеих таблиц (левой и правой); исправлена опция index_weights для правой таблицы.
- Issue #2915 Использование
avg()в запросеSELECT ... JOINмогло приводить к некорректным результатам; теперь исправлено. - Issue #2996 Исправлен некорректный набор результатов из-за неявного ограничения при включенной пакетной обработке join.
- Issue #3031 Исправлен сбой демона при завершении работы, если была активна слияние чанков.
- Issue #3037 Исправлена проблема, когда
IN(...)мог возвращать некорректные результаты. - Issue #3038 Установка
max_iops/max_iosizeв версии 7.0.0 могла ухудшать производительность индексирования; теперь исправлено. - Issue #3042 Исправлена утечка памяти в кеше запросов join.
- Issue #3052 Исправлена обработка опций запросов в объединённых JSON-запросах.
- Issue #3054 Исправлена проблема с командой ATTACH TABLE.
- Issue #3079 Исправлены несоответствия в сообщениях об ошибках.
- Issue #3087 Установка
diskchunk_flush_write_timeout=-1для каждой таблицы не отключала сброс индекса; теперь исправлено. - Issue #3088 Устранены дублирующие записи после массовой замены больших ID.
- Issue #3126 Исправлен сбой демона, вызванный полнотекстовым запросом с одним оператором
NOTи ранжировщиком выражений. - Issue #3128 Исправлена потенциальная уязвимость в библиотеке CJSON. ❤️ Спасибо, @tabudz за PR.
Выпущена: 30 января 2025 г.
- Issue #1497 Добавлен новый функционал Нечёткого поиска и Автозаполнения для упрощения поиска.
- Issue #1500 Интеграция с Kafka.
- Issue #1928 Введены вторичные индексы для JSON.
- Issue #2361 Обновления и поиск во время обновлений больше не блокируются слиянием чанков.
- Issue #2787 Автоматический сброс дисковых чанков для RT-таблиц для улучшения производительности; теперь мы автоматически сбрасываем RAM-чанки в дисковые чанки, предотвращая проблемы с производительностью из-за отсутствия оптимизаций в RAM-чанках, что иногда могло приводить к нестабильности в зависимости от размера чанка.
- Issue #2811 Опция Scroll для упрощения постраничного вывода.
- Issue #931 Интеграция с Jieba для улучшенной токенизации китайского языка.
- ⚠️ BREAKING Issue #1111 Исправлена поддержка
global_idfв RT таблицах. Требуется пересоздание таблицы. - ⚠️ BREAKING Issue #2103 Удалены тайские символы из внутреннего
cjkнабора символов. Обновите определения вашего набора символов соответственно: если у васcjk,non_cjkи тайские символы важны для вас, измените его наcjk,thai,non_cjk, илиcont,non_cjk, гдеcont— это новое обозначение для всех языков с непрерывным письмом (т.е.cjk+thai). Измените существующие таблицы с помощью ALTER TABLE. - ⚠️ BREAKING Issue #2468 CALL SUGGEST / QSUGGEST теперь совместимы с распределенными таблицами. Это увеличивает версию протокола master/agent. Если вы запускаете Manticore Search в распределенной среде с несколькими экземплярами, сначала обновите агенты, затем мастеров.
- ⚠️ BREAKING Issue #2889 Изменено имя столбца с
NameнаVariable nameдля PQ SHOW META. - ⚠️ BREAKING Issue #879 Введен переменный binlog для таблиц с новыми опциями: binlog_common, binlog для
create table/alter table. Вам необходимо выполнить чистое завершение работы экземпляра Manticore перед обновлением до новой версии. - ⚠️ BREAKING Issue #1789 Исправлено неправильное сообщение об ошибке, когда узел присоединяется к кластеру с неправильной версией протокола репликации. Это изменение обновляет протокол репликации. Если вы запускаете кластер репликации, вам необходимо:
- Сначала аккуратно остановить все ваши узлы
- Затем запустить узел, который был остановлен последним, с
--new-cluster, используя инструментmanticore_new_clusterв Linux. - Ознакомьтесь с перезапуском кластера для получения дополнительных сведений.
- ⚠️ BREAKING Issue #2308 Добавлена поддержка нескольких таблиц в
ALTER CLUSTER ADDиDROP. Это изменение также затрагивает протокол репликации. Обратитесь к предыдущему разделу за рекомендациями по обработке этого обновления. - Issue #2997 Исправлена проблема с dlopen на Macos.
- Commit 4954 Изменен стандартный порог для OPTIMIZE TABLE на таблицах с индексами KNN для улучшения производительности поиска.
- Commit cfc8 Добавлена поддержка
COUNT(DISTINCT)дляORDER BYвFACETиGROUP BY. - Issue #1103 Улучшена ясность в логировании слияния чанков.
- Issue #1130 Добавлена поддержка DBeaver.
- Issue #1546 Реализованы вторичные индексы для функций POLY2D()/GEOPOLY2D().
- Issue #1630 HTTP-запросы теперь поддерживают
Content-Encoding: gzip. - Issue #1831 Добавлена команда
SHOW LOCKS. - Issue #2187 Разрешен запрос Buddy к демону для обхода ограничения searchd.max_connections.
- Issue #2208 Добавлена поддержка объединения таблиц через JSON HTTP интерфейс.
- Issue #2235 Логирование успешно обработанных запросов через Buddy в их оригинальной форме.
- Issue #2249 Добавлен специальный режим для выполнения
mysqldumpдля реплицированных таблиц. - Issue #2268 Улучшено переименование внешних файлов при копировании для операторов
CREATE TABLEиALTER TABLE. - Issue #2402 Обновлено значение по умолчанию для searchd.max_packet_size до 128 МБ.
- Issue #2419 Добавлена поддержка модификатора IDF boost в JSON "match".
- Issue #2430 Улучшена синхронизация записи binlog для предотвращения ошибок.
- Issue #2458 Включена поддержка zlib в пакетах для Windows.
- Issue #2479 Добавлена поддержка команды SHOW TABLE INDEXES.
- Issue #2485 Установлены метаданные сессии для ответов Buddy.
- Issue #2490 Миллисекундная точность для агрегаций на совместимых конечных точках.
- Issue #2500 Изменены сообщения об ошибках для операций с кластерами, когда репликация не удается запуститься.
- Issue #2584 Новые показатели производительности в SHOW STATUS: min/max/avg/95-й/99-й процентиль по типу запроса за последние 1, 5 и 15 минут.
- Issue #2639 Заменены все вхождения
indexнаtableв запросах и ответах. - Issue #2643 Добавлен столбец
distinctв результаты агрегации конечной точки HTTP/sql. - Issue #268 Реализовано автоматическое определение типов данных, импортируемых из Elasticsearch.
- Issue #2744 Добавлена поддержка сопоставления строк для выражений сравнения JSON полей.
- Issue #2752 Добавлена поддержка выражения
uuid_shortв списке выбора. - Issue #2783 Manticore Search теперь запускает Buddy напрямую без обертки
manticore-buddy. - Issue #2785 Различные сообщения об ошибках для отсутствующих таблиц и таблиц, которые не поддерживают операции вставки.
- Issue #2789 OpenSSL 3 теперь статически встроен в
searchd. - Issue #2790 Добавлено выражение
CALL uuid_shortдля генерации последовательностей с несколькими значениямиuuid_short. - Issue #2803 Добавлены отдельные параметры для правой таблицы в операции JOIN.
- Issue #2810 Улучшена производительность агрегации HTTP JSON для соответствия
GROUP BYв SphinxQL. - Issue #2854 Добавлена поддержка
fixed_intervalв запросах Kibana, связанных с датами. - Issue #2909 Реализовано пакетирование для JOIN запросов, что улучшает производительность определенных JOIN запросов в сотни или даже тысячи раз.
- Issue #2937 Включено использование веса объединенной таблицы в запросах полного сканирования.
- Issue #2953 Исправлено логирование для запросов объединения.
- Issue #337 Скрыты исключения Buddy из лога
searchdв не-отладочном режиме. - Issue #2931 Демон завершает работу с сообщением об ошибке, если пользователь устанавливает неправильные порты для слушателя репликации.
- Commit 0c6b Исправлено: Неправильные результаты, возвращаемые в JOIN-запросах с более чем 32 столбцами.
- Issue #2335 Решена проблема, когда соединение таблиц не выполнялось, когда в условии использовались два json-атрибута.
- Issue #2338 Исправлен неправильный total_relation в многозапросах с cutoff.
- Issue #2366 Исправлено фильтрация по
json.stringв правой таблице на соединении таблиц. - Issue #2406 Включено использование
nullдля всех значений в любых POST HTTP JSON конечных точках (вставка/замена/пакет). В этом случае используется значение по умолчанию. - Issue #2418 Оптимизировано потребление памяти путем корректировки выделения max_packet_size сетевого буфера для первоначального зондирования сокета.
- Issue #2420 Исправлена вставка беззнакового целого числа в атрибут bigint через JSON интерфейс.
- Issue #2422 Исправлены вторичные индексы для корректной работы с фильтрами исключения и включенным псевдо-шардингом.
- Issue #2423 Устранен баг в manticore_new_cluster.
- Issue #2448 Решена проблема с аварийным завершением демона при неправильно сформированном запросе
_update. - Issue #2452 Исправлена неспособность гистограмм обрабатывать фильтры значений с исключениями.
- Issue #55 Исправлены запросы knn к распределенным таблицам.
- Issue #68 Улучшена обработка фильтров исключения при кодировании таблиц в колонном доступе.
- Commit 0eb1 Исправлен парсер выражений, который не подчинялся переопределенному
thread_stack. - Commit c304 Исправлен сбой при клонировании выражения IN для колонн.
- Commit edad Исправлена проблема инверсии в итераторе битов, которая вызывала сбой.
- Commit fc30 Исправлена проблема, когда некоторые пакеты Manticore автоматически удалялись с помощью
unattended-upgrades. - Issue #1019 Улучшена обработка запросов из инструмента DbForge MySQL.
- Issue #1107 Исправлено экранирование специальных символов в
CREATE TABLEиALTER TABLE. ❤️ Спасибо, @subnix за PR. - Issue #116 Исправлен дедлок при обновлении атрибута blob в замороженном индексе. Дедлок возник из-за конфликтующих блокировок при попытке разморозить индекс. Это также могло вызвать сбой в manticore-backup.
- Issue #1818
OPTIMIZEтеперь выдает ошибку, когда таблица заморожена. - Issue #2001 Разрешены имена функций для использования в качестве имен столбцов.
- Issue #2153 Исправлено аварийное завершение демона при запросе настроек таблицы с неизвестным дисковым чанком.
- Issue #2184 Исправлена проблема, когда
searchdзависал при остановке послеFREEZEиFLUSH RAMCHUNK. - Issue #2228 Удалены токены, связанные с датой/временем (и регулярные выражения) из зарезервированных слов.
- Issue #2255 Исправлен сбой на
FACETс более чем 5 полями сортировки. - Issue #2265 Исправлен сбой восстановления
mysqldumpс включеннымindex_field_lengths. - Issue #2291 Исправлен сбой при выполнении команды
ALTER TABLE. - Issue #2333 Исправлен MySQL DLL в пакете Windows для корректной работы индексатора.
- Issue #2393 Исправлена ошибка компиляции GCC. ❤️ Спасибо, @animetosho за PR.
- Issue #2447 Исправлена проблема экранирования в _update.
- Issue #2460 Исправлен сбой индексатора при объявлении нескольких атрибутов или полей с одинаковым именем.
- Issue #2467 Решена проблема аварийного завершения демона при неправильной трансформации для вложенных булевых запросов для конечных точек, связанных с "совместимостью".
- Issue #2493 Исправлено расширение в фразах с модификаторами.
- Issue #2535 Решен сбой демона при использовании ZONE или ZONESPAN полнотекстового оператора.
- Issue #2552 Исправлено создание инфиксов для обычных и RT таблиц с словарем ключевых слов.
- Issue #2571 Исправлен ответ с ошибкой в запросе
FACET; установлен порядок сортировки по умолчанию наDESCдляFACETсCOUNT(*). - Issue #2580 Исправлено аварийное завершение демона на Windows во время запуска.
- Issue #2603 Исправлено усечение запросов для HTTP конечных точек
/sqlи/sql?mode=raw; сделаны запросы из этих конечных точек последовательными без необходимости заголовкаquery=. - Issue #2623 Исправлена проблема, когда авто-схема создает таблицу, но одновременно не удается.
- Issue #2627 Исправлена библиотека HNSW для поддержки загрузки нескольких KNN индексов.
- Issue #2630 Исправлена проблема заморозки, когда несколько условий происходят одновременно.
- Issue #2645 Исправлен сбой с фатальной ошибкой при использовании
ORс KNN поиском. - Issue #2647 Исправлена проблема, когда
indextool --mergeidf *.idf --out global.idfудаляет выходной файл после создания. - Issue #2658 Исправлено аварийное завершение демона при подвыборе с
ORDER BYстрокой во внешнем выборе. - Issue #2686 Исправлен сбой при обновлении атрибута float вместе с атрибутом string.
- Issue #2704 Исправлена проблема, когда несколько стоп-слов из токенизаторов
lemmatize_xxx_allувеличиваютhitposпоследующих токенов. - Issue #2708 Исправлен сбой при
ALTER ... ADD COLUMN ... TEXT. - Issue #2737 Исправлена проблема, когда обновление атрибута blob в замороженной таблице с хотя бы одним RAM чанком вызывает ожидание последующих запросов
SELECT, пока таблица не будет разморожена. - Issue #2742 Исправлен пропуск кэша запросов для запросов с упакованными факторами.
- Issue #2775 Manticore теперь сообщает об ошибке при неизвестном действии вместо сбоя на запросах
_bulk. - Issue #2791 Исправлен возврат ID вставленного документа для HTTP конечной точки
_bulk. - Issue #2797 Исправлен сбой в группировщике при обработке нескольких таблиц, одна из которых пуста, а другая имеет разное количество совпадающих записей.
- Issue #2835 Исправлен сбой в сложных запросах
SELECT. - Issue #2872 Добавлено сообщение об ошибке, если аргумент
ALLилиANYв выраженииINне является JSON-атрибутом. - Issue #2882 Исправлено аварийное завершение демона при обновлении MVA в больших таблицах.
- Issue #2888 Исправлен сбой при ошибке токенизации с
libstemmer. ❤️ Спасибо, @subnix за PR. - Issue #2919 Исправлена проблема, когда присоединенный вес из правой таблицы не работал корректно в выражениях.
- Issue #2919 Исправлена проблема, когда вес правой присоединенной таблицы не работает в выражениях.
- Issue #325 Исправлен сбой
CREATE TABLE IF NOT EXISTS ... WITH DATA, когда таблица уже существует. - Issue #351 Исправлена ошибка неопределенного ключа массива "id" при подсчете по KNN с ID документа.
- Issue #359 Исправлена функциональность
REPLACE INTO cluster_name:table_name. - Issue #67 Исправлена фатальная ошибка при запуске контейнера Manticore Docker с
--network=host.
Выпущена: 22 ноября 2024
Версия 6.3.8 продолжает серию 6.3 и включает только исправления ошибок.
- PR #2777 Исправлено вычисление доступных потоков, когда параллелизм запросов ограничен настройками
threadsилиmax_threads_per_query.
Выпущен: 7 октября 2024
- Issue #64 Решена проблема, когда утилита
unattended-upgrades, которая автоматически устанавливает обновления пакетов на системах на базе Debian, неверно помечала несколько пакетов Manticore, включаяmanticore-galera,manticore-executorиmanticore-columnar-lib, для удаления. Это произошло из-за того, чтоdpkgошибочно считал виртуальный пакетmanticore-extraизбыточным. Были внесены изменения, чтобы гарантировать, чтоunattended-upgradesбольше не пытается удалить важные компоненты Manticore.
Выпущена: 2 августа 2024
Версия 6.3.6 продолжает серию 6.3 и включает только исправления ошибок.
- Issue #2477 Исправлен сбой, введенный в версии 6.3.4, который мог произойти при работе с выражениями и распределенными или несколькими таблицами.
- Issue #2352 Исправлен сбой демона или внутренняя ошибка при раннем выходе, вызванная
max_query_time, при запросе нескольких индексов.
Выпущена: 31 июля 2024
Версия 6.3.4 продолжает серию 6.3 и включает только незначительные улучшения и исправления ошибок.
- Issue #1130 Добавлена поддержка DBeaver.
- Issue #2146 Улучшено экранирование разделителей в формах слов и исключениях.
- Issue #2315 Добавлены операторы сравнения строк в выражениях списка SELECT.
- Issue #2363 Добавлена поддержка нулевых значений в запросах Elastic-like bulk.
- Issue #2374 Добавлена поддержка mysqldump версии 9.
- Issue #2375 Улучшена обработка ошибок в HTTP JSON запросах с JSON путем к узлу, где возникает ошибка.
- Issue #2280 Исправлено ухудшение производительности в запросах с подстановочными знаками с множеством совпадений, когда disk_chunks > 1.
- Issue #2332 Исправлен сбой в выражениях списка SELECT MVA MIN или MAX для пустых массивов MVA.
- Issue #2339 Исправлена некорректная обработка запроса бесконечного диапазона Kibana.
- Issue #2342 Исправлен фильтр соединения по колоннарным атрибутам из правой таблицы, когда атрибут отсутствует в списке SELECT.
- Issue #2343 Исправлен дублирующийся спецификатор 'static' в Manticore 6.3.2.
- Issue #2344 Исправлено LEFT JOIN, возвращающий несовпадающие записи, когда используется MATCH() по правой таблице.
- Issue #2350 Исправлено сохранение дискового чанка в RT индексе с
hitless_words. - Issue #2364 Свойство 'aggs_node_sort' теперь можно добавлять в любом порядке среди других свойств.
- Issue #2368 Исправлена ошибка в порядке full-text и filter в JSON запросе.
- Issue #2376 Исправлен баг, связанный с некорректным JSON ответом для длинных UTF-8 запросов.
- Issue #2684 Исправлено вычисление выражений presort/prefilter, которые зависят от объединенных атрибутов.
- Issue #301 Изменен метод вычисления размера данных для метрик, чтобы читать из файла
manticore.json, а не проверять весь размер каталога данных. - Issue #302 Добавлена обработка запросов валидации от Vector.dev.
Выпущена: 26 июня 2024
Версия 6.3.2 продолжает серию 6.3 и включает несколько исправлений ошибок, некоторые из которых были обнаружены после выпуска 6.3.0.
- ⚠️Issue #2305 Обновлены значения aggs.range до числовых.
- Коммит c51c Исправлено группирование по сохраненной проверке против объединения rset.
- Коммит 0e85 Исправлен сбой в демоне при запросе с использованием символов подстановки в RT индексе с включенным словарем CRC и
local_df. - Проблема #2200 Исправлен сбой в JOIN на
count(*)без GROUP BY. - Проблема #2201 Исправлен JOIN, который не возвращал предупреждение при попытке группировки по полю полного текста.
- Проблема #2230 Устранена проблема, когда добавление атрибута через
ALTER TABLEне учитывало параметры KNN. - Проблема #2231 Исправлен сбой при удалении пакета
manticore-toolsRedhat версии 6.3.0. - Проблема #2242 Исправлены проблемы с JOIN и несколькими операторами FACET, возвращающими некорректные результаты.
- Проблема #2250 Исправлено сообщение об ошибке при выполнении ALTER TABLE, если таблица находится в кластере.
- Проблема #2252 Исправлен оригинальный запрос, передаваемый в buddy из интерфейса SphinxQL.
- Проблема #2267 Улучшено расширение символов подстановки в
CALL KEYWORDSдля RT индекса с дисковыми чанками. - Проблема #271 Исправлено зависание некорректных запросов
/cli. - Проблема #274 Устранены проблемы, когда параллельные запросы к Manticore могли зависать.
- Проблема #275 Исправлено зависание
drop table if exists t; create table tчерез/cli.
- Проблема #2270 Добавлена поддержка формата
cluster:nameв HTTP-эндпоинте/_bulk.
Выпущено: 23 мая 2024 года
- Проблема #839 Реализован тип данных float_vector; реализован поиск векторов.
- Проблема #1673 INNER/LEFT JOIN (бета-версия).
- Проблема #1744 Реализовано автоматическое определение форматов даты для полей timestamp.
- Проблема #1720 Изменена лицензия Manticore Search с GPLv2-or-later на GPLv3-or-later.
- Коммит 7a55 Запуск Manticore в Windows теперь требует Docker для работы Buddy.
- Проблема #1541 Добавлен оператор полного текста REGEX.
- Проблема #2091 Поддержка Ubuntu Noble 24.04.
- Коммит 514d Переработка операций с временем для повышения производительности и новые функции даты/времени:
- CURDATE() - Возвращает текущую дату в местном часовом поясе
- QUARTER() - Возвращает целый квартал года из аргумента timestamp
- DAYNAME() - Возвращает название дня недели для данного аргумента timestamp
- MONTHNAME() - Возвращает название месяца для данного аргумента timestamp
- DAYOFWEEK() - Возвращает целый индекс дня недели для данного аргумента timestamp
- DAYOFYEAR() - Возвращает целый день года для данного аргумента timestamp
- YEARWEEK() - Возвращает целый год и код дня первой недели для данного аргумента timestamp
- DATEDIFF() - Возвращает количество дней между двумя заданными временными метками
- DATE() - Форматирует часть даты из аргумента timestamp
- TIME() - Форматирует часть времени из аргумента timestamp
- timezone - Часовой пояс, используемый функциями, связанными с датой/временем.
- Коммит 30e7 Добавлены агрегаты range, histogram, date_range и date_histogram в HTTP-интерфейс и аналогичные выражения в SQL.
- Issue #1285 Поддержка версий Filebeat 8.10 - 8.11.
- Issue #1771 ALTER TABLE ... type='distributed'.
- Issue #1788 Добавлена возможность копирования таблиц с помощью SQL-запроса CREATE TABLE ... LIKE ... WITH DATA.
- Issue #2072 Оптимизирован алгоритм компактирования таблиц: Ранее как ручные OPTIMIZE, так и автоматические auto_optimize процессы сначала объединяли чанки, чтобы убедиться, что их количество не превышает лимит, а затем удаляли документы из всех других чанков, содержащих удаленные документы. Этот подход иногда был слишком ресурсоемким и был отключен. Теперь объединение чанков происходит исключительно в соответствии с настройкой progressive_merge. Однако чанки с большим количеством удаленных документов с большей вероятностью будут объединены.
- Commit ce6c Добавлена защита от загрузки вторичного индекса более новой версии.
- Issue #1417 Частичная замена через REPLACE INTO ... SET.
- Commit 7c16 Обновлены размеры буферов слияния по умолчанию:
.spa(скалярные атрибуты): 256KB -> 8MB;.spb(блоб-атрибуты): 256KB -> 8MB;.spc(колоночные атрибуты): 1MB, без изменений;.spds(docstore): 256KB -> 8MB;.spidx(вторичные индексы): 256KB буфер -> 128MB лимит памяти;.spi(словарь): 256KB -> 16MB;.spd(списки документов): 8MB, без изменений;.spp(списки попаданий): 8MB, без изменений;.spe(списки пропусков): 256KB -> 8MB. - Issue #1859 Добавлена композитная агрегация через JSON.
- Commit 216b Отключен PCRE.JIT из-за проблем с некоторыми шаблонами regex и отсутствия значительной выгоды по времени.
- Commit 55cd Добавлена поддержка ванильной Galera v.3 (api v25) (
libgalera_smm.soиз MySQL 5.x). - Commit 86f9 Изменен суффикс метрики с
_rateна_rps. - Commit c0c1 Улучшена документация о поддержке HA балансировщика.
- Commit d1d2 Изменено
indexнаtableв сообщениях об ошибках; исправлено сообщение об ошибке парсера bison. - Commit fd26 Поддержка
manticore.tblв качестве имени таблицы. - Issue #1105 Поддержка запуска индексатора через systemd (docs). ❤️ Спасибо, @subnix за PR.
- Issue #1294 Поддержка вторичных индексов в GEODIST().
- Issue #1394 Упрощен SHOW THREADS.
- Issue #1424 Добавлена поддержка значений по умолчанию (
agent_connect_timeoutиagent_query_timeout) для оператораcreate distributed table. - Issue #1442 Добавлен параметр запроса поиска expansion_limit, который переопределяет
searchd.expansion_limit. - Issue #1448 Реализован ALTER TABLE для преобразования int->bigint.
- Issue #1456 Метаинформация в ответе MySQL.
- Issue #1494 SHOW VERSION.
- Issue #1582 Поддержка удаления документов по массиву id через JSON.
- Issue #1589 Улучшено сообщение об ошибке "unsupported value type".
- Issue #1634 Добавлена версия Buddy в
SHOW STATUS. - Issue #1641 Оптимизация запросов на совпадение в случае нуля документов для ключевого слова.
- Issue #1712 Добавлено преобразование в булевый атрибут из строкового значения "true" и "false" при отправке данных.
- Issue #1713 Добавлена таблица access_dict и опция searchd.
- Issue #1767 Добавлены новые параметры: expansion_merge_threshold_docs и expansion_merge_threshold_hits в секцию searchd конфигурации; сделан порог для объединения крошечных терминов расширенных терминов настраиваемым.
- Issue #1768 Добавлено отображение времени последней команды в
@@system.sessions. - Issue #1806 Обновлен протокол Buddy до версии 2.
- Issue #1810 Реализованы дополнительные форматы запросов к конечной точке
/sqlдля упрощения интеграции с библиотеками. - Issue #1825 Добавлен раздел Информация в SHOW BUDDY PLUGINS.
- Issue #1837 Улучшено потребление памяти в
CALL PQс большими пакетами. - Issue #1853 Переключен компилятор с Clang 15 на Clang 16.
- Issue #1857 Добавлено сравнение строк. ❤️ Спасибо, @etcd за PR.
- Issue #1915 Добавлена поддержка объединенных хранимых полей.
- Issue #1937 Логирование хоста:порта клиента в журнале запросов.
- Issue #1981 Исправлена ошибка.
- Issue #1983 Введена поддержка уровней подробности для плана запроса через JSON.
- Issue #2010 Отключено логирование запросов от Buddy, если не установлен
log_level=debug. - Issue #2035 Поддержка Linux Mint 21.3.
- Issue #2056 Manticore не удалось собрать с Mysql 8.3+.
- Issue #2112 Команда
DEBUG DEDUPдля чанков таблицы реального времени, которые могут содержать дублирующиеся записи после присоединения обычной таблицы, содержащей дубликаты. - Issue #212 Добавлено время к SHOW QUERIES.
- Issue #218 Обработка столбца
@timestampкак временной метки. - Issue #252 Реализована логика для включения/выключения плагинов Buddy.
- Issue #254 Обновлен composer до более свежей версии, в которой исправлены недавние уязвимости CVE.
- Issue #340 Небольшая оптимизация в юните systemd Manticore, связанная с
RuntimeDirectory. - Issue #51 Добавлена поддержка rdkafka и обновлено до PHP 8.3.3.
- Issue #527 Поддержка присоединения таблицы реального времени. Новая команда ALTER TABLE ... RENAME.
- ⚠️Issue #1436 Исправлена проблема с расчетом IDF.
local_dfтеперь по умолчанию. Улучшен протокол поиска мастер-агент (версия обновлена). Если вы запускаете Manticore Search в распределенной среде с несколькими экземплярами, сначала обновите агентов, затем мастеров. - ⚠️Issue #1572 Добавлено реплицирование распределенных таблиц и обновлен протокол репликации. Если вы запускаете кластер репликации, вам нужно:
- Сначала аккуратно остановить все ваши узлы
- Затем запустить узел, который был остановлен последним, с
--new-cluster, используя инструментmanticore_new_clusterв Linux. - Ознакомьтесь с перезапуском кластера для получения дополнительных деталей.
- ⚠️Issue #1763 Псевдонимы конечных точек HTTP API
/json/*были устаревшими. - ⚠️Issue #1982 Изменено профилирование на план в JSON, добавлено профилирование запросов для JSON.
- ⚠️Commit e235 manticore-backup больше не создает резервные копии
plugin_dir. - ⚠️Issue #171 Перенесен Buddy на Swoole для улучшения производительности и стабильности. При переходе на новую версию убедитесь, что все пакеты Manticore обновлены.
- ⚠️Issue #196 Объединены все основные плагины в Buddy и изменена основная логика.
- ⚠️Issue #2107 Обработка идентификаторов документов как чисел в ответах
/search. - ⚠️Issue #38 Добавлен Swoole, отключен ZTS и удалено параллельное расширение.
- ⚠️Issue #1929 Переопределение в
charset_tableне работало в некоторых случаях.
- Commit 3376 Исправлена ошибка репликации на SST больших файлов.
- Commit 6d36 Добавлен механизм повторной попытки для команд репликации; исправлена ошибка соединения репликации в загруженной сети с потерей пакетов.
- Commit 842e Изменено сообщение FATAL в репликации на сообщение WARNING.
- Commit 8c32 Исправлен расчет
gcache.page_sizeдля кластеров репликации без таблиц или с пустыми таблицами; также исправлено сохранение и загрузка параметров Galera. - Commit a2af Добавлена функциональность для пропуска команды репликации обновления узлов на узле, который присоединяется к кластеру.
- Commit c054 Исправлен взаимоблокировка во время репликации при обновлении атрибутов blob по сравнению с заменой документов.
- Commit e80d Добавлены параметры конфигурации searchd replication_connect_timeout, replication_query_timeout, replication_retry_delay, replication_retry_count для управления сетью во время репликации, аналогично
searchd.agent_*, но с другими значениями по умолчанию. - Issue #1356 Исправлена повторная попытка узлов репликации после пропуска некоторых узлов и неудачи разрешения имен этих узлов.
- Issue #1445 Исправлен уровень подробности журнала репликации в
show variables. - Issue #1482 Исправлена проблема репликации для узла-присоединителя, подключающегося к кластеру на поде, перезапущенном в Kubernetes.
- Issue #1962 Исправлено долгое ожидание репликации для изменения на пустом кластере с недопустимым именем узла.
- Commit 8a48 Исправлена очистка неиспользуемых совпадений в
count distinct, которая могла приводить к сбою. - Issue #1569 Бинарный лог теперь записывается с транзакционной гранулярностью.
- Issue #2089 Исправлена ошибка, связанная с 64-битными идентификаторами, которая могла приводить к ошибке "Malformed packet" при вставке через MySQL, что в свою очередь приводило к повреждению таблиц и дублированию идентификаторов.
- Issue #2160 Исправлена вставка дат как UTC вместо локального часового пояса.
- Issue #2177 Исправлен сбой, возникавший при выполнении поиска в таблице real-time с непустым
index_token_filter. - Issue #2209 Изменена фильтрация дубликатов в колоннарном хранилище RT для исправления сбоев и некорректных результатов запросов.
- Commit 001d Исправлен html stipper, повреждающий память после обработки объединённого поля.
- Commit 00eb Предотвращена перемотка потока после flush для избежания проблем взаимодействия с mysqldump.
- Commit 0553 Не ждать завершения preread, если он не был запущен.
- Commit 055a Исправлен вывод длинной строки Buddy: теперь она разделяется на несколько строк в логе searchd.
- Commit 0a88 Перемещено предупреждение интерфейса MySQL о неудачной установке уровня подробности заголовка
debugv. - Commit 150a Исправлено состояние гонки при операциях управления несколькими кластерами; запрещено создание нескольких кластеров с одинаковым именем или путём.
- Commit 2e40 Исправлен неявный cutoff в полнотекстовых запросах; MatchExtended разделён на шаблонную часть partD.
- Commit 75f5 Исправлено расхождение параметра
index_exact_wordsмежду индексированием и загрузкой таблицы в демон. - Commit 7643 Исправлено отсутствие сообщения об ошибке при удалении некорректного кластера.
- Commit 7a03 Исправлены ошибки CBO при объединении через очередь; исправлено псевдо-шардирование CBO для RT.
- Commit 7b4e При запуске без библиотеки secondary index (SI) и соответствующих параметров в конфигурации выводилось вводящее в заблуждение сообщение 'WARNING: secondary_indexes set but failed to initialize secondary library'.
- Commit 8496 Исправлена сортировка хитов в quorum.
- Commit 8973 Исправлена проблема с опциями в верхнем регистре в плагине ModifyTable.
- Commit 9935 Исправлено восстановление из дампа с пустыми значениями JSON (представленными как NULL).
- Commit a28f Исправлен таймаут SST на узле присоединения при получении SST с использованием pcon.
- Commit b5a5 Исправлен сбой при выборе строкового атрибута с псевдонимом.
- Commit c556 Добавлено преобразование запроса терма в
=termв полнотекстовом запросе с использованием поляmorphology_skip_fields. - Commit cdc3 Добавлен отсутствующий ключ конфигурации (skiplist_cache_size).
- Commit cf6e Исправлен сбой в ранжировщике выражений при большом сложном запросе.
- Commit e513 Исправлен конфликт CBO полнотекстового поиска с некорректными подсказками индексов.
- Commit eb05 Прерывание preread при выключении для ускорения завершения работы.
- Commit f945 Изменён расчёт стека для полнотекстовых запросов, чтобы избежать сбоя при сложном запросе.
- Issue #1262 Исправлен сбой индексатора при индексировании SQL-источника с несколькими столбцами с одинаковым именем.
- Issue #1273 Возвращать 0 вместо
для несуществующих системных переменных. - Issue #1289 Исправлена ошибка indextool при проверке внешних файлов таблицы RT.
- Issue #1335 Исправлена ошибка разбора запроса из-за нескольких форм слова внутри фразы.
- Issue #1364 Добавлен повтор воспроизведения пустых файлов binlog для старых версий binlog.
- Issue #1365 Исправлено удаление последнего пустого файла binlog.
- Issue #1372 Исправлены некорректные относительные пути (преобразуемые в абсолютные относительно директории запуска демона) после изменений в
data_dir, влияющих на текущий рабочий каталог при старте демона. - Issue #1393 Существенное замедление в hn_small: получение/кеширование информации о CPU при запуске демона.
- Issue #1395 Исправлено предупреждение об отсутствии внешнего файла при загрузке индекса.
- Issue #1402 Исправлен сбой в глобальных группировщиках при освобождении атрибутов data ptr.
- Issue #1403 _ADDITIONAL_SEARCHD_PARAMS не работает.
- Issue #1427 Исправлено замещение параметра
agent_query_timeoutдля таблицы на значение параметра по умолчаниюagent_query_timeout. - Issue #1444 Исправлен сбой в группировщике и ранжировщике при использовании
packedfactors()с несколькими значениями на совпадение. - Issue #1458 Manticore падает при частых обновлениях индекса.
- Issue #1481 Исправлен сбой при очистке разобранного запроса после ошибки разбора.
- Issue #1484 Исправлено ненаправление HTTP JSON-запросов к buddy.
- Issue #1499 Корневое значение JSON-атрибута не могло быть массивом. Исправлено.
- Issue #1507 Исправлен сбой при пересоздании таблицы в рамках транзакции.
- Issue #1515 Исправлено расширение сокращённых форм русских лемм.
- Issue #1579 Исправлено использование атрибутов JSON и STRING в выражении [date_format](Functions/Date_and_time_functions.md#DATE_FORMAT()).
- Issue #1580 Исправлен группировщик для нескольких псевдонимов JSON-полей.
- Issue #1594 Некорректное total_related в dev: исправлен неявный cutoff vs limit; добавлено улучшенное обнаружение полного сканирования в JSON-запросах.
- Issue #1603 Исправлено использование атрибутов JSON и STRING во всех выражениях дат.
- Issue #1609 Сбой при использовании LEVENSHTEIN().
- Issue #1612 Исправлено повреждение памяти после ошибки разбора поискового запроса с подсветкой.
- Issue #1614 Отключено расширение подстановочных символов для терминов короче
min_prefix_len/min_infix_len. - Issue #1617 Изменено поведение: не логировать ошибку, если Buddy успешно обрабатывает запрос.
- Issue #1635 Исправлено значение total в метаинформации поискового запроса для запросов с установленным limit.
- Issue #1640 Невозможно использовать таблицу с буквами верхнего регистра через JSON в режиме plain.
- Issue #1643 Добавлено значение по умолчанию для
SPH_EXTNODE_STACK_SIZE. - Issue #1646 Исправлен лог SphinxQL отрицательного фильтра с ALL/ANY для атрибута MVA.
- Issue #1660 Исправлено применение списков удаления docid из других индексов. ❤️ Спасибо, @raxoft, за PR.
- Issue #1668 Исправлены пропущенные совпадения из-за преждевременного выхода при полном сканировании raw индекса (без итераторов индексов); удалён cutoff из plain row iterator.
- Issue #1671 Исправлена ошибка
FACETпри запросе к распределённой таблице с агентными и локальными таблицами. - Issue #1690 Исправлен сбой при оценке гистограммы для больших значений.
- Issue #1692 Сбой при выполнении alter table tbl add column col uint.
- Issue #1710 Пустой результат для условия
WHERE json.array IN (<value>). - Issue #172 Исправлена проблема с TableFormatter при отправке запроса на
/cli. - Issue #1742
CREATE TABLEне выдавал ошибку в случае отсутствия файла wordforms. - Issue #1762 Порядок атрибутов в таблицах RT теперь соответствует порядку в конфигурации.
- Issue #1765 HTTP-булев запрос с условием 'should' возвращает некорректные результаты.
- Issue #1769 Сортировка по строковым атрибутам не работает с
SPH_SORT_ATTR_DESCиSPH_SORT_ATTR_ASC. - Issue #177 Отключён HTTP-заголовок
Expect: 100-continueдля curl-запросов к Buddy. - Issue #1791 Сбой, вызванный псевдонимом в GROUP BY.
- Issue #1792 SQL meta summary показывает неправильное время в Windows.
- Issue #1794 Исправлено падение производительности для однотерминных JSON-запросов.
- Issue #1798 Несовместимые фильтры не вызывали ошибку на
/search. - Issue #1802 Исправлены операции
ALTER CLUSTER ADDиJOIN CLUSTERдля ожидания друг друга, что предотвращает состояние гонки, когдаALTERдобавляет таблицу в кластер, пока узел-донора отправляет таблицы узлу-присоединителю. - Issue #1811 Некорректная обработка запросов
/pq/{table}/*. - Issue #1816
UNFREEZEне работал в некоторых случаях. - Issue #183 Исправлена проблема с восстановлением MVA в некоторых случаях.
- Issue #1849 Исправлен сбой indextool при завершении работы в связке с MCL.
- Issue #1866 Исправлено ненужное декодирование URL для запросов
/cli_json. - Issue #1872 Изменена логика задания plugin_dir при старте демона.
- Issue #1874 Сбой при alter table ... exceptions.
- Issue #1891 Manticore падает с
signal 11при вставке данных. - Issue #1920 Уменьшено ограничение пропускной способности для low_priority.
- Issue #1924 Ошибка при работе mysqldump и восстановлении mysql.
- Issue #1951 Исправлено некорректное создание распределённой таблицы в случае отсутствия локальной таблицы или неверного описания агента; теперь возвращается сообщение об ошибке.
- Issue #1972 Реализован счётчик
FREEZEдля избежания проблем с freeze/unfreeze. - Issue #1980 Учтён тайм-аут запроса в OR-узлах. Ранее
max_query_timeв некоторых случаях не работал. - Issue #1986 Не удалось переименовать новый файл в текущий [manticore.json].
- Issue #1988 Полнотекстовый запрос мог игнорировать подсказку CBO
SecondaryIndex. - Issue #1990 Исправлен
expansion_limitдля разбиения конечного набора результатов ключевых слов вызова из нескольких дисковых или RAM чанков. - Issue #1994 Неверные внешние файлы.
- Issue #2021 Некоторые процессы manticore-executor могли оставаться запущенными после остановки Manticore.
- Issue #2029 Сбой при использовании расстояния Левенштейна.
- Issue #2037 Ошибка после нескольких запусков оператора max на пустом индексе.
- Issue #2052 Сбой при многогруппировке с JSON.field.
- Issue #2067 Manticore падал при некорректном запросе к _update.
- Issue #2069 Исправлена проблема с компараторами строковых фильтров для замкнутых диапазонов в JSON-интерфейсе.
- Issue #2082
alterне выполнялся, когда путь data_dir находился на символической ссылке. - Issue #2102 Улучшена специальная обработка SELECT-запросов в mysqldump для обеспечения совместимости получаемых INSERT-операторов с Manticore.
- Issue #2103 Тайские символы были в неправильных наборах символов.
- Issue #2124 Сбой при использовании SQL-запроса с зарезервированным словом.
- Issue #2154 Таблицы с wordforms не могли быть импортированы.
- Issue #2176 Исправлен сбой, возникавший при установке параметра engine в 'columnar' и добавлении дублированных идентификаторов через JSON.
- Issue #223 Корректная ошибка при попытке вставить документ без схемы и без имён столбцов.
- Issue #239 Многострочная вставка Auto-schema могла завершаться неудачей.
- Issue #399 Добавлено сообщение об ошибке при индексации, если атрибут id объявлен в источнике данных.
- Issue #59 Сбой кластера Manticore.
- Issue #68 optimize.php падал, если таблица percolate присутствовала.
- Issue #77 Исправлены ошибки при развертывании на Kubernetes.
- Issue #274 Исправлена некорректная обработка параллельных запросов к Buddy.
- Issue #97 Установить VIP HTTP порт по умолчанию, если он доступен.
Различные улучшения: улучшена проверка версий и потоковая декомпрессия ZSTD; добавлены пользовательские подсказки для несоответствий версий во время восстановления; исправлено неправильное поведение подсказок для разных версий при восстановлении; улучшена логика декомпрессии для чтения непосредственно из потока, а не в рабочую память; добавлен флаг--force - Commit 3b35 Добавлено отображение версии резервной копии после запуска поиска Manticore для выявления проблем на этом этапе.
- Commit ad2e Обновлено сообщение об ошибке для неудачных подключений к демону.
- Commit ce5e Исправлена проблема с преобразованием абсолютных путей резервных копий в относительные и удалена проверка на возможность записи при восстановлении, чтобы разрешить восстановление из разных путей.
- Commit db7e Добавлена сортировка для итератора файлов, чтобы обеспечить согласованность в различных ситуациях.
- Issue #106 Резервное копирование и восстановление нескольких конфигураций.
- Issue #91 Добавлен defattr для предотвращения необычных пользовательских прав на файлы после установки на RHEL.
- Issue #91 Добавлен дополнительный chown, чтобы гарантировать, что файлы по умолчанию принадлежат пользователю root в Ubuntu.
- Commit f104 Поддержка векторного поиска.
- Commit 2169 Исправлена очистка временных файлов во время прерванной настройки сборки вторичного индекса. Это решает проблему, когда демон превышал лимит открытых файлов при создании файлов
tmp.spidx. - Commit 709b Использовать отдельную библиотеку streamvbyte для колоночного и SI.
- Commit 1c26 Добавлено предупреждение о том, что колоночное хранилище не поддерживает json атрибуты.
- Commit 3acd Исправлена распаковка данных в SI.
- Commit 574c Исправлен сбой при сохранении дискового чанка с смешанным построчным и колоночным хранилищем.
- Commit e87f Исправлен итератор SI, который намекал на уже обработанный блок.
- Issue #1474 Обновление не работает для построчной MVA колонки с колоночным движком.
- Issue #1510 Исправлен сбой при агрегации к колоночному атрибуту, использованному в
HAVING. - Issue #1519 Исправлен сбой в ранжировщике
exprпри использовании колоночного атрибута.
- ❗Issue #42 Поддержка обычной индексации через переменные окружения.
- ❗Issue #47 Улучшена гибкость конфигурации через переменные окружения.
- Issue #54 Улучшены процессы резервного копирования и восстановления для Docker.
- Issue #77 Улучшен entrypoint для обработки восстановления резервной копии только при первом запуске.
- Commit a27c Исправлен лог запросов в stdout.
- Issue #38 Заглушить предупреждения BUDDY, если EXTRA не установлен.
- Issue #71 Исправлено имя хоста в
manticore.conf.sh.
Выпущена: 23 августа 2023 года
Версия 6.2.12 продолжает серию 6.2 и устраняет проблемы, обнаруженные после выпуска 6.2.0.
- ❗Проблема #1351 "Manticore 6.2.0 не запускается через systemctl на Centos 7": Изменен
TimeoutStartSecсinfinityна0для лучшей совместимости с Centos 7. - ❗Проблема #1364 "Сбой после обновления с 6.0.4 до 6.2.0": Добавлена функция воспроизведения для пустых файлов binlog из более старых версий binlog.
- PR #1334 "исправлена опечатка в searchdreplication.cpp": Исправлена опечатка в
searchdreplication.cpp: beggining -> beginning. - Проблема #1337 "Manticore 6.2.0 WARNING: conn (local)(12), sock=8088: выход на неудачном заголовке MySQL, AsyncNetInputBuffer_c::AppendData: ошибка 11 (Ресурс временно недоступен) возвращает -1": Понижен уровень подробности предупреждения интерфейса MySQL о заголовке до logdebugv.
- Проблема #1355 "присоединение к кластеру зависает, когда node_address не может быть разрешен": Улучшен повторный запрос репликации, когда определенные узлы недоступны, и их разрешение имен не удается. Это должно решить проблемы в Kubernetes и Docker узлах, связанные с репликацией. Улучшено сообщение об ошибке для неудач старта репликации и внесены обновления в тестовую модель 376. Кроме того, предоставлено четкое сообщение об ошибке для неудач разрешения имен.
- Проблема #1361 "Нет сопоставления нижнего регистра для "Ø" в наборе символов non_cjk": Скорректировано сопоставление для символа 'Ø'.
- Проблема #1365 "searchd оставляет binlog.meta и binlog.001 после чистой остановки": Обеспечено правильное удаление последнего пустого файла binlog.
- Коммит 0871: Исправлена проблема сборки
Thd_tна Windows, связанная с ограничениями атомарного копирования. - Коммит 1cc0: Решена проблема с FT CBO против
ColumnarScan. - Коммит c6bf: Внесены исправления в тест 376 и добавлена замена для ошибки
AF_INETв тесте. - Коммит cbc3: Решена проблема взаимной блокировки во время репликации при обновлении атрибутов blob по сравнению с заменой документов. Также удален rlock индекса во время коммита, так как он уже заблокирован на более базовом уровне.
- Коммит 4f91 Обновлена информация о конечных точках
/bulkв руководстве.
- Поддержка Manticore Columnar Library v2.2.4
Выпущено: 4 августа 2023 года
- Оптимизатор запросов был улучшен для поддержки полнотекстовых запросов, что значительно повысило эффективность поиска и производительность.
- Интеграции с:
- mysqldump - для создания логических резервных копий с использованием
mysqldump - Apache Superset и Grafana для визуализации данных, хранящихся в Manticore
- HeidiSQL и DBForge для упрощения разработки с Manticore
- mysqldump - для создания логических резервных копий с использованием
- Мы начали использовать GitHub workflows, что упрощает участникам использование того же процесса Непрерывной Интеграции (CI), который применяет основная команда при подготовке пакетов. Все задания могут выполняться на хостах GitHub, что облегчает тестирование изменений в вашем форке Manticore Search.
- Мы начали использовать CLT для тестирования сложных сценариев. Например, теперь мы можем гарантировать, что пакет, собранный после коммита, может быть правильно установлен на всех поддерживаемых операционных системах Linux. Командный тестер (CLT) предоставляет удобный способ записи тестов в интерактивном режиме и их легкого воспроизведения.
- Значительное улучшение производительности операции подсчета уникальных значений за счет использования комбинации хеш-таблиц и HyperLogLog.
- Включено многопоточное выполнение запросов, содержащих вторичные индексы, с количеством потоков, ограниченным количеством физических ядер ЦП. Это должно значительно улучшить скорость выполнения запросов.
pseudo_shardingбыл скорректирован, чтобы ограничиваться количеством свободных потоков. Это обновление значительно повышает производительность пропускной способности.- Пользователи теперь могут указывать движок хранения атрибутов по умолчанию через настройки конфигурации, что обеспечивает лучшую настройку в соответствии с конкретными требованиями нагрузки.
- Поддержка Manticore Columnar Library 2.2.0 с многочисленными исправлениями ошибок и улучшениями в вторичных индексах.
- Buddy #153: HTTP-эндпоинт /pq теперь служит псевдонимом для HTTP-эндпоинта
/json/pq. - Commit 0bf1: Мы обеспечили совместимость с многобайтовыми символами для
upper()иlower(). - Commit 2bb9: Вместо сканирования индекса для запросов
count(*)теперь возвращается предрассчитанное значение. - Commit 3c84: Теперь возможно использовать
SELECTдля выполнения произвольных вычислений и отображения@@sysvars. В отличие от предыдущего, вы больше не ограничены только одним вычислением. Поэтому запросы, такие какselect user(), database(), @@version_comment, version(), 1+1 as a limit 10, вернут все столбцы. Обратите внимание, что необязательный 'limit' всегда будет игнорироваться. - Commit 6aca: Реализован заглушечный запрос
CREATE DATABASE. - Commit 9dc1: При выполнении
ALTER TABLE table REBUILD SECONDARYвторичные индексы теперь всегда перестраиваются, даже если атрибуты не были обновлены. - Commit 46ed: Сортировщики, использующие предрассчитанные данные, теперь идентифицируются перед использованием CBO, чтобы избежать ненужных расчетов CBO.
- Commit 102a: Реализация имитации и использование стека выражений полнотекстового поиска для предотвращения сбоев демона.
- Commit 979f: Быстрый код был добавлен для клонирования совпадений для совпадений, которые не используют строковые/массивные/json атрибуты.
- Commit a073: Добавлена поддержка команды
SELECT DATABASE(). Однако она всегда будет возвращатьManticore. Это дополнение имеет решающее значение для интеграций с различными инструментами MySQL. - Commit bc04: Изменен формат ответа эндпоинта /cli и добавлен эндпоинт
/cli_json, который будет функционировать как предыдущий/cli. - Commit d70b:
thread_stackтеперь можно изменять во время выполнения с помощью оператораSET. Доступны как локальные для сессии, так и глобальные для демона варианты. Текущие значения можно получить в выводеshow variables. - Commit d96e: Код был интегрирован в CBO для более точной оценки сложности выполнения фильтров по строковым атрибутам.
- Commit e77d: Расчет стоимости DocidIndex был улучшен, что повысило общую производительность.
- Commit f3ae: Метрики загрузки, аналогичные 'uptime' в Linux, теперь видны в команде
SHOW STATUS. - Commit f3cc: Порядок полей и атрибутов для
DESCиSHOW CREATE TABLEтеперь соответствует порядкуSELECT * FROM. - Commit f3d2: Разные внутренние парсеры теперь предоставляют свой внутренний мнемонический код (например,
P01) при различных ошибках. Это улучшение помогает определить, какой парсер вызвал ошибку, и также скрывает несущественные внутренние детали. - Issue #271 "Иногда CALL SUGGEST не предлагает исправление для опечатки в одну букву": Улучшено поведение SUGGEST/QSUGGEST для коротких слов: добавлена опция
sentence, чтобы показать целое предложение. - Issue #696 "Индекс перколяции не ищет правильно по запросу точной фразы, когда включено стеммирование": Запрос перколяции был изменен для обработки модификатора точного термина, улучшая функциональность поиска.
- Issue #829 "Методы форматирования даты": добавлено выражение списка выбора [date_format()](Functions/Date_and_time_functions.md#DATE_FORMAT()), которое открывает функцию
strftime(). - Issue #961 "Сортировка ведер через HTTP JSON API": введено необязательное свойство сортировки для каждого ведра агрегатов в HTTP-интерфейсе.
- Issue #1062 "Improve error logging of JSON insert api failure - "unsupported value type": Эндпоинт
/bulkсообщает информацию о количестве обработанных и необработанных строк (документов) в случае ошибки. - Issue #1070 "Подсказки CBO не поддерживают несколько атрибутов": Включены подсказки индекса для обработки нескольких атрибутов.
- Issue #1106 "Добавить теги к http поисковому запросу": Теги были добавлены к HTTP PQ ответам.
- Issue #1301 "buddy не должен создавать таблицу параллельно": Решена проблема, из-за которой происходили сбои при параллельных операциях CREATE TABLE. Теперь только одна операция
CREATE TABLEможет выполняться одновременно. - Issue #1303 "добавить поддержку @ в названиях столбцов".
- Issue #1316 "Запросы к набору данных такси медленные с ps=1": Логика CBO была уточнена, и разрешение по умолчанию для гистограммы было установлено на 8k для лучшей точности по атрибутам с случайно распределенными значениями.
- Issue #1317 "Исправить CBO против полнотекстового поиска на наборе данных hn": Улучшенная логика была реализована для определения, когда использовать пересечение итераторов битовых карт и когда использовать приоритетную очередь.
- Issue #1318 "колоночный: изменить интерфейс итератора на однократный вызов": Колонковые итераторы теперь используют один вызов
Get, заменяя предыдущие двухшаговые вызовыAdvanceTo+Getдля получения значения. - Issue #1319 "Ускорение расчета агрегатов (удалить CheckReplaceEntry?)": Вызов
CheckReplaceEntryбыл удален из группового сортировщика для ускорения расчета агрегатных функций. - Issue #1320 "создать таблицу read_buffer_docs/hits не понимает синтаксис k/m/g": Опции
CREATE TABLEread_buffer_docsиread_buffer_hitsтеперь поддерживают синтаксис k/m/g. - Языковые пакеты для английского, немецкого и русского языков теперь можно легко установить на Linux, выполнив команду
apt/yum install manticore-language-packs. На macOS используйте командуbrew install manticoresoftware/tap/manticore-language-packs. - Порядок полей и атрибутов теперь согласован между операциями
SHOW CREATE TABLEиDESC. - Если на диске недостаточно места при выполнении запросов
INSERT, новые запросыINSERTбудут завершаться неудачей, пока не станет доступно достаточно места на диске. - Функция преобразования типа UINT64() была добавлена.
- Эндпоинт
/bulkтеперь обрабатывает пустые строки как команду commit. Дополнительная информация здесь. - Предупреждения были реализованы для недействительных подсказок индекса, обеспечивая большую прозрачность и позволяя смягчить ошибки.
- Когда
count(*)используется с одним фильтром, запросы теперь используют предрассчитанные данные из вторичных индексов, когда это возможно, значительно ускоряя время выполнения запросов.
- ⚠️ Таблицы, созданные или измененные в версии 6.2.0, не могут быть прочитаны более старыми версиями.
- ⚠️ Идентификаторы документов теперь обрабатываются как беззнаковые 64-битные целые числа во время индексации и операций INSERT.
- ⚠️ Синтаксис для подсказок оптимизатора запросов был обновлен. Новый формат:
/*+ SecondaryIndex(uid) */. Обратите внимание, что старый синтаксис больше не поддерживается. - ⚠️ Проблема #1160: Использование
@в именах таблиц было запрещено для предотвращения конфликтов синтаксиса. - ⚠️ Строковые поля/атрибуты, помеченные как
indexedиattribute, теперь рассматриваются как одно поле во время операцийINSERT,DESCиALTER. - ⚠️ Проблема #1057: Библиотеки MCL больше не будут загружаться на системах, которые не поддерживают SSE 4.2.
- ⚠️ Проблема #1143: agent_query_timeout был сломан. Исправлено и теперь эффективно.
- Коммит 2a6e "Сбой при DROP TABLE": решена проблема, вызывавшая длительное ожидание завершения операций записи (оптимизация, сохранение дискового чанка) на RT таблице при выполнении оператора DROP TABLE. Добавлено предупреждение, чтобы уведомить, когда директория таблицы не пуста после выполнения команды DROP TABLE.
- Коммит 2ebd: Добавлена поддержка колоннарных атрибутов, которые отсутствовали в коде, используемом для группировки по нескольким атрибутам.
- Коммит 3be4 Исправлена проблема сбоя, потенциально вызванная нехваткой дискового пространства, путем правильной обработки ошибок записи в binlog.
- Коммит 6adb: Исправлен сбой, который иногда происходил при использовании нескольких колоннарных итераторов сканирования (или итераторов вторичного индекса) в запросе.
- Коммит 6bd9: Фильтры не удалялись при использовании сортировщиков, которые используют предрассчитанные данные. Эта проблема была исправлена.
- Коммит 6d03: Код CBO был обновлен для предоставления лучших оценок для запросов, использующих фильтры по строковым атрибутам, выполняемым в нескольких потоках.
- Коммит 6dd3, Helm #56 "фатальный дамп сбоя в кластере Kubernetes": Исправлен дефектный bloom-фильтр для корневого объекта JSON; исправлен сбой демона из-за фильтрации по полю JSON.
- Коммит 6e1b Исправлен сбой демона, вызванный недействительным конфигом
manticore.json. - Коммит 6fbc Исправлен фильтр диапазона json для поддержки значений int64.
- Коммит 9c67 Файлы
.sphмогли быть поврежденыALTER. Исправлено. - Коммит 77cc: Добавлен общий ключ для репликации оператора замены, чтобы решить ошибку
pre_commit, возникающую при репликации замены с нескольких мастер-узлов. - Коммит 2884 решены проблемы с проверками bigint по функциям, таким как 'date_format()'.
- Коммит 9513: Итераторы больше не отображаются в SHOW META, когда сортировщики используют предрассчитанные данные.
- Коммит a2a7: Размер стека узла полнотекстового поиска был обновлен, чтобы предотвратить сбои при сложных полнотекстовых запросах.
- Коммит a062: Исправлена ошибка, вызывавшая сбой во время репликации обновлений с атрибутами JSON и строками.
- Коммит b3e6: Строковый сборщик был обновлен для использования 64-битных целых чисел, чтобы избежать сбоев при работе с большими наборами данных.
- Коммит c472: Устранен сбой, который происходил при подсчете уникальных значений по нескольким индексам.
- Коммит d073: Исправлена проблема, когда запросы по дисковым чанкам RT индексов могли выполняться в нескольких потоках, даже если
pseudo_shardingбыл отключен. - Коммит d205 Набор значений, возвращаемых командой
show index status, был изменен и теперь варьируется в зависимости от типа используемого индекса. - Коммит e9bc Исправлена ошибка HTTP при обработке массовых запросов и проблема, когда ошибка не возвращалась клиенту из сетевого цикла.
- Коммит f77c использование расширенного стека для PQ.
- Коммит fac2 Обновлен вывод ранжировщика экспорта для соответствия packedfactors().
- Коммит ff87: Исправлена проблема со строковым списком в фильтре журнала запросов SphinxQL.
- Проблема #589 "Определение кодировки, похоже, зависит от порядка кодов": Исправлено неправильное сопоставление кодировки для дубликатов.
- Проблема #811 "Сопоставление нескольких слов в формах слов мешает фразовому поиску с CJK знаками препинания между ключевыми словами": Исправлена позиция токена ngram в фразовом запросе с формами слов.
- Проблема #834 "Знак равенства в поисковом запросе нарушает запрос": Обеспечено экранирование точного символа и исправлено двойное точное расширение с помощью опции
expand_keywords. - Проблема #864 "конфликт исключений/стоп-слов"
- Проблема #910 "Сбой Manticore при вызове call snippets() с libstemmer_fr и index_exact_words": Устранены внутренние конфликты, вызывающие сбои при вызове
SNIPPETS(). - Проблема #946 "Дублирующиеся записи во время SELECT": Исправлена проблема дублирующихся документов в наборе результатов для запроса с опцией
not_terms_only_allowedк RT индексу с убитыми документами. - Проблема #967 "Использование JSON аргументов в UDF функциях приводит к сбою": Исправлен сбой демона при обработке поиска с включенным псевдо-шардингом и UDF с аргументом JSON.
- Проблема #1050 "count(*) в FEDERATED": Исправлен сбой демона, возникающий при запросе через движок
FEDERATEDс агрегатом. - Проблема #1052 Исправлена проблема, когда столбец
rt_attr_jsonбыл несовместим с колоннарным хранилищем. - Проблема #1072 "* удаляется из поискового запроса с ignore_chars": Исправлена эта проблема, чтобы подстановочные знаки в запросе не затрагивались
ignore_chars. - Проблема #1075 "indextool --check не работает, если есть распределенная таблица": indextool теперь совместим с экземплярами, имеющими 'distributed' и 'template' индексы в json конфиге.
- Проблема #1081 "особый select на особом RT наборе данных приводит к сбою searchd": Устранен сбой демона при запросе с packedfactors и большим внутренним буфером.
- Проблема #1095 "С удаленными документами игнорируются not_terms_only_allowed"
- Проблема #1099 "indextool --dumpdocids не работает": Восстановлена функциональность команды
--dumpdocids. - Проблема #1100 "indextool --buildidf не работает": indextool теперь закрывает файл после завершения globalidf.
- Проблема #1104 "Count(*) пытается обрабатываться как схема, установленная в удаленных таблицах": Исправлена проблема, когда сообщение об ошибке отправлялось демоном для запросов в распределенный индекс, когда агент возвращал пустой набор результатов.
- Проблема #1109 "FLUSH ATTRIBUTES зависает с threads=1".
- Проблема #1126 "Потеряно соединение с сервером MySQL во время запроса - manticore 6.0.5": Устранены сбои, которые происходили при использовании нескольких фильтров по колоннарным атрибутам.
- Проблема #1135 "Чувствительность к регистру фильтрации строк JSON": Исправлена сортировка для правильной работы фильтров, используемых в HTTP поисковых запросах.
- Проблема #1140 "Совпадение в неправильном поле": Исправлены повреждения, связанные с
morphology_skip_fields. - Проблема #1155 "системные удаленные команды через API должны передавать g_iMaxPacketSize": Внесены обновления для обхода проверки
max_packet_sizeдля команд репликации между узлами. Кроме того, последняя ошибка кластера была добавлена в отображение статуса. - Проблема #1302 "временные файлы остаются после неудачной оптимизации": Исправлена проблема, когда временные файлы оставались после ошибки, произошедшей во время процесса слияния или оптимизации.
- Проблема #1304 "добавить переменную окружения для времени ожидания запуска buddy": Добавлена переменная окружения
MANTICORE_BUDDY_TIMEOUT(по умолчанию 3 секунды) для управления временем ожидания демона для сообщения buddy при запуске. - Проблема #1305 "Переполнение целого числа при сохранении метаданных PQ": Уменьшено чрезмерное потребление памяти демоном при сохранении большого индекса PQ.
- Проблема #1306 "Невозможно воссоздать RT таблицу после изменения ее внешнего файла": Исправлена ошибка изменения с пустой строкой для внешних файлов; исправлены внешние файлы RT индекса, оставшиеся после изменения внешних файлов.
- Проблема #1307 "Запрос SELECT sum(value) as value не работает должным образом": Исправлена проблема, когда выражение списка выбора с псевдонимом могло скрыть атрибут индекса; также исправлен суммирование для подсчета в int64 для целого числа.
- Проблема #1308 "Избегать привязки к localhost в репликации": Обеспечено, чтобы репликация не привязывалась к localhost для имен хостов с несколькими IP.
- Проблема #1309 "ответ клиенту mysql не удался для данных больше 16Mb": Исправлена проблема возврата пакета SphinxQL размером более 16Mb клиенту.
- Проблема #1310 "неправильная ссылка в "пути к внешним файлам должны быть абсолютными": Исправлено отображение полного пути к внешним файлам в
SHOW CREATE TABLE. - Проблема #1311 "сборка отладки сбоит на длинных строках в фрагментах": Теперь длинные строки (>255 символов) разрешены в тексте, на который нацелена функция
SNIPPET(). - Проблема #1312 "случайный сбой при использовании после удаления в опросе kqueue (master-agent)": Исправлены сбои, когда мастер не может подключиться к агенту на системах с управлением kqueue (FreeBSD, MacOS и т.д.).
- Проблема #1313 "слишком долгое соединение с самим собой": При подключении от мастера к агентам на MacOS/BSD теперь используется единый тайм-аут соединения+запроса вместо простого соединения.
- Проблема #1314 "pq (json meta) с недостижимыми встроенными синонимами не загружается": Исправлен флаг встроенных синонимов в pq.
- Проблема #1315 "Разрешить некоторым функциям (sint, fibonacci, second, minute, hour, day, month, year, yearmonth, yearmonthday) использовать неявно продвигаемые значения аргументов".
- Проблема #1321 "Включить многопоточную SI в полном сканировании, но ограничить потоки": Код был реализован в CBO для лучшего прогнозирования многопоточной производительности вторичных индексов, когда они используются в полнотекстовом запросе.
- Проблема #1322 "запросы count(*) все еще медленные после использования предрассчитанных сортировщиков": Итераторы больше не инициализируются при использовании сортировщиков, которые используют предрассчитанные данные, что позволяет избежать негативных эффектов производительности.
- Проблема #1411 "журнал запросов в sphinxql не сохраняет оригинальные запросы для MVA": Теперь
all()/any()записывается в журнал.
Выпущено: 15 марта 2023
- Улучшенная интеграция с Logstash, Beats и т.д., включая:
- Поддержка версий Logstash 7.6 - 7.15, версий Filebeat 7.7 - 7.12
- Поддержка авто-схемы.
- Добавлена обработка массовых запросов в формате, похожем на Elasticsearch.
- Коммит Buddy ce90 Версия Log Buddy при запуске Manticore.
- Проблема #588, Проблема #942 Исправлен неправильный символ в метаданных поиска и ключевых словах для биграммного индекса.
- Проблема #1027 Заголовки HTTP в нижнем регистре отклоняются.
- ❗Проблема #1039 Исправлена утечка памяти в демоне при чтении вывода консоли Buddy.
- Проблема #1056 Исправлено неожиданное поведение вопросительного знака.
- Проблема #1064 - Исправлено состояние гонки в таблицах токенизатора в нижнем регистре, вызывающее сбой.
- Коммит 59bb Исправлена обработка массовых записей в JSON-интерфейсе для документов с явно установленным id в null.
- Коммит 7b6b Исправлена статистика терминов в CALL KEYWORDS для нескольких одинаковых терминов.
- Коммит f381 Конфигурация по умолчанию теперь создается установщиком Windows; пути больше не заменяются во время выполнения.
- Коммит 6940, Коммит cc5a Исправлены проблемы с репликацией для кластера с узлами в нескольких сетях.
- Коммит 4972 Исправлен HTTP-эндпоинт
/pq, чтобы он был псевдонимом для HTTP-эндпоинта/json/pq. - Коммит 3b53 Исправлен сбой демона при перезапуске Buddy.
- Коммит Buddy fba9 Отображение оригинальной ошибки при получении недействительного запроса.
- Коммит Buddy db95 Разрешены пробелы в пути резервного копирования и добавлена магия к regexp для поддержки одинарных кавычек.
Выпущено: 10 февраля 2023
- Проблема #1024 сбой 2 Сбой / Ошибка сегментации при поиске по фасетам с большим количеством результатов
- ❗Проблема #1029 - ПРЕДУПРЕЖДЕНИЕ: Скомпилированное значение KNOWN_CREATE_SIZE (16) меньше измеренного (208). Рассмотрите возможность исправления значения!
- ❗Проблема #1032 - Простой индекс Manticore 6.0.0 вызывает сбой
- ❗Проблема #1033 - множественные распределенные теряются при перезапуске демона
- ❗Проблема #1064 - состояние гонки в таблицах токенизатора в нижнем регистре
Выпущено: 7 февраля 2023
Начиная с этого выпуска, Manticore Search поставляется с Manticore Buddy, демоном-сайдкаром, написанным на PHP, который обрабатывает высокоуровневую функциональность, не требующую супернизкой задержки или высокой пропускной способности. Manticore Buddy работает за кулисами, и вы можете даже не осознавать, что он работает. Хотя он невидим для конечного пользователя, это была значительная задача сделать Manticore Buddy легко устанавливаемым и совместимым с основным демоном на C++. Это главное изменение позволит команде разрабатывать широкий спектр новых высокоуровневых функций, таких как оркестрация шардов, контроль доступа и аутентификация, а также различные интеграции, такие как mysqldump, DBeaver, Grafana mysql connector. На данный момент он уже обрабатывает SHOW QUERIES, BACKUP и Авто-схему.
Этот выпуск также включает более 130 исправлений ошибок и множество функций, многие из которых можно считать основными.
- 🔬 Экспериментально: теперь вы можете выполнять совместимые с Elasticsearch вставки и замены JSON-запросов, что позволяет использовать Manticore с такими инструментами, как Logstash (версия < 7.13), Filebeat и другими инструментами из семейства Beats. Включено по умолчанию. Вы можете отключить это, используя
SET GLOBAL ES_COMPAT=off. - Поддержка Manticore Columnar Library 2.0.0 с многочисленными исправлениями и улучшениями в вторичных индексах. ⚠️ СУЩЕСТВЕННОЕ ИЗМЕНЕНИЕ: Вторичные индексы включены по умолчанию с этой версии. Убедитесь, что вы выполняете ALTER TABLE table_name REBUILD SECONDARY, если вы обновляетесь с Manticore 5. См. ниже для получения дополнительных сведений.
- Коммит c436 Авто-схема: теперь вы можете пропустить создание таблицы, просто вставив первый документ, и Manticore автоматически создаст таблицу на основе его полей. Читайте об этом более подробно здесь. Вы можете включить или отключить это, используя searchd.auto_schema.
- Огромная переработка оптимизатора на основе стоимости, который снижает время отклика запросов во многих случаях.
- Проблема #1008 Оценка производительности параллелизации в CBO.
- Проблема #1014 CBO теперь учитывает вторичные индексы и может действовать более разумно.
- Коммит cef9 Статистика кодирования колоннарных таблиц/полей теперь хранится в метаданных, чтобы помочь CBO принимать более разумные решения.
- Коммит 2b95 Добавлены подсказки CBO для тонкой настройки его поведения.
- Телеметрия: мы рады объявить о добавлении телеметрии в этом релизе. Эта функция позволяет нам собирать анонимные и деперсонализированные метрики, которые помогут нам улучшить производительность и пользовательский опыт нашего продукта. Будьте уверены, все собранные данные абсолютно анонимны и не будут связаны с какой-либо личной информацией. Эта функция может быть легко отключена в настройках, если это необходимо.
- Коммит 5aaf ALTER TABLE table_name REBUILD SECONDARY для перестройки вторичных индексов, когда вам это нужно, например:
- когда вы мигрируете с Manticore 5 на более новую версию,
- когда вы выполнили UPDATE (т.е. обновление на месте, а не замена) атрибута в индексе
- Проблема #821 Новый инструмент
manticore-backupдля резервного копирования и восстановления экземпляра Manticore - SQL команда BACKUP для выполнения резервного копирования изнутри Manticore.
- SQL команда SHOW QUERIES как простой способ увидеть выполняющиеся запросы, а не потоки.
- Проблема #551 SQL команда
KILLдля завершения длительногоSELECT. - Динамический
max_matchesдля агрегирующих запросов для повышения точности и снижения времени отклика.
-
Проблема #822 SQL команды FREEZE/UNFREEZE для подготовки реального/обычного таблицы к резервному копированию.
-
Коммит c470 Новые настройки
accurate_aggregationиmax_matches_increase_thresholdдля контролируемой точности агрегации. -
Проблема #718 Поддержка подписанных отрицательных 64-битных идентификаторов. Обратите внимание, что вы все еще не можете использовать идентификаторы > 2^63, но теперь вы можете использовать идентификаторы в диапазоне от -2^63 до 0.
-
Поскольку мы недавно добавили поддержку вторичных индексов, ситуация стала запутанной, так как "индекс" может относиться к вторичному индексу, полнотекстовому индексу или обычному/реальному
индексу. Чтобы уменьшить путаницу, мы переименовываем последний в "таблицу". Следующие SQL/командные строки подвержены этому изменению. Их старые версии устарели, но все еще функциональны:index <table name>=>table <table name>,searchd -i / --index=>searchd -t / --table,SHOW INDEX STATUS=>SHOW TABLE STATUS,SHOW INDEX SETTINGS=>SHOW TABLE SETTINGS,FLUSH RTINDEX=>FLUSH TABLE,OPTIMIZE INDEX=>OPTIMIZE TABLE,ATTACH TABLE plain TO RTINDEX rt=>ATTACH TABLE plain TO TABLE rt,RELOAD INDEX=>RELOAD TABLE,RELOAD INDEXES=>RELOAD TABLES.
Мы не планируем делать старые формы устаревшими, но для обеспечения совместимости с документацией мы рекомендуем изменить названия в вашем приложении. Что будет изменено в будущем релизе, так это переименование "index" в "table" в выводе различных SQL и JSON команд.
-
Запросы с состоянием UDF теперь вынуждены выполняться в одном потоке.
-
Проблема #1011 Рефакторинг всего, что связано с планированием времени, как предварительное условие для параллельного объединения чанков.
-
⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: Формат хранения столбцов был изменен. Вам нужно перестроить те таблицы, которые имеют столбцовые атрибуты.
-
⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: Формат файла вторичных индексов был изменен, поэтому если вы используете вторичные индексы для поиска и у вас в конфигурационном файле указано
searchd.secondary_indexes = 1, имейте в виду, что новая версия Manticore пропустит загрузку таблиц, которые имеют вторичные индексы. Рекомендуется:- Перед обновлением измените
searchd.secondary_indexesна 0 в конфигурационном файле. - Запустите экземпляр. Manticore загрузит таблицы с предупреждением.
- Выполните
ALTER TABLE <имя таблицы> REBUILD SECONDARYдля каждого индекса, чтобы перестроить вторичные индексы.
Если вы запускаете кластер репликации, вам нужно будет выполнить
ALTER TABLE <имя таблицы> REBUILD SECONDARYна всех узлах или следовать этой инструкции с единственным изменением: выполнитеALTER .. REBUILD SECONDARYвместоOPTIMIZE. - Перед обновлением измените
-
⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: Версия binlog была обновлена, поэтому любые binlog из предыдущих версий не будут воспроизведены. Важно убедиться, что Manticore Search остановлен корректно в процессе обновления. Это означает, что в
/var/lib/manticore/binlog/не должно быть файлов binlog, кромеbinlog.meta, после остановки предыдущего экземпляра. -
Проблема #849
SHOW SETTINGS: теперь вы можете видеть настройки из конфигурационного файла изнутри Manticore. -
Проблема #1007 SET GLOBAL CPUSTATS=1/0 включает/выключает отслеживание времени процессора; SHOW THREADS теперь не показывает статистику CPU, когда отслеживание времени процессора выключено.
-
Проблема #1009 Сегменты RAM чанков RT таблицы теперь могут быть объединены во время сброса RAM чанка.
-
Проблема #1012 Добавлен прогресс вторичного индекса в вывод indexer.
-
Проблема #1013 Ранее запись таблицы могла быть удалена Manticore из списка индексов, если она не могла начать обслуживать ее при запуске. Новое поведение заключается в том, чтобы оставить ее в списке, чтобы попытаться загрузить ее при следующем запуске.
-
indextool --docextract возвращает все слова и попадания, принадлежащие запрашиваемому документу.
-
Коммит 2b29 Переменная окружения
dump_corrupt_metaвключает дамп поврежденных метаданных таблицы в журнал в случае, если searchd не может загрузить индекс. -
Коммит c7a3
DEBUG METAможет показатьmax_matchesи статистику псевдо-шардинга. -
Коммит 6bca Лучше ошибка вместо запутанного "Формат заголовка индекса не json, попробую как бинарный...".
-
Коммит bef3 Путь украинского лемматизатора был изменен.
-
Коммит 4ae7 Статистика вторичных индексов была добавлена в SHOW META.
-
Коммит 2e7c JSON интерфейс теперь можно легко визуализировать с помощью Swagger Editor https://manual.manticoresearch.com/Openapi#OpenAPI-specification.
-
⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: Протокол репликации был изменен. Если вы запускаете кластер репликации, то при обновлении до Manticore 5 вам нужно:
- сначала корректно остановить все ваши узлы
- а затем запустить узел, который был остановлен последним с
--new-cluster(запустите инструментmanticore_new_clusterв Linux). - прочитайте о перезапуске кластера для получения дополнительных деталей.
- Рефакторинг интеграции вторичных индексов с колонковым хранилищем.
- Коммит efe2 Оптимизация библиотеки Manticore Columnar, которая может снизить время отклика за счет частической предварительной оценки min/max.
- Коммит 2757 Если слияние дисковых чанков прерывается, демон теперь очищает временные файлы, связанные с MCL.
- Коммит e9c6 Версии колонковых и вторичных библиотек записываются в журнал при сбое.
- Коммит f5e8 Добавлена поддержка быстрого перематывания списка документов для вторичных индексов.
- Коммит 06df Запросы, такие как
select attr, count(*) from plain_index(без фильтрации), теперь быстрее, если вы используете MCL. - Коммит 0a76 @@autocommit в HandleMysqlSelectSysvar для совместимости с .net коннектором для mysql версии выше 8.25
- ⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: MCL Проблема #17 MCL: добавлен код SSE для колонкового сканирования. MCL теперь требует как минимум SSE4.2.
- Коммит 4d19 ⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: Поддержка Debian Stretch и Ubuntu Xenial прекращена.
- Поддержка RHEL 9, включая Centos 9, Alma Linux 9 и Oracle Linux 9.
- Проблема #924 Поддержка Debian Bookworm.
- Проблема #636 Упаковка: сборки arm64 для Linux и MacOS.
- PR #26 Многоархитектурный (x86_64 / arm64) образ docker.
- Упрощенная сборка пакетов для участников.
- Теперь возможно установить конкретную версию с помощью APT.
- Коммит a6b8 Установщик для Windows (ранее мы предоставляли только архив).
- Переключились на компиляцию с использованием CLang 15.
- ⚠️ СЛОМАННОЕ ИЗМЕНЕНИЕ: Пользовательские формулы Homebrew, включая формулу для библиотеки Manticore Columnar. Чтобы установить Manticore, MCL и любые другие необходимые компоненты, используйте следующую команду
brew install manticoresoftware/manticore/manticoresearch manticoresoftware/manticore/manticore-extra.
- Проблема #479 Поле с именем
text - Проблема #501 id не может быть не bigint
- Проблема #646 ALTER против поля с именем "text"
- ❗Проблема #652 Возможная ОШИБКА: HTTP (JSON) смещение и лимит влияют на результаты фасетов
- ❗Проблема #827 Searchd зависает/выходит из строя при интенсивной загрузке
- ❗Проблема #996 PQ индекс исчерпал память
- ❗Коммит 1041
binlog_flush = 1был сломан все время с Sphinx. Исправлено. - MCL Проблема #14 MCL: сбой при выборе, когда слишком много полей ft
- Проблема #470 sql_joined_field не может быть сохранен
- Проблема #713 Сбой при использовании LEVENSHTEIN()
- Проблема #743 Manticore неожиданно вылетает и не может нормально перезапуститься
- Проблема #788 CALL KEYWORDS через /sql возвращает управляющий символ, который ломает json
- Проблема #789 mariadb не может создать таблицу FEDERATED
- Проблема #796 ПРЕДУПРЕЖДЕНИЕ: dlopen() не удалось: /usr/bin/lib_manticore_columnar.so: не удается открыть общий объект: Нет такого файла или каталога
- Проблема #797 Manticore вылетает, когда поиск с ZONESPAN выполняется через api
- Проблема #799 неправильный вес при использовании нескольких индексов и уникальных фасетов
- Проблема #801 Запрос группы SphinxQL зависает после повторной обработки SQL индекса
- Проблема #802 MCL: Индексатор вылетает в 5.0.2 и manticore-columnar-lib 1.15.4
- Проблема #813 Manticore 5.0.2 FEDERATED возвращает пустое множество (MySQL 8.0.28)
- Проблема #824 выбор COUNT DISTINCT на 2 индексах, когда результат равен нулю, вызывает внутреннюю ошибку
- Проблема #826 СБОЙ на запросе удаления
- Проблема #843 MCL: Ошибка с длинным текстовым полем
- Проблема #856 5.0.2 rtindex: Поведение лимита агрегатного поиска не соответствует ожиданиям
- Проблема #863 Возвращаемые результаты имеют тип Nonetype, даже для запросов, которые должны возвращать несколько результатов
- Проблема #870 Сбой при использовании атрибута и сохраненного поля в выражении SELECT
- Проблема #872 таблица становится невидимой после сбоя
- Проблема #877 Два отрицательных термина в запросе поиска дают ошибку: запрос не вычисляемый
- Проблема #878 a -b -c не работает через json query_string
- Проблема #886 псевдо_шардинг с совпадением запроса
- Проблема #893 Manticore 5.0.2 функция min/max не работает как ожидалось ...
- Проблема #896 Поле "weight" не разбирается правильно
- Проблема #897 Сервис Manticore вылетает при запуске и продолжает перезапускаться
- Проблема #900 группировка по j.a, что-то работает неправильно
- Проблема #913 Сбой Searchd, когда expr используется в ранжировании, но только для запросов с двумя близостями
- Проблема #916 net_throttle_action сломан
- Проблема #919 MCL: Manticore вылетает при выполнении запроса, и другие вылетают во время восстановления кластера.
- Проблема #925 SHOW CREATE TABLE выводит без обратных кавычек
- Проблема #930 Теперь можно запрашивать Manticore из Java через JDBC коннектор
- Проблема #933 проблемы с ранжированием bm25f
- Проблема #934 индексы без конфигурации зависают в watchdog в состоянии первой загрузки
- Проблема #937 Segfault при сортировке данных фасета
- Проблема #940 сбой на CONCAT(TO_STRING)
- Проблема #947 В некоторых случаях один простой выбор может вызвать зависание всего экземпляра, так что вы не могли войти в него или выполнить любой другой запрос, пока выполняется текущий выбор.
- Проблема #948 Сбой индексатора
- Проблема #950 неправильный подсчет из уникального фасета
- Проблема #953 LCS рассчитывается неправильно в встроенном ранжировщике sph04
- Проблема #955 5.0.3 dev вылетает
- Проблема #963 FACET с json на движке columnar вызывает сбой
- Проблема #982 MCL: 5.0.3 сбой из-за вторичного индекса
- PR #984 @@autocommit в HandleMysqlSelectSysvar
- PR #985 Исправить распределение потоков в RT индексах
- Проблема #985 Исправить распределение потоков в RT индексах
- Проблема #986 неправильное значение по умолчанию max_query_time
- Проблема #987 Сбой при использовании регулярного выражения в многопоточном выполнении
- Проблема #988 Нарушена обратная совместимость индекса
- Проблема #989 indextool сообщает об ошибке при проверке атрибутов columnar
- Проблема #990 утечка памяти клонов json grouper
- Проблема #991 Утечка памяти клонирования функции levenshtein
- Проблема #992 Сообщение об ошибке потеряно при загрузке метаданных
- Проблема #993 Распространение ошибок от динамических индексов/подключей и системных переменных
- Проблема #994 Сбой при подсчете уникальных значений по строке в columnar хранилище
- Проблема #995 MCL: min(pickup_datetime) из taxi1 вызывает сбой
- Проблема #997 пустые исключения JSON запрос удаляет столбцы из списка выбора
- Проблема #998 Вторичные задачи, выполняемые на текущем планировщике, иногда вызывают аномальные побочные эффекты
- Проблема #999 сбой с уникальными фасетами и разными схемами
- Проблема #1000 MCL: Колонный rt индекс стал поврежденным после запуска без колонной библиотеки
- Проблема #1001 неявный обрезка не работает в json
- Проблема #1002 Проблема с колонным группировщиком
- Проблема #1003 Невозможно удалить последнее поле из индекса
- Проблема #1004 неправильное поведение после --new-cluster
- Проблема #1005 "колонная библиотека не загружена", но она не требуется
- Проблема #1006 нет ошибки для запроса удаления
- Проблема #1010 Исправлено местоположение файла данных ICU в сборках Windows
- PR #1018 Проблема с отправкой рукопожатия
- Проблема #1020 Отображение id в show create table
- Проблема #1024 crash 1 Сбой / Сегментация при поиске фасета с большим количеством результатов.
- Проблема #1026 RT индекс: searchd "зависает" навсегда, когда вставляется много документов и RAMchunk заполняется
- Коммит 4739 Поток зависает при завершении работы, пока репликация занята между узлами
- Коммит ab87 Смешивание чисел с плавающей запятой и целых в фильтре диапазона JSON может заставить Manticore игнорировать фильтр
- Коммит d001 Фильтры с плавающей запятой в JSON были неточными
- Коммит 4092 Отменить неподтвержденные транзакции, если индекс изменен (иначе может произойти сбой)
- Коммит 9692 Ошибка синтаксиса запроса при использовании обратной косой черты
- Коммит 0c19 workers_clients могут быть неверными в SHOW STATUS
- Коммит 1772 исправлен сбой при слиянии сегментов ram без docstores
- Коммит f45b Исправлено пропущенное условие ALL/ANY для фильтра JSON равенства
- Коммит 3e83 Репликация может завершиться неудачей с
got exception while reading ist stream: mkstemp(./gmb_pF6TJi) failed: 13 (Permission denied), если searchd был запущен из каталога, в который он не может записывать. - Коммит 92e5 С 4.0.2 журнал сбоев включал только смещения. Этот коммит это исправляет.
Выпущена: 30 мая 2022
- ❗Issue #791 - неправильный размер стека мог привести к сбою.
Выпущена: 18 мая 2022
-
🔬 Поддержка Manticore Columnar Library 1.15.2, которая включает бета-версию вторичных индексов. Построение вторичных индексов включено по умолчанию для колоночных и построчных индексов (как обычных, так и реального времени), если используется Manticore Columnar Library, но для их использования при поиске необходимо установить
secondary_indexes = 1либо в конфигурационном файле, либо с помощью SET GLOBAL. Новая функциональность поддерживается во всех операционных системах, кроме старых Debian Stretch и Ubuntu Xenial. -
Режим только для чтения: теперь можно указать слушателей, которые обрабатывают только запросы на чтение, игнорируя любые операции записи.
-
Новый эндпоинт /cli для ещё более простого выполнения SQL-запросов через HTTP.
-
Более быстрые массовые INSERT/REPLACE/DELETE через JSON по HTTP: ранее можно было передавать несколько команд записи через протокол HTTP JSON, но они обрабатывались по одной, теперь они обрабатываются как единая транзакция.
-
#720 Поддержка вложенных фильтров в протоколе JSON. Ранее нельзя было закодировать такие конструкции, как
a=1 and (b=2 or c=3)в JSON:must(И),should(ИЛИ) иmust_not(НЕ) работали только на верхнем уровне. Теперь их можно вкладывать. -
Поддержка Chunked transfer encoding в протоколе HTTP. Теперь вы можете использовать chunked transfer в своём приложении для передачи больших пакетов с уменьшенным потреблением ресурсов (поскольку вычисление
Content-Lengthне требуется). На стороне сервера Manticore теперь всегда обрабатывает входящие HTTP-данные в потоковом режиме, не дожидаясь передачи всего пакета, как раньше, что:- снижает пиковое использование оперативной памяти, уменьшая риск OOM
- уменьшает время отклика (наши тесты показали снижение на 11% при обработке пакета размером 100 МБ)
- позволяет обойти ограничение max_packet_size и передавать пакеты, значительно превышающие максимально допустимое значение
max_packet_size(128 МБ), например, 1 ГБ за раз.
-
#719 Поддержка
100 Continueв HTTP-интерфейсе: теперь можно передавать большие пакеты изcurl(включая библиотеки curl, используемые различными языками программирования), который по умолчанию отправляетExpect: 100-continueи ждёт некоторое время перед фактической отправкой пакета. Ранее приходилось добавлять заголовокExpect:, теперь в этом нет необходимости.MORE -
⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: Псевдошардирование включено по умолчанию. Если вы хотите отключить его, убедитесь, что добавили
pseudo_sharding = 0в разделsearchdвашего конфигурационного файла Manticore. -
Наличие хотя бы одного полнотекстового поля в индексе реального времени/обычном индексе больше не является обязательным. Теперь вы можете использовать Manticore даже в случаях, не связанных с полнотекстовым поиском.
-
Быстрая выборка для атрибутов, использующих Manticore Columnar Library: запросы вида
select * from <columnar table>теперь выполняются намного быстрее, чем раньше, особенно если в схеме много полей. -
⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: Неявный cutoff. Теперь Manticore не тратит время и ресурсы на обработку данных, которые вам не нужны в возвращаемом наборе результатов. Обратной стороной является то, что это влияет на
total_foundв SHOW META и наhits.totalв JSON-выводе. Теперь это значение точно только в случае, если вы видитеtotal_relation: eq, в то время какtotal_relation: gteозначает, что фактическое количество соответствующих документов больше, чем полученное значениеtotal_found. Чтобы сохранить прежнее поведение, можно использовать опцию поискаcutoff=0, которая делаетtotal_relationвсегда равнымeq. -
⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: Все полнотекстовые поля теперь по умолчанию хранятся. Чтобы сделать все поля нехранимыми (т.е. вернуться к прежнему поведению), необходимо использовать
stored_fields =(пустое значение). -
#715 HTTP JSON поддерживает опции поиска.
- ⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: Изменение формата метафайла индекса. Ранее метафайлы (
.meta,.sph) были в бинарном формате, теперь это просто json. Новая версия Manticore автоматически преобразует старые индексы, но:- вы можете получить предупреждение типа
WARNING: ... syntax error, unexpected TOK_IDENT - вы не сможете запустить индекс с предыдущими версиями Manticore, убедитесь, что у вас есть резервная копия
- вы можете получить предупреждение типа
- ⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: Поддержка состояния сессии с помощью HTTP keep-alive. Это делает HTTP сессионным, когда клиент тоже его поддерживает. Например, используя новый эндпоинт /cli и HTTP keep-alive (который включен по умолчанию во всех браузерах), вы можете вызвать
SHOW METAпослеSELECT, и это будет работать так же, как и через mysql. Обратите внимание, что ранее заголовок HTTPConnection: keep-aliveтоже поддерживался, но он только приводил к повторному использованию того же соединения. Начиная с этой версии он также делает сессию сессионной. - Теперь вы можете указать
columnar_attrs = *, чтобы определить все ваши атрибуты как колоночные в plain mode, что полезно, если список длинный. - Более быстрая репликация SST
- ⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: Протокол репликации был изменен. Если вы запускаете кластер репликации, то при обновлении до Manticore 5 вам необходимо:
- сначала корректно остановить все ваши узлы
- а затем запустить узел, который был остановлен последним, с параметром
--new-cluster(запустите инструментmanticore_new_clusterв Linux). - прочитайте о перезапуске кластера для получения более подробной информации.
- Улучшения репликации:
- Более быстрая SST
- Устойчивость к шуму, что может помочь в случае нестабильной сети между узлами репликации
- Улучшенное логирование
- Улучшение безопасности: Manticore теперь прослушивает
127.0.0.1вместо0.0.0.0в случае, если в конфигурации вообще не указанlisten. Хотя в конфигурации по умолчанию, которая поставляется с Manticore Search, параметрlistenуказан, и не типично иметь конфигурацию вообще безlisten, это все же возможно. Ранее Manticore прослушивал бы0.0.0.0, что небезопасно, теперь он прослушивает127.0.0.1, который обычно не доступен из Интернета. - Более быстрая агрегация по колоночным атрибутам.
- Повышена точность
AVG(): ранее Manticore использовалfloatвнутренне для агрегаций, теперь он используетdouble, что значительно повышает точность. - Улучшена поддержка драйвера JDBC MySQL.
- Поддержка
DEBUG malloc_statsдля jemalloc. - optimize_cutoff теперь доступен как настройка для каждой таблицы, которую можно установить при CREATE или ALTER таблицы.
- ⚠️ КРИТИЧЕСКОЕ ИЗМЕНЕНИЕ: query_log_format теперь по умолчанию
sphinxql. Если вы привыкли к форматуplain, вам нужно добавитьquery_log_format = plainв ваш конфигурационный файл. - Значительные улучшения потребления памяти: Manticore теперь потребляет значительно меньше оперативной памяти в случае длительной и интенсивной нагрузки на вставку/замену/оптимизацию, если используются хранимые поля.
- Значение по умолчанию для shutdown_timeout было увеличено с 3 секунд до 60 секунд.
- Коммит ffd0 Поддержка Java mysql connector >= 6.0.3: в Java mysql connection 6.0.3 они изменили способ подключения к mysql, что нарушило совместимость с Manticore. Новое поведение теперь поддерживается.
- Коммит 1da6 отключил сохранение нового дискового чанка при загрузке индекса (например, при запуске searchd).
- Issue #746 Поддержка glibc >= 2.34.
- Issue #784 подсчет 'VIP' соединений отдельно от обычных (не-VIP). Ранее VIP-соединения учитывались в лимите
max_connections, что могло вызывать ошибку "maxed out" для не-VIP соединений. Теперь VIP-соединения не учитываются в лимите. Текущее количество VIP-соединений также можно увидеть вSHOW STATUSиstatus. - ID теперь можно указывать явно.
- Issue #687 поддержка сжатия zstd для mysql proto
- ⚠️ Формула BM25F была немного обновлена для улучшения релевантности поиска. Это влияет только на результаты поиска в случае, если вы используете функцию BM25F(), это не изменяет поведение формулы ранжирования по умолчанию.
- ⚠️ Изменено поведение REST /sql конечной точки:
/sql?mode=rawтеперь требует экранирования и возвращает массив. - ⚠️ Изменение формата ответа на запросы
/bulkINSERT/REPLACE/DELETE:- ранее каждый подзапрос составлял отдельную транзакцию и приводил к отдельному ответу
- теперь весь пакет считается одной транзакцией, которая возвращает один ответ
- ⚠️ Параметры поиска
low_priorityиboolean_simplifyтеперь требуют значения (0/1): ранее вы могли делатьSELECT ... OPTION low_priority, boolean_simplify, теперь вам нужно делатьSELECT ... OPTION low_priority=1, boolean_simplify=1. - ⚠️ Если вы используете старые клиенты php, python или java, пожалуйста, перейдите по соответствующей ссылке и найдите обновленную версию. Старые версии не полностью совместимы с Manticore 5.
- ⚠️ HTTP JSON запросы теперь записываются в другом формате в режиме
query_log_format=sphinxql. Ранее записывалась только часть с полным текстом, теперь записывается как есть.
-
⚠️ СУЩЕСТВЕННОЕ ИЗМЕНЕНИЕ: из-за новой структуры при обновлении до Manticore 5 рекомендуется удалить старые пакеты перед установкой новых:
- Для RPM:
yum remove manticore* - Для Debian и Ubuntu:
apt remove manticore*
- Для RPM:
-
Новая структура deb/rpm пакетов. Предыдущие версии предоставляли:
manticore-serverсsearchd(основной демон поиска) и всем необходимым для негоmanticore-toolsсindexerиindextoolmanticore, включающий всеmanticore-allRPM как мета-пакет, ссылающийся наmanticore-serverиmanticore-tools
Новая структура:
manticore- мета-пакет deb/rpm, который устанавливает все вышеперечисленное как зависимостиmanticore-server-core-searchdи все, чтобы запустить его отдельноmanticore-server- файлы systemd и другие вспомогательные скриптыmanticore-tools-indexer,indextoolи другие инструментыmanticore-common- файл конфигурации по умолчанию, каталог данных по умолчанию, стоп-слова по умолчаниюmanticore-icudata,manticore-dev,manticore-converterне изменились сильно.tgzпакет, который включает все пакеты
-
Поддержка Ubuntu Jammy
-
Поддержка Amazon Linux 2 через YUM репозиторий
- Проблема #815 Случайный сбой при использовании функции UDF
- Проблема #287 недостаточно памяти при индексации RT индекса
- Проблема #604 Ломающее изменение 3.6.0, 4.2.0 sphinxql-parser
- Проблема #667 ФАТАЛЬНО: недостаточно памяти (невозможно выделить 9007199254740992 байт)
- Проблема #676 Строки не передаются правильно в UDF
- ❗Проблема #698 Searchd выдает сбой после попытки добавить текстовый столбец в rt индекс
- Проблема #705 Индексатор не смог найти все столбцы
- ❗Проблема #709 Группировка по json.boolean работает неправильно
- Проблема #716 Команды indextool, связанные с индексом (например, --dumpdict) не работают
- ❗Проблема #724 Поля исчезают из выбора
- Проблема #727 Несоответствие Content-Type HttpClient .NET при использовании
application/x-ndjson - Проблема #729 Расчет длины поля
- ❗Проблема #730 создание/вставка/удаление колонной таблицы вызывает утечку памяти
- Проблема #731 Пустой столбец в результатах при определенных условиях
- ❗Проблема #749 Сбой демона при запуске
- ❗Проблема #750 Демон зависает при запуске
- ❗Проблема #751 Сбой на SST
- Проблема #752 Атрибут Json помечен как колонный, когда engine='columnar'
- Проблема #753 Репликация слушает на 0
- Проблема #754 columnar_attrs = * не работает с csvpipe
- ❗Проблема #755 Сбой при выборе float в колонной в rt
- ❗Проблема #756 Indextool изменяет rt индекс во время проверки
- Проблема #757 Необходима проверка на пересечение диапазонов портов слушателей
- Проблема #758 Записать оригинальную ошибку в случае, если RT индекс не удалось сохранить на диск
- Проблема #759 Сообщается только одна ошибка для конфигурации RE2
- ❗Проблема #760 Изменения потребления ОЗУ в коммите 5463778558586d2508697fa82e71d657ac36510f
- Проблема #761 3-й узел не создает непервичный кластер после грязного перезапуска
- Проблема #762 Счетчик обновлений увеличивается на 2
- Проблема #763 Новая версия 4.2.1 повреждает индекс, созданный с 4.2.0 с использованием морфологии
- Проблема #764 Нет экранирования в ключах json /sql?mode=raw
- ❗Проблема #765 Использование функции скрывает другие значения
- ❗Проблема #766 Утечка памяти, вызванная строкой в FixupAttrForNetwork
- ❗Проблема #767 Утечка памяти в 4.2.0 и 4.2.1, связанная с кэшем docstore
- Проблема #768 Странный пинг-понг с сохраненными полями по сети
- Проблема #769 lemmatizer_base сбрасывается в пустое значение, если не упомянуто в разделе 'common'
- Проблема #770 pseudo_sharding делает SELECT по id медленнее
- Проблема #771 DEBUG malloc_stats выводит нули при использовании jemalloc
- Проблема #772 Удаление/добавление столбца делает значение невидимым
- Проблема #773 Невозможно добавить столбец bit(N) в колонную таблицу
- Проблема #774 "cluster" становится пустым при запуске в manticore.json
- ❗Коммит 1da4 HTTP действия не отслеживаются в SHOW STATUS
- Коммит 3810 отключить pseudo_sharding для запросов с низкой частотой по одному ключевому слову
- Коммит 8003 исправлено слияние сохраненных атрибутов и индекса
- Коммит cddf обобщены выборщики уникальных значений; добавлены специализированные выборщики уникальных значений для колонных строк
- Коммит fba4 исправлено извлечение нулевых целочисленных атрибутов из docstore
- Коммит f300
rankerможет быть указан дважды в журнале запросов
- Поддержка псевдо-шардирования для индексов в реальном времени и полнотекстовых запросов. В предыдущем релизе мы добавили ограниченную поддержку псевдо-шардирования. Начиная с этой версии, вы можете получить все преимущества псевдо-шардирования и вашего многоядерного процессора, просто включив searchd.pseudo_sharding. Самое крутое в этом то, что вам не нужно ничего делать с вашими индексами или запросами для этого, просто включите это, и если у вас есть свободный ЦП, он будет использован для снижения времени ответа. Это поддерживает обычные и индексы в реальном времени для полнотекстовых, фильтрационных и аналитических запросов. Например, вот как включение псевдо-шардирования может сделать время ответа большинства запросов в среднем примерно в 10 раз ниже на наборе данных курируемых комментариев Hacker news, умноженном на 100 (116 миллионов документов в обычном индексе).
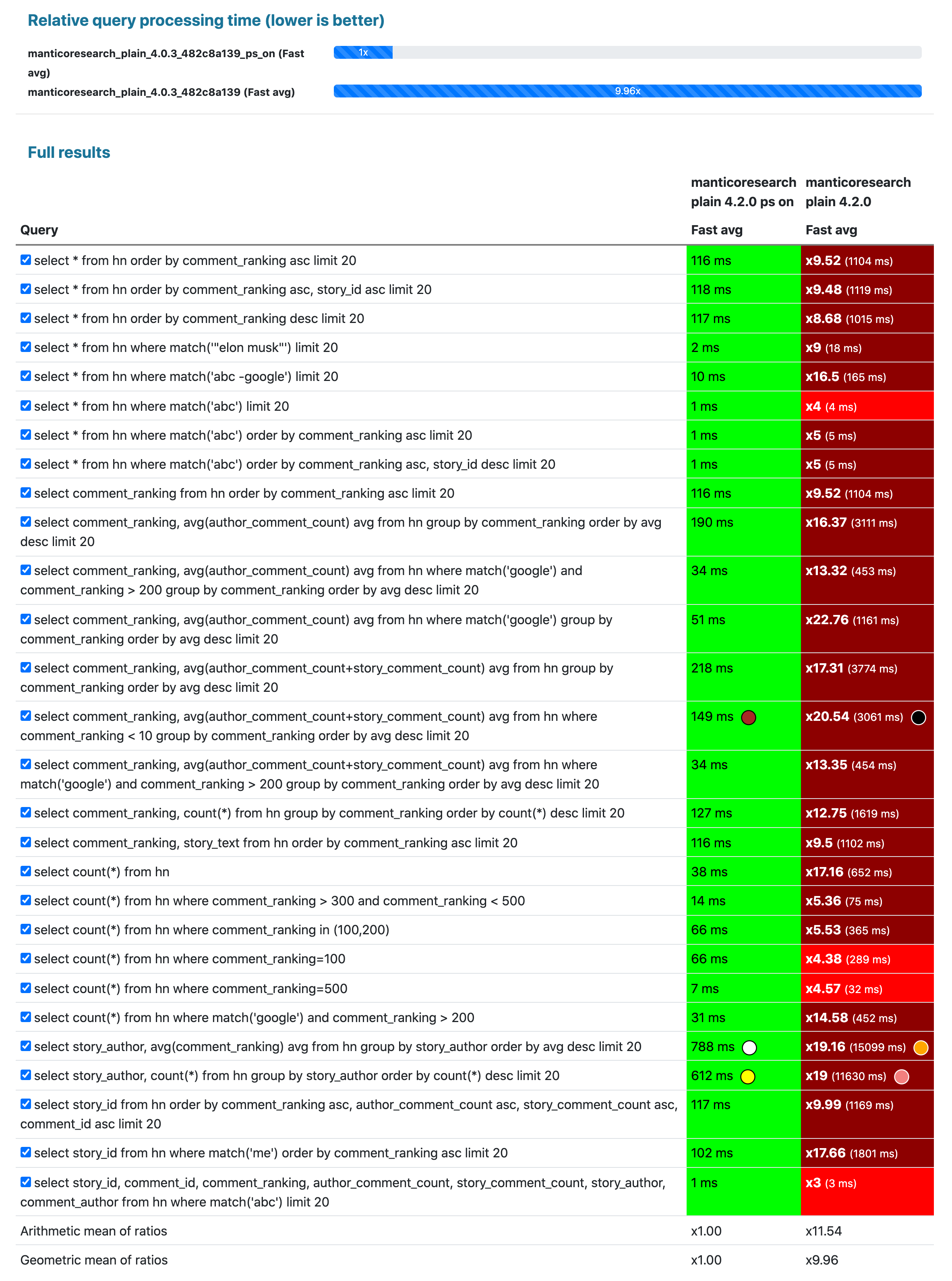
- Debian Bullseye теперь поддерживается.
- PQ транзакции теперь атомарны и изолированы. Ранее поддержка PQ транзакций была ограничена. Это позволяет значительно ускорить REPLACE в PQ, особенно когда вам нужно заменить много правил сразу. Подробности о производительности:
- 4.0.2
- 4.2.0
Вставка 1M PQ правил занимает 48 секунд и REPLACE всего 40K в 10K пакетах занимает 406 секунд.
root@perf3 ~ # mysql -P9306 -h0 -e "drop table if exists pq; create table pq (f text, f2 text, j json, s string) type='percolate';"; date; for m in `seq 1 1000`; do (echo -n "insert into pq (id,query,filters,tags) values "; for n in `seq 1 1000`; do echo -n "(0,'@f (cat | ( angry dog ) | (cute mouse)) @f2 def', 'j.json.language=\"en\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; [ $n != 1000 ] && echo -n ","; done; echo ";")|mysql -P9306 -h0; done; date; mysql -P9306 -h0 -e "select count(*) from pq"
Wed Dec 22 10:24:30 AM CET 2021
Wed Dec 22 10:25:18 AM CET 2021
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
root@perf3 ~ # date; (echo "begin;"; for offset in `seq 0 10000 30000`; do n=0; echo "replace into pq (id,query,filters,tags) values "; for id in `mysql -P9306 -h0 -NB -e "select id from pq limit $offset, 10000 option max_matches=1000000"`; do echo "($id,'@f (tiger | ( angry bear ) | (cute panda)) @f2 def', 'j.json.language=\"de\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; n=$((n+1)); [ $n != 10000 ] && echo -n ","; done; echo ";"; done; echo "commit;") > /tmp/replace.sql; date
Wed Dec 22 10:26:23 AM CET 2021
Wed Dec 22 10:26:27 AM CET 2021
root@perf3 ~ # time mysql -P9306 -h0 < /tmp/replace.sql
real 6m46.195s
user 0m0.035s
sys 0m0.008sВставка 1M PQ правил занимает 34 секунды и REPLACE их в 10K пакетах занимает 23 секунды.
root@perf3 ~ # mysql -P9306 -h0 -e "drop table if exists pq; create table pq (f text, f2 text, j json, s string) type='percolate';"; date; for m in `seq 1 1000`; do (echo -n "insert into pq (id,query,filters,tags) values "; for n in `seq 1 1000`; do echo -n "(0,'@f (cat | ( angry dog ) | (cute mouse)) @f2 def', 'j.json.language=\"en\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; [ $n != 1000 ] && echo -n ","; done; echo ";")|mysql -P9306 -h0; done; date; mysql -P9306 -h0 -e "select count(*) from pq"
Wed Dec 22 10:06:38 AM CET 2021
Wed Dec 22 10:07:12 AM CET 2021
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
root@perf3 ~ # date; (echo "begin;"; for offset in `seq 0 10000 990000`; do n=0; echo "replace into pq (id,query,filters,tags) values "; for id in `mysql -P9306 -h0 -NB -e "select id from pq limit $offset, 10000 option max_matches=1000000"`; do echo "($id,'@f (tiger | ( angry bear ) | (cute panda)) @f2 def', 'j.json.language=\"de\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; n=$((n+1)); [ $n != 10000 ] && echo -n ","; done; echo ";"; done; echo "commit;") > /tmp/replace.sql; date
Wed Dec 22 10:12:31 AM CET 2021
Wed Dec 22 10:14:00 AM CET 2021
root@perf3 ~ # time mysql -P9306 -h0 < /tmp/replace.sql
real 0m23.248s
user 0m0.891s
sys 0m0.047s- optimize_cutoff теперь доступен как параметр конфигурации в разделе
searchd. Это полезно, когда вы хотите ограничить количество RT чанков во всех ваших индексах до определенного числа глобально. - Commit 0087 точный count(distinct ...) и FACET ... distinct по нескольким локальным физическим индексам (реального времени/обычным) с идентичными полями и порядком.
- PR #598 поддержка bigint для
YEAR()и других функций временных меток. - Commit 8e85 Адаптивный rt_mem_limit. Ранее Manticore Search собирал ровно до
rt_mem_limitданных перед сохранением нового дискового чанка на диск, и во время сохранения все еще собирал до 10% больше (так называемый двойной буфер), чтобы минимизировать возможные задержки вставки. Если этот лимит также исчерпывался, добавление новых документов блокировалось до полного сохранения дискового чанка на диск. Новый адаптивный лимит основан на том факте, что у нас теперь есть auto-optimize, так что это не большая проблема, если дисковые чанки не полностью соблюдаютrt_mem_limitи начинают сбрасывать дисковый чанк раньше. Теперь мы собираем до 50%rt_mem_limitи сохраняем это как дисковый чанк. При сохранении мы смотрим на статистику (сколько мы сохранили, сколько новых документов поступило во время сохранения) и пересчитываем начальную скорость, которая будет использоваться в следующий раз. Например, если мы сохранили 90 миллионов документов, и еще 10 миллионов документов поступило во время сохранения, скорость составляет 90%, так что мы знаем, что в следующий раз мы можем собрать до 90%rt_mem_limitперед началом сброса другого дискового чанка. Значение скорости рассчитывается автоматически от 33.3% до 95%. - Issue #628 unpack_zlib для источника PostgreSQL. Спасибо, Дмитрий Воронин за вклад.
- Commit 6d54
indexer -vи--version. Ранее вы все еще могли видеть версию индексатора, но-v/--versionне поддерживались. - Issue #662 бесконечный лимит mlock по умолчанию, когда Manticore запускается через systemd.
- Commit 63c8 spinlock -> op queue для coro rwlock.
- Commit 4113 переменная окружения
MANTICORE_TRACK_RT_ERRORS, полезная для отладки повреждений сегментов RT.
- Версия Binlog была увеличена, binlog из предыдущей версии не будет воспроизведен, поэтому убедитесь, что вы останавливаете Manticore Search корректно во время обновления: никаких файлов binlog не должно быть в
/var/lib/manticore/binlog/, кромеbinlog.metaпосле остановки предыдущего экземпляра. - Commit 3f65 новый столбец "chain" в
show threads option format=all. Он показывает стек некоторых информационных билетов задач, наиболее полезен для профилирования, так что если вы парсите выводshow threads, будьте внимательны к новому столбцу. searchd.workersбыл устаревшим с версии 3.5.0, теперь он считается устаревшим, если вы все еще имеете его в вашем конфигурационном файле, это вызовет предупреждение при запуске. Manticore Search запустится, но с предупреждением.- Если вы используете PHP и PDO для доступа к Manticore, вам нужно установить
PDO::ATTR_EMULATE_PREPARES
- ❗Проблема #650 Manticore 4.0.2 медленнее, чем Manticore 3.6.3. 4.0.2 был быстрее, чем предыдущие версии по скорости массовых вставок, но значительно медленнее для вставок одного документа. Это было исправлено в 4.2.0.
- ❗Коммит 22f4 Индекс RT мог быть поврежден под интенсивной нагрузкой REPLACE, или он мог аварийно завершиться
- Коммит 03be исправлено среднее значение при объединении группировщиков и сортировщика группы N; исправлено объединение агрегатов
- Коммит 2ea5
indextool --checkмог аварийно завершиться - Коммит 7ec7 Проблема исчерпания ОЗУ, вызванная UPDATE
- Коммит 658a демон мог зависнуть при INSERT
- Коммит 46e4 демон мог зависнуть при завершении работы
- Коммит f8d7 демон мог аварийно завершиться при завершении работы
- Коммит 733a демон мог зависнуть при аварийном завершении
- Коммит f7f8 демон мог аварийно завершиться при запуске, пытаясь повторно присоединиться к кластеру с недействительным списком узлов
- Коммит 1401 распределенный индекс мог быть полностью забыт в режиме RT, если он не мог разрешить одного из своих агентов при запуске
- Проблема #683 атрибут bit(N) engine='columnar' не работает
- Проблема #682 создание таблицы не удалось, но оставляет директорию
- Проблема #663 Конфигурация не работает с: неизвестное имя ключа 'attr_update_reserve'
- Проблема #632 Manticore аварийно завершился при пакетных запросах
- Проблема #679 Пакетные запросы снова вызывают аварии с v4.0.3
- Коммит f7f8 исправлено аварийное завершение демона при запуске, пытаясь повторно присоединиться к кластеру с недействительным списком узлов
- Проблема #643 Manticore 4.0.2 не принимает соединения после пакета вставок
- Проблема #635 Запрос FACET с ORDER BY JSON.field или строковым атрибутом мог аварийно завершиться
- Проблема #634 Авария SIGSEGV при запросе с packedfactors
- Коммит 4165 morphology_skip_fields не поддерживался при создании таблицы
-
Полная поддержка Manticore Columnar Library. Ранее Manticore Columnar Library поддерживалась только для обычных индексов. Теперь она поддерживается:
- в индексах реального времени для
INSERT,REPLACE,DELETE,OPTIMIZE - в репликации
- в
ALTER - в
indextool --check
- в индексах реального времени для
-
Автоматическая компакция индексов (Проблема #478). Наконец, вам не нужно вручную вызывать OPTIMIZE или через крон-задачу или другой вид автоматизации. Manticore теперь делает это автоматически и по умолчанию. Вы можете установить порог компакции по умолчанию через optimize_cutoff глобальную переменную.
-
Переработка системы снимков и блокировок чанков. Эти изменения могут быть невидимы снаружи на первый взгляд, но они значительно улучшают поведение многих вещей, происходящих в индексах реального времени. В двух словах, ранее большинство операций манипуляции данными Manticore сильно полагались на блокировки, теперь мы используем снимки дисковых чанков вместо этого.
-
Значительно более высокая производительность массовых вставок в индекс реального времени. Например, на сервере AX101 от Hetzner с SSD, 128 ГБ ОЗУ и AMD Ryzen™ 9 5950X (16*2 ядра) с 3.6.0 вы могли вставить 236K документов в секунду в таблицу со схемой
name text, email string, description text, age int, active bit(1)(по умолчаниюrt_mem_limit, размер пакета 25000, 16 параллельных рабочих процессов вставки, всего вставлено 16 миллионов документов). В 4.0.2 та же степень параллелизма/размер пакета/количество дает 357K документов в секунду.MORE -
ALTER может добавлять/удалять полнотекстовое поле (в RT-режиме). Ранее можно было только добавлять/удалять атрибут.
-
🔬 Экспериментально: псевдошардирование для запросов с полным сканированием - позволяет распараллелить любой запрос, не являющийся полнотекстовым поиском. Вместо ручной подготовки шардов теперь можно просто включить новую опцию searchd.pseudo_sharding и ожидать снижения времени отклика до
CPU coresраз для запросов, не являющихся полнотекстовым поиском. Обратите внимание, что это может легко занять все имеющиеся ядра CPU, поэтому если важна не только задержка, но и пропускная способность - используйте с осторожностью.
- Linux Mint и Ubuntu Hirsute Hippo поддерживаются через APT-репозиторий
- более быстрое обновление по id через HTTP в больших индексах в некоторых случаях (зависит от распределения id)
- 671e65a2 - добавлено кэширование в lemmatizer-uk
- 3.6.0
- 4.0.2
time curl -X POST -d '{"update":{"index":"idx","id":4611686018427387905,"doc":{"mode":0}}}' -H "Content-Type: application/x-ndjson" http://127.0.0.1:6358/json/bulk
real 0m43.783s
user 0m0.008s
sys 0m0.007stime curl -X POST -d '{"update":{"index":"idx","id":4611686018427387905,"doc":{"mode":0}}}' -H "Content-Type: application/x-ndjson" http://127.0.0.1:6358/json/bulk
real 0m0.006s
user 0m0.004s
sys 0m0.001s- пользовательские флаги запуска для systemd. Теперь не нужно запускать searchd вручную, если требуется запустить Manticore с каким-либо специфическим флагом запуска
- новая функция LEVENSHTEIN(), которая вычисляет расстояние Левенштейна
- добавлены новые флаги запуска searchd
--replay-flags=ignore-trx-errorsи--replay-flags=ignore-all-errors, чтобы можно было запустить searchd, даже если binlog повреждён - Issue #621 - пробрасывание ошибок из RE2
- более точный COUNT(DISTINCT) для распределённых индексов, состоящих из локальных обычных индексов
- FACET DISTINCT для удаления дубликатов при фасетном поиске
- модификатор точной формы теперь не требует морфологии и работает для индексов с включённым поиском по инфиксам/префиксам
- новая версия может читать старые индексы, но старые версии не могут читать индексы Manticore 4
- удалена неявная сортировка по id. Сортируйте явно, если требуется
- значение по умолчанию для
charset_tableизменено с0..9, A..Z->a..z, _, a..z, U+410..U+42F->U+430..U+44F, U+430..U+44F, U+401->U+451, U+451наnon_cjk OPTIMIZEвыполняется автоматически. Если он не нужен, убедитесь, что установилиauto_optimize=0в секцииsearchdконфигурационного файла- Issue #616
ondisk_attrs_defaultбыли устаревшими, теперь они удалены - для контрибьюторов: теперь для сборок под Linux используется компилятор Clang, так как согласно нашим тестам он может собрать более быстрый Manticore Search и Manticore Columnar Library
- если max_matches не указан в поисковом запросе, он неявно обновляется минимально необходимым значением для повышения производительности нового колоночного хранилища. Это может повлиять на метрику
totalв SHOW META, но не наtotal_found, который является фактическим количеством найденных документов.
- убедитесь, что вы остановили Manticore 3 корректно:
- в
/var/lib/manticore/binlog/не должно быть файлов binlog (в директории должен быть толькоbinlog.meta) - иначе индексы, для которых Manticore 4 не сможет воспроизвести binlog, не будут запущены
- в
- новая версия может читать старые индексы, но старые версии не могут читать индексы Manticore 4, поэтому убедитесь, что сделали резервную копию, если хотите иметь возможность легко откатиться на предыдущую версию
- если вы запускаете кластер репликации, убедитесь, что вы:
- сначала корректно остановили все ваши ноды
- а затем запустили ноду, которая была остановлена последней, с
--new-cluster(запустите инструментmanticore_new_clusterв Linux). - прочитайте о перезапуске кластера для получения более подробной информации
- Исправлено множество проблем с репликацией:
- Коммит 696f - исправлен краш во время SST на узле-присоединяющемся при активном индексе; добавлена проверка sha1 на узле-присоединяющемся при записи файловых чанков для ускорения загрузки индекса; добавлена ротация измененных файлов индекса на узле-присоединяющемся при загрузке индекса; добавлено удаление файлов индекса на узле-присоединяющемся, когда активный индекс заменяется новым индексом от узла-донора; добавлены точки лога репликации на узле-доноре для отправки файлов и чанков
- Коммит b296 - краш при JOIN CLUSTER в случае некорректного адреса
- Коммит 418b - во время начальной репликации большого индекса присоединяющийся узел мог завершиться с ошибкой
ERROR 1064 (42000): invalid GTID, (null), донор мог перестать отвечать, пока другой узел присоединялся - Коммит 6fd3 - хэш мог вычисляться неправильно для большого индекса, что могло привести к сбою репликации
- Issue #615 - репликация завершалась сбоем при перезапуске кластера
- Issue #574 -
indextool --helpне отображает параметр--rotate - Issue #578 - высокое использование CPU процессом searchd в простое после примерно дня работы
- Issue #587 - немедленная запись .meta файла
- Issue #617 - файл manticore.json очищается
- Issue #618 -
searchd --stopwaitзавершается с ошибкой под root. Также исправлено поведение systemctl (ранее он показывал ошибку для ExecStop и не ждал достаточно долго для корректной остановки searchd) - Issue #619 - INSERT/REPLACE/DELETE vs SHOW STATUS.
command_insert,command_replaceи другие показывали неверные метрики - Issue #620 -
charset_tableдля обычного индекса имела неверное значение по умолчанию - Коммит 8f75 - новые дисковые чанки не блокируются в памяти (mlock)
- Issue #607 - Узел кластера Manticore падает, когда не может разрешить имя узла
- Issue #623 - репликация обновленного индекса может привести к неопределенному состоянию
- Коммит ca03 - indexer мог зависнуть при индексировании источника обычного индекса с json-атрибутом
- Коммит 53c7 - исправлен фильтр с выражением "не равно" для PQ индекса
- Коммит ccf9 - исправлен выбор окон для списковых запросов свыше 1000 совпадений.
SELECT * FROM pq ORDER BY id desc LIMIT 1000 , 100 OPTION max_matches=1100ранее не работал - Коммит a048 - HTTPS-запрос к Manticore мог вызывать предупреждение вида "max packet size(8388608) exceeded"
- Issue #648 - Manticore 3 мог зависнуть после нескольких обновлений строковых атрибутов
Поддерживающий релиз перед Manticore 4
- Поддержка Manticore Columnar Library для обычных индексов. Новая настройка columnar_attrs для обычных индексов
- Поддержка Украинского лемматизатора
- Полностью переработанные гистограммы. При построении индекса Manticore также строит гистограммы для каждого поля в нем, которые затем использует для более быстрой фильтрации. В версии 3.6.0 алгоритм был полностью переработан, и вы можете получить более высокую производительность, если у вас много данных и выполняется много фильтраций.
- Инструмент
manticore_new_cluster [--force], полезный для перезапуска кластера репликации через systemd - --drop-src для
indexer --merge - Новый режим
blend_mode='trim_all' - Добавлена поддержка экранирования JSON пути с помощью обратных кавычек
- indextool --check может работать в режиме RT
- FORCE/IGNORE INDEX(id) для SELECT/UPDATE
- ID чанка для объединенного дискового чанка теперь уникален
- indextool --check-disk-chunk CHUNK_NAME
- Более быстрый разбор JSON, наши тесты показывают снижение задержки на 3-4% для запросов вида
WHERE json.a = 1 - Не документированная команда
DEBUG SPLITкак предварительное условие для автоматического шардирования/перебалансировки
- Проблема #584 - неточные и нестабильные результаты FACET
- Проблема #506 - Странное поведение при использовании MATCH: тем, кто страдает от этой проблемы, необходимо перестроить индекс, так как проблема была на этапе построения индекса
- Проблема #387 - периодический дамп ядра при выполнении запроса с функцией SNIPPET()
- Оптимизации стека, полезные для обработки сложных запросов:
- Проблема #469 - Результаты SELECT приводят к CRASH DUMP
- e8420cc7 - определение размера стека для деревьев фильтров
- Проблема #461 - Обновление с использованием условия IN не применяется корректно
- Проблема #464 - SHOW STATUS сразу после CALL PQ возвращает - Проблема #481 - Исправлена сборка статического бинарника
- Проблема #502 - ошибка в многозапросах
- Проблема #514 - Невозможно использовать необычные имена для столбцов при использовании 'create table'
- Коммит d1db - сбой демона при воспроизведении binlog с обновлением строкового атрибута; установить версию binlog на 10
- Коммит 775d - исправлено определение фрейма стека выражений во время выполнения (тест 207)
- Коммит 4795 - фильтр индекса перколяторов и теги были пустыми для пустого сохраненного запроса (тест 369)
- Коммит c3f0 - сбои репликации потока SST в сети с высокой задержкой и высоким уровнем ошибок (репликация в разных центрах обработки данных); обновлена версия команды репликации на 1.03
- Коммит ba2d - блокировка кластера joiner при операциях записи после присоединения к кластеру (тест 385)
- Коммит de4d - соответствие подстановочным знакам с точным модификатором (тест 321)
- Коммит 6524 - контрольные точки docid против docstore
- Коммит f4ab - Непоследовательное поведение индексатора при разборе недопустимого xml
- Коммит 7b72 - Сохраненный запрос перколяторов с NOTNEAR выполняется бесконечно (тест 349)
- Коммит 812d - неправильный вес для фразы, начинающейся с подстановочного знака
- Коммит 1771 - запрос перколяторов с подстановочными знаками генерирует термины без полезной нагрузки при совпадении, что вызывает пересекающиеся попадания и нарушает совпадение (тест 417)
- Коммит aa0d - исправлено вычисление 'total' в случае параллелизованного запроса
- Коммит 18d8 - сбой в Windows с несколькими параллельными сессиями на демоне
- Коммит 8443 - некоторые настройки индекса не могли быть реплицированы
- Коммит 9341 - При высокой скорости добавления новых событий netloop иногда зависает из-за атомарного события 'kick', обрабатываемого один раз для нескольких событий за раз и теряющего актуальные действия из них статус запроса, а не статус сервера
- Коммит d805 - Новый сброшенный диск может быть потерян при коммите
- Коммит 63cb - неточная 'net_read' в профайлере
- Коммит f537 - Проблема с перколятором на арабском (тексты справа налево)
- Коммит 49ee - id не выбирается корректно при дублирующемся имени столбца
- Коммит refa сетевых событий для исправления сбоя в редких случаях
- e8420cc7 исправление в
indextool --dumpheader - Коммит ff71 - TRUNCATE WITH RECONFIGURE работал неправильно с сохраненными полями
- Новый формат бинарного лога: необходимо выполнить полную остановку Manticore перед обновлением
- Формат индекса немного изменяется: новая версия может читать ваши существующие индексы, но если вы решите откатиться с версии 3.6.0 на более старую, новые индексы будут недоступны для чтения
- Изменение формата репликации: не реплицируйте со старой версии на 3.6.0 и наоборот, переключайтесь на новую версию на всех ваших узлах одновременно
reverse_scanустарел. Убедитесь, что вы не используете эту опцию в своих запросах, начиная с версии 3.6.0, иначе они завершатся ошибкой- Начиная с этого релиза мы больше не предоставляем сборки для RHEL6, Debian Jessie и Ubuntu Trusty. Если для вас критически важно, чтобы они поддерживались, свяжитесь с нами
- Больше не используется неявная сортировка по id. Если вы полагаетесь на нее, обязательно обновите свои запросы соответствующим образом
- Опция поиска
reverse_scanустарела
- Новые клиенты для Python, Javascript и Java теперь общедоступны и хорошо задокументированы в этом руководстве.
- Автоматическое удаление дискового чанка реального индекса. Эта оптимизация позволяет автоматически удалять дисковый чанк при OPTIMIZировании реального индекса, когда чанк явно больше не нужен (все документы подавлены). Ранее это все равно требовало слияния, теперь чанк можно просто мгновенно удалить. Опция cutoff игнорируется, т.е. даже если фактически ничего не сливается, устаревший дисковый чанк удаляется. Это полезно, если вы поддерживаете хранение данных в своем индексе и удаляете старые документы. Теперь уплотнение таких индексов будет быстрее.
- Автономный NOT как опция для SELECT
- Issue #453 Новая опция indexer.ignore_non_plain=1 полезна, если вы запускаете
indexer --allи в файле конфигурации есть не только простые индексы. Безignore_non_plain=1вы получите предупреждение и соответствующий код завершения. - SHOW PLAN ... OPTION format=dot и EXPLAIN QUERY ... OPTION format=dot позволяют визуализировать выполнение плана полнотекстового запроса. Полезно для понимания сложных запросов.
indexer --verboseустарел, так как он никогда ничего не добавлял к выводу indexer- Для дампа трассировки сторожевого процесса теперь следует использовать сигнал
USR2вместоUSR1
- Issue #423 кириллический символ точка вызов сниппетов режим retain не подсвечивает
- Issue #435 RTINDEX - GROUP N BY выражение select = фатальный сбой
- Commit 2b3b статус searchd показывает Segmentation fault при работе в кластере
- Commit 9dd2 'SHOW INDEX index.N SETTINGS' не обращается к чанкам >9
- Issue #389 Ошибка, вызывающая сбой Manticore
- Commit fba1 Конвертер создает поврежденные индексы
- Commit eecd stopword_step=0 vs CALL SNIPPETS()
- Commit ea68 count distinct возвращает 0 при низком max_matches на локальном индексе
- Commit 362f При использовании агрегации сохраненные тексты не возвращаются в результатах
- OPTIMIZE сокращает количество дисковых чанков до числа чанков (по умолчанию
2* Количество ядер) вместо одного. Оптимальное количество чанков можно контролировать с помощью опции cutoff. - Оператор NOT теперь можно использовать автономно. По умолчанию он отключен, поскольку случайные одиночные запросы NOT могут быть медленными. Его можно включить, установив новую директиву searchd not_terms_only_allowed в
0. - Новая настройка max_threads_per_query устанавливает, сколько потоков может использовать запрос. Если директива не установлена, запрос может использовать потоки до значения threads.
Для каждого запроса
SELECTколичество потоков можно ограничить с помощью OPTION threads=N, переопределяя глобальныйmax_threads_per_query. - Перколяционные индексы теперь можно импортировать с помощью IMPORT TABLE.
- HTTP API
/searchполучает базовую поддержку фасетного поиска/группировки с помощью нового узла запросаaggs.
- Если не объявлена директива прослушивания репликации, движок попытается использовать порты после определенного порта 'sphinx', до 200.
listen=...:sphinxнеобходимо явно установить для подключений SphinxSE или клиентов SphinxAPI.- SHOW INDEX STATUS выводит новые метрики:
killed_documents,killed_rate,disk_mapped_doclists,disk_mapped_cached_doclists,disk_mapped_hitlistsиdisk_mapped_cached_hitlists. - SQL команда
statusтеперь выводитQueue\ThreadsиTasks\Threads.
dist_threadsтеперь полностью устарел, searchd будет записывать предупреждение, если директива все еще используется.
Официальный образ Docker теперь основан на Ubuntu 20.04 LTS
Помимо обычного пакета manticore, вы также можете установить Manticore Search по компонентам:
manticore-server-core- предоставляетsearchd, manpage, каталог логов, API и модуль galera. Он также установитmanticore-commonкак зависимость.manticore-server- предоставляет автоматизационные скрипты для ядра (init.d, systemd) и оберткуmanticore_new_cluster. Он также установитmanticore-server-coreкак зависимость.manticore-common- предоставляет конфигурацию, стоп-слова, общие документы и скелетные папки (datadir, модули и т.д.)manticore-tools- предоставляет вспомогательные инструменты (indexer,indextoolи т.д.), их manpages и примеры. Он также установитmanticore-commonкак зависимость.manticore-icudata(RPM) илиmanticore-icudata-65l(DEB) - предоставляет файл данных ICU для использования морфологии icu.manticore-devel(RPM) илиmanticore-dev(DEB) - предоставляет заголовки для разработки UDF.
- Коммит 2a47 Сбой демона в группировщике на RT индексе с разными чанками
- Коммит 57a1 Быстрый путь для пустых удаленных документов
- Коммит 07dd Обнаружение фрейма стека выражений во время выполнения
- Коммит 08ae Сопоставление более 32 полей в индексах перколяции
- Коммит 16b9 Диапазон портов для прослушивания репликации
- Коммит 5fa6 Показать создание таблицы на pq
- Коммит 54d1 Поведение порта HTTPS
- Коммит fdbb Смешивание строк docstore при замене
- Коммит afb5 Переключение уровня сообщения о недоступности TFO на 'info'
- Коммит 59d9 Сбой при неверном использовании strcmp
- Коммит 04af Добавление индекса в кластер с системными (стоп-словами) файлами
- Коммит 5014 Объединение индексов с большими словарями; оптимизация RT больших дисковых чанков
- Коммит a2ad Indextool может выгружать метаданные из текущей версии
- Коммит 69f6 Проблема в порядке группировки в GROUP N
- Коммит 24d5 Явная очистка для SphinxSE после рукопожатия
- Коммит 31c4 Избегать копирования огромных описаний, когда это не нужно
- Коммит 2959 Отрицательное время в показе потоков
- Коммит f0b3 Плагин фильтра токенов против нулевых дельт позиции
- Коммит a49e Изменить 'FAIL' на 'WARNING' при нескольких попаданиях
-
Этот релиз занял так много времени, потому что мы усердно работали над изменением многозадачного режима с потоков на корутины. Это упрощает конфигурацию и делает параллелизацию запросов гораздо более понятной: Manticore просто использует заданное количество потоков (см. новую настройку threads), и новый режим гарантирует, что это сделано наиболее оптимальным образом.
-
Изменения в подсветке:
- любая подсветка, которая работает с несколькими полями (
highlight({},'field1, field2') илиhighlightв json запросах) теперь по умолчанию применяет ограничения на поле. - любая подсветка, которая работает с обычным текстом (
highlight({}, string_attr)илиsnippet()теперь применяет ограничения ко всему документу. - ограничения на поле могут быть переключены на глобальные ограничения с помощью опции
limits_per_field=0(1по умолчанию). - allow_empty теперь
0по умолчанию для подсветки через HTTP JSON.
- любая подсветка, которая работает с несколькими полями (
-
Один и тот же порт теперь может использоваться для http, https и бинарного API (для принятия соединений от удаленного экземпляра Manticore).
listen = *:mysqlпо-прежнему требуется для соединений через mysql протокол. Manticore теперь автоматически определяет тип клиента, пытающегося подключиться к нему, за исключением MySQL (из-за ограничений протокола). -
В режиме RT поле теперь может быть текстовым и строковым атрибутом одновременно - проблема GitHub #331.
В обычном режиме это называется
sql_field_string. Теперь это доступно в RT режиме для индексов реального времени тоже. Вы можете использовать это, как показано в примере:create table t(f string attribute indexed); insert into t values(0,'abc','abc'); select * from t where match('abc'); +---------------------+------+ | id | f | +---------------------+------+ | 2810845392541843463 | abc | +---------------------+------+ 1 row in set (0.01 sec) mysql> select * from t where f='abc'; +---------------------+------+ | id | f | +---------------------+------+ | 2810845392541843463 | abc | +---------------------+------+ 1 row in set (0.00 sec)
- Теперь можно подсвечивать строковые атрибуты.
- Поддержка SSL и сжатия для SQL-интерфейса
- Поддержка команды
statusклиента mysql. - Репликация теперь может реплицировать внешние файлы (стоп-слова, исключения и т.д.).
- Оператор фильтрации
inтеперь доступен через HTTP JSON интерфейс. expressionsв HTTP JSON.- Теперь можно изменять
rt_mem_limitна лету в RT-режиме, т.е. можно выполнятьALTER ... rt_mem_limit=<новое значение>. - Теперь можно использовать отдельные таблицы символов для CJK:
chinese,japaneseиkorean. - thread_stack теперь ограничивает максимальный стек потока, а не начальный.
- Улучшен вывод
SHOW THREADS. - Отображение прогресса длительного
CALL PQвSHOW THREADS. - cpustat, iostat, coredump можно изменять во время выполнения с помощью SET.
- Реализовано
SET [GLOBAL] wait_timeout=NUM,
- Формат индекса был изменен. Индексы, построенные в версии 3.5.0, не могут быть загружены Manticore версии < 3.5.0, но Manticore 3.5.0 понимает старые форматы.
INSERT INTO PQ VALUES()(т.е. без указания списка столбцов) ранее ожидал строго значения(query, tags). Это изменено на(id,query,tags,filters). ID можно установить в 0, если требуется его авто-генерация.allow_empty=0теперь значение по умолчанию при подсветке через HTTP JSON интерфейс.- В
CREATE TABLE/ALTER TABLEдля внешних файлов (стоп-слов, исключений и т.д.) разрешены только абсолютные пути.
ram_chunks_countпереименована вram_chunk_segments_countвSHOW INDEX STATUS.workersустарел. Теперь существует только один режим workers.dist_threadsустарел. Все запросы теперь максимально параллельны (ограниченыthreadsиjobs_queue_size).max_childrenустарел. Используйте threads для установки количества потоков, которые будет использовать Manticore (по умолчанию равно количеству ядер ЦП).queue_max_lengthустарел. Вместо этого, если это действительно необходимо, используйте jobs_queue_size для тонкой настройки размера внутренней очереди заданий (по умолчанию не ограничен).- Все конечные точки
/json/*теперь доступны без/json/, например,/search,/insert,/delete,/pqи т.д. - Значение
field, означающее "полнотекстовое поле", переименовано в "text" вdescribe.3.4.2:
mysql> describe t; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | field | indexed stored | +-------+--------+----------------+3.5.0:
mysql> describe t; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | text | indexed stored | +-------+--------+----------------+ - Кириллическая
ибольше не отображается вiвnon_cjkcharset_table (которая используется по умолчанию), так как это слишком сильно влияло на русские стеммеры и лемматизаторы. read_timeout. Используйте вместо этого network_timeout, который контролирует как чтение, так и запись.
- Официальный пакет для Ubuntu Focal 20.04
- Имя deb-пакета изменено с
manticore-binнаmanticore
- Проблема #351 утечка памяти searchd
- Коммит ceab Небольшое чтение за пределами в фрагментах
- Коммит 1c3e Опасная запись в локальную переменную для запросов на сбой
- Коммит 26e0 Небольшая утечка памяти сортировщика в тесте 226
- Коммит d2c7 Огромная утечка памяти в тесте 226
- Коммит 0dd8 Кластер показывает, что узлы синхронизированы, но
count(*)показывает разные числа - Коммит f1c1 Косметика: Дублирующиеся и иногда потерянные предупреждающие сообщения в журнале
- Коммит f1c1 Косметика: (null) имя индекса в журнале
- Коммит 359d Невозможно получить более 70M результатов
- Коммит 19f3 Невозможно вставить правила PQ с синтаксисом без колонок
- Коммит bf68 Вводя документ в индекс в кластере, появляется вводящий в заблуждение текст ошибки
- Коммит 2cf1
/json/replaceиjson/updateвозвращают id в экспоненциальной форме - Проблема #324 Обновление скалярных свойств json и mva в одном запросе
- Коммит d384
hitless_wordsне работает в режиме RT - Коммит 5813
ALTER RECONFIGUREв режиме rt должен быть запрещен - Коммит 5813
rt_mem_limitсбрасывается на 128M после перезапуска searchd - highlight() иногда зависает
- Коммит 7cd8 Не удалось использовать U+код в режиме RT
- Коммит 2b21 Не удалось использовать подстановочный знак в словоформах в режиме RT
- Коммит e9d0 Исправлено
SHOW CREATE TABLEпротив нескольких файлов словоформ - Коммит fc90 JSON-запрос без "query" вызывает сбой searchd
- Официальный docker Manticore не мог индексировать из mysql 8
- Коммит 23e0 HTTP /json/insert требует id
- Коммит bd67
SHOW CREATE TABLEне работает для PQ - Коммит bd67
CREATE TABLE LIKEне работает должным образом для PQ - Коммит 5eac Конец строки в настройках в показе статуса индекса
- Коммит cb15 Пустой заголовок в "highlight" в HTTP JSON-ответе
- Проблема #318 Ошибка инфикса
CREATE TABLE LIKE - Коммит 9040 RT вылетает под нагрузкой
- cd512c7d Потерян журнал сбоев при сбое на дисковом куске RT
- Проблема #323 Ошибка импорта таблицы и закрытие соединения
- Коммит 6275
ALTER reconfigureповреждает индекс PQ - Коммит 9c1d Проблемы с перезагрузкой searchd после изменения типа индекса
- Коммит 71e2 Демон вылетает при импорте таблицы с пропущенными файлами
- Проблема #322 Сбой при выборе с использованием нескольких индексов, группировки и ranker = none
- Коммит c3f5
HIGHLIGHT()не выделяет в строковых атрибутах - Проблема #320
FACETне удается отсортировать по строковому атрибуту - Коммит 4f1a Ошибка в случае отсутствия каталога данных
- Коммит 04f4 access_* не поддерживаются в режиме RT
- Коммит 1c06 Плохие JSON-объекты в строках: 1.
CALL PQвозвращает "Плохие JSON-объекты в строках: 1", когда json превышает некоторое значение. - Коммит 32f9 Непоследовательность в режиме RT. В некоторых случаях я не могу удалить индекс, так как он неизвестен, и не могу создать его, так как каталог не пуст.
- Проблема #319 Сбой при выборе
- Коммит 22a2
max_xmlpipe2_field= 2M возвращает предупреждение о поле 2M - Проблема #342 Ошибка выполнения условий запроса
- Коммит dd8d Простой поиск по 2 терминам находит документ, содержащий только один термин
- Коммит 9091 В PQ было невозможно сопоставить json с заглавными буквами в ключах
- Коммит 56da Индексатор вылетает на csv+docstore
- Проблема #363 использование
[null]в json attr в centos 7 вызывает поврежденные вставленные данные - Основная Проблема #345 Записи не вставляются, count() случайный, "replace into" возвращает OK
- max_query_time слишком сильно замедляет SELECT
- Проблема #352 Связь мастер-агент не работает на Mac OS
- Проблема #328 Ошибка при подключении к Manticore с Connector.Net/Mysql 8.0.19
- Коммит daa7 Исправлено экранирование \0 и оптимизирована производительность
- Коммит 9bc5 Исправлено count distinct против json
- Коммит 4f89 Исправлено удаление таблицы на другом узле
- Коммит 952a Исправить сбои при плотном выполнении вызова pq
- Коммит 2ffe исправляет сбой индекса RT из старой версии при индексировании данных
- сервер работает в 2 режимах: rt-mode и plain-mode
- rt-mode требует data_dir и отсутствует определение индекса в конфиге
- в plain-mode индексы определяются в конфиге; data_dir не разрешён
- репликация доступна только в rt-mode
- charset_table по умолчанию соответствует псевдониму non_cjk
- в rt-mode полнотекстовые поля по умолчанию индексируются и сохраняются
- полнотекстовые поля в rt-mode переименованы с 'field' в 'text'
- ALTER RTINDEX переименован в ALTER TABLE
- TRUNCATE RTINDEX переименован в TRUNCATE TABLE
- поля только для хранения
- SHOW CREATE TABLE, IMPORT TABLE
- значительно более быстрая очередь без блокировок (lockless PQ)
- /sql может выполнять любые SQL-запросы в режиме mode=raw
- псевдоним mysql для протокола mysql41
- состояние по умолчанию state.sql в data_dir
- Коммит a533 исправляет сбой при неверном синтаксисе поля в highlight()
- Коммит 7fbb исправляет сбой сервера при репликации RT индекса с docstore
- Коммит 24a0 исправляет сбой при highlight для индекса с опцией infix или prefix и без включённых сохранённых полей
- Коммит 3465 исправляет ложную ошибку о пустом docstore и lookup dock-id для пустого индекса
- Коммит a707 исправляет #314 ошибку INSERT с завершающей точкой с запятой
- Коммит 9562 удалено предупреждение о несовпадении слов запроса
- Коммит b860 исправлены запросы в сниппетах, сегментированных через ICU
- Коммит 5275 исправлена гонка при поиске/добавлении в кэш блоков docstore
- Коммит f06e исправлена утечка памяти в docstore
- Коммит a725 исправляет #316 LAST_INSERT_ID возвращает пустое значение при INSERT
- Коммит 1ebd исправляет #317 HTTP endpoint json/update для поддержки массива для MVA и объекта для JSON атрибута
- Коммит e426 исправлена проблема с индексатором, сбрасывающим rt без явного id
- Параллельный поиск по Real-Time индексам
- Команда EXPLAIN QUERY
- конфигурационный файл без определений индексов (альфа-версия)
- команды CREATE/DROP TABLE (альфа-версия)
- indexer --print-rt - может читать из источника и выводить INSERT для Real-Time индекса
- Обновлены стеммеры Snowball до версии 2.0
- LIKE фильтр для SHOW INDEX STATUS
- улучшено использование памяти при больших max_matches
- SHOW INDEX STATUS добавляет ram_chunks_count для RT индексов
- очередь без блокировок (lockless PQ)
- изменено LimitNOFILE на 65536
- Коммит 9c33 добавлена проверка схемы индекса на наличие дублирующихся атрибутов #293
- Коммит a008 исправлен сбой в hitless terms
- Коммит 6895 исправлена потеря docstore после ATTACH
- Коммит d6f6 исправлена проблема с docstore в распределенной конфигурации
- Коммит bce2 заменен FixedHash на OpenHash в сортировщике
- Коммит e0ba исправлены атрибуты с дублирующимися именами при определении индекса
- Коммит ca81 исправлен html_strip в HIGHLIGHT()
- Коммит 493a исправлен макрос passage в HIGHLIGHT()
- Коммит a82d исправлены проблемы с двойным буфером при создании RT-индексом малого или большого дискового чанка
- Коммит a404 исправлено удаление событий для kqueue
- Коммит 8bea исправлено сохранение дискового чанка для большого значения rt_mem_limit у RT-индекса
- Коммит 8707 исправлено переполнение float при индексации
- Коммит a564 исправлено: вставка документа с отрицательным ID в RT-индекс теперь завершается ошибкой
- Коммит bbeb исправлен сбой сервера на ranker fieldmask
- Коммит 3809 исправлен сбой при использовании кэша запросов
- Коммит dc2a исправлен сбой при использовании RAM-сегментов RT-индекса с параллельными вставками
- Автоинкрементный ID для RT-индексов
- Поддержка выделения для docstore через новую функцию HIGHLIGHT(), также доступную в HTTP API
- SNIPPET() может использовать специальную функцию QUERY(), которая возвращает текущий запрос MATCH
- Новая опция field_separator для функций выделения.
- Ленивая загрузка хранимых полей для удаленных узлов (может значительно повысить производительность)
- Строки и выражения больше не нарушают оптимизации multi-query и FACET
- Сборка для RHEL/CentOS 8 теперь использует библиотеку mysql libclient из mariadb-connector-c-devel
- Файл данных ICU теперь поставляется с пакетами, параметр icu_data_dir удален
- Файлы службы systemd включают политику 'Restart=on-failure'
- Инструмент indextool теперь может проверять индексы реального времени в режиме онлайн
- Конфигурация по умолчанию теперь /etc/manticoresearch/manticore.conf
- Служба на RHEL/CentOS переименована в 'manticore' с 'searchd'
- Удалены опции сниппета query_mode и exact_phrase
- Commit 6ae4 исправление сбоя при выполнении SELECT запроса через HTTP интерфейс
- Commit 5957 исправление RT индекса, который сохраняет дисковые чанки, но не помечает некоторые документы как удаленные
- Commit e861 исправление сбоя при поиске по многим индексам или многим запросам с dist_threads
- Commit 4409 исправление сбоя при генерации инфиксов для длинных терминов с широкими utf8 кодовыми точками
- Commit 5fd5 исправление гонки при добавлении сокета в IOCP
- Commit cf10 исправление проблемы с булевыми запросами против json списка выбора
- Commit 996d исправление проверки indextool для сообщения о неправильном смещении skiplist, проверка doc2row поиска
- Commit 6e3f исправление индексации, которая создает плохой индекс с отрицательным смещением skiplist на больших данных
- Commit faed исправление JSON, который конвертирует только числовые значения в строку и конвертацию JSON строки в числовое значение в выражениях
- Commit 5331 исправление выхода indextool с кодом ошибки в случае установки нескольких команд в командной строке
- Commit 7955 исправление #275 binlog недопустимое состояние при ошибке недостаточно места на диске
- Commit 2284 исправление #279 сбоя при фильтре IN для JSON атрибута
- Commit ce2e исправление #281 неправильного вызова закрытия канала
- Commit 5355 исправление зависания сервера при вызове CALL PQ с рекурсивным JSON атрибутом, закодированным как строка
- Commit a5fc исправление продвижения за пределы конца списка документов в узле multiand
- Commit a362 исправление получения публичной информации о потоке
- Commit f8d2 исправление блокировок кэша docstore
- Хранение документов
- новые директивы stored_fields, docstore_cache_size, docstore_block_size, docstore_compression, docstore_compression_level
- улучшенная поддержка SSL
- обновленный встроенный набор символов non_cjk
- отключено ведение журнала операторов UPDATE/DELETE при выполнении SELECT в журнале запросов
- пакеты RHEL/CentOS 8
- Commit 301a исправление сбоя при замене документа в дисковом чанке RT индекса
- Commit 46c1 исправление #269 LIMIT N OFFSET M
- Commit 92a4 исправление операторов DELETE с явно установленным id или списком id, предоставленным для пропуска поиска
- Commit 8ca7 исправление неправильного индекса после удаления события в netloop в poller windowspoll
- Commit 6036 исправление округления float в JSON через HTTP
- Commit 62f6 исправление удаленных фрагментов для проверки пустого пути в первую очередь; исправление тестов для windows
- Commit aba2 исправление перезагрузки конфигурации для работы в windows так же, как и в linux
- Commit 6b8c исправление #194 PQ для работы с морфологией и стеммерами
- Commit 174d исправление управления списками сегментов RT
- Экспериментальная поддержка SSL для HTTP API
- фильтр полей для CALL KEYWORDS
- max_matches для /json/search
- автоматическое определение размера по умолчанию для Galera gcache.size
- улучшенная поддержка FreeBSD
- Коммит 0a1a исправлена репликация RT-индекса на узел, где такой же RT-индекс уже существует и имеет другой путь
- Коммит 4adc исправлено перепланирование сброса на диск для индексов без активности
- Коммит d6c0 улучшено перепланирование сброса на диск для RT/PQ индексов
- Коммит d0a7 исправлена опция индекса index_field_lengths для TSV и CSV piped источников (#250)
- Коммит 1266 исправлен некорректный отчет indextool при проверке блочного индекса на пустом индексе
- Коммит 553c исправлен пустой список выбора в логе SQL-запросов Manticore
- Коммит 56c8 исправлен ответ indexer на -h/--help
- репликация для RealTime-индексов
- ICU-токенизатор для китайского языка
- новая опция морфологии icu_chinese
- новая директива icu_data_dir
- транзакции с несколькими операторами для репликации
- LAST_INSERT_ID() и @session.last_insert_id
- LIKE 'шаблон' для SHOW VARIABLES
- Вставка нескольких документов для перколяционных индексов
- Добавлены парсеры времени для конфигурации
- внутренний менеджер задач
- mlock для компонентов списков документов и хитов
- jail snippets path
- Поддержка библиотеки RLP удалена в пользу ICU; все директивы rlp* удалены
- Обновление ID документа с помощью UPDATE отключено
- Коммит f047 исправлены дефекты в concat и group_concat
- Коммит b081 исправлен тип атрибута query uid в перколяционном индексе на BIGINT
- Коммит 4cd8 не падать, если не удалось предварительно выделить новый дисковой чанк
- Коммит 1a55 добавлен отсутствующий тип данных timestamp в ALTER
- Коммит f3a8 исправлен краш из-за неправильного чтения mmap
- Коммит 4475 исправлен хэш блокировки кластеров в репликации
- Коммит ff47 исправлена утечка провайдеров в репликации
- Коммит 58dc исправлена #246 неопределенная sigmask в indexer
- Коммит 3dd8 исправлена гонка в отчетности netloop
- Коммит a02a нулевой зазор для балансировщика стратегий HA
- добавлены mmap-ридеры для документов и списков хитов
- ответ конечной точки HTTP
/sqlтеперь такой же, как ответ/json/search - новые директивы
access_plain_attrs,access_blob_attrs,access_doclists,access_hitlists - новая директива
server_idдля настроек репликации
- удалена конечная точка HTTP
/search
read_buffer,ondisk_attrs,ondisk_attrs_default,mlockзаменены директивамиaccess_*
- Коммит 849c разрешены имена атрибутов, начинающиеся с цифр, в списке выбора
- Коммит 48e6 исправлены MVA в UDF, исправлен алиасинг MVA
- Коммит 0555 исправлен #187 краш при использовании запроса с SENTENCE
- Коммит 93bf исправлена #143 поддержка () вокруг MATCH()
- Коммит 599e исправлено сохранение состояния кластера при выполнении ALTER cluster
- Коммит 230c исправлен краш сервера при ALTER index с blob-атрибутами
- Коммит 5802 исправлена #196 фильтрация по id
- Коммит 25d2 отменен поиск по шаблонным индексам
- Коммит 2a30 исправлен столбец id для соответствия обычному типу bigint в SQL-ответе
- Новое хранилище индексов. Немасштабируемые атрибуты больше не ограничены размером 4 ГБ на индекс
- Директива attr_update_reserve
- Строковые, JSON и MVA атрибуты могут быть обновлены с помощью UPDATE
- Списки удаления применяются во время загрузки индекса
- Директива killlist_target
- Ускорение многократных AND-поисков
- Улучшена средняя производительность и использование оперативной памяти
- Инструмент convert для обновления индексов, созданных в версии 2.x
- Функция CONCAT()
- JOIN CLUSTER cluster AT 'nodeaddress:port'
- ALTER CLUSTER posts UPDATE nodes
- Директива node_address
- Список узлов выводится в SHOW STATUS
- в случае индексов с killlists сервер не вращает индексы в порядке, определённом в конфиге, а следует цепочке целей killlist
- порядок индексов в поиске больше не определяет порядок применения killlists
- Идентификаторы документов теперь подписанные большие целые числа
- docinfo (теперь всегда extern), inplace_docinfo_gap, mva_updates_pool
- Galera-репликация для percolate-индексов
- OPTION morphology
Минимальная версия Cmake теперь 3.13. Для компиляции требуются библиотеки boost и libssl для разработки.
- Коммит 6967 исправлен сбой при множественных звёздочках в списке select для запроса к множеству распределённых индексов
- Коммит 36df исправлен #177 — большой пакет через Manticore SQL интерфейс
- Коммит 5793 исправлен #170 сбой сервера при RT optimize с обновлённым MVA
- Коммит edb2 исправлен сбой сервера при удалении binlog вследствие удаления RT индекса после перезагрузки конфига по SIGHUP
- Коммит bd3e исправлены payloads аутентификационного плагина handshake MySQL
- Коммит 6a21 исправлен #172 — настройки phrase_boundary для RT индекса
- Коммит 3562 исправлен #168 — дедлок при ATTACH индекса к самому себе
- Коммит 250b исправлено: binlog сохраняет пустую метаинформацию после сбоя сервера
- Коммит 4aa6 исправлен сбой сервера из-за строки на сортировщике из RT индекса с дисковыми чанками
- SUBSTRING_INDEX()
- Поддержка SENTENCE и PARAGRAPH для percolate-запросов
- systemd-генератор для Debian/Ubuntu; также добавлен LimitCORE для разрешения core dump
- Коммит 84fe исправлен сбой сервера в режиме совпадения all и пустом полномтекстовом запросе
- Коммит daa8 исправлен сбой при удалении статической строки
- Коммит 2207 исправлен код выхода при неудаче indextool с FATAL
- Коммит 0721 исправлен #109 — отсутствие совпадений для префиксов из-за некорректной проверки exact form
- Коммит 8af8 исправлен #161 перезагрузка настроек конфига для RT индексов
- Коммит e2d5 исправлен сбой сервера при доступе к большой JSON строке
- Коммит 75cd исправлено: поле PQ в JSON-документе, изменённом stripper’ом индекса, вызывает ошибочное совпадение с соседним полем
- Коммит e2f7 исправлен сбой сервера при разборе JSON на сборках RHEL7
- Коммит 3a25 исправлен сбой функции unescaping json при символе слэша на границе
- Коммит be9f исправлена опция 'skip_empty', чтобы пропускать пустые документы и не предупреждать, что они невалидный json
- Коммит 266e исправлен #140 — вывод 8 знаков на float, если 6 недостаточно для точности
- Коммит 3f6d исправлено создание пустых jsonobj
- Коммит f3c7 исправлен #160 — пустой mva возвращает NULL вместо пустой строки
- Коммит 0afa исправлена ошибка сборки без pthread_getname_np
- Коммит 9405 исправлен сбой при завершении работы сервера с thread_pool workers
- Распределенные индексы для перколяторных индексов
- CALL PQ новые опции и изменения:
- skip_bad_json
- mode (sparsed/sharded)
- json документы могут передаваться как json массив
- shift
- Имена столбцов 'UID', 'Documents', 'Query', 'Tags', 'Filters' были переименованы в 'id', 'documents', 'query', 'tags', 'filters'
- DESCRIBE pq TABLE
- SELECT FROM pq, где UID больше не возможен, используйте 'id' вместо
- SELECT по pq индексам на уровне с обычными индексами (например, вы можете фильтровать правила через REGEX())
- ANY/ALL могут использоваться на тегах PQ
- выражения имеют автоматическое преобразование для JSON полей, не требуя явного приведения
- встроенная 'non_cjk' charset_table и 'cjk' ngram_chars
- встроенные коллекции стоп-слов для 50 языков
- несколько файлов в объявлении стоп-слов также могут быть разделены запятой
- CALL PQ может принимать JSON массив документов
- Коммит a4e1 исправил утечку, связанную с csjon
- Коммит 28d8 исправил сбой из-за отсутствующего значения в json
- Коммит bf4e исправил сохранение пустой мета для RT индекса
- Коммит 33b4 исправил потерянный флаг формы (точный) для последовательности лемматизатора
- Коммит 6b95 исправил строковые атрибуты > 4M использовать насыщение вместо переполнения
- Коммит 6214 исправил сбой сервера на SIGHUP с отключенным индексом
- Коммит 3f7e исправил сбой сервера на одновременных командах статуса API сессии
- Коммит cd9e исправил сбой сервера при удалении запроса к RT индексу с фильтрами полей
- Коммит 9376 исправил сбой сервера при CALL PQ к распределенному индексу с пустым документом
- Коммит 8868 исправил обрезку сообщения об ошибке Manticore SQL больше 512 символов
- Коммит de9d исправил сбой при сохранении перколяторного индекса без binlog
- Коммит 2b21 исправил работу http интерфейса в OSX
- Коммит e92c исправил ложное сообщение об ошибке indextool при проверке MVA
- Коммит 238b исправил блокировку записи при FLUSH RTINDEX, чтобы не блокировать весь индекс во время сохранения и при обычном сбросе из rt_flush_period
- Коммит c26a исправил зависание ALTER перколяторного индекса в ожидании загрузки поиска
- Коммит 9ee5 исправил max_children, чтобы использовать стандартное количество потоков thread_pool для значения 0
- Коммит 5138 исправил ошибку при индексации данных в индекс с плагином index_token_filter вместе со стоп-словами и stopword_step=0
- Коммит 2add исправил сбой при отсутствии lemmatizer_base при использовании aot лемматизаторов в определениях индекса
- Функция REGEX
- limit/offset для json API поиска
- точки профилирования для qcache
- Коммит eb3c исправил сбой сервера на FACET с несколькими атрибутами широких типов
- Коммит d915 исправил неявную группировку по основному списку выбора FACET запроса
- Коммит 5c25 исправил сбой на запросе с GROUP N BY
- Коммит 85d3 исправил взаимную блокировку при обработке сбоя в операциях с памятью
- Коммит 8516 исправил потребление памяти indextool во время проверки
- Коммит 58fb исправил включение gmock, которое больше не нужно, так как upstream решает это самостоятельно
- SHOW THREADS в случае удаленных распределенных индексов выводит оригинальный запрос вместо вызова API
- SHOW THREADS новая опция
format=sphinxqlвыводит все запросы в SQL формате - SHOW PROFILE выводит дополнительный этап
clone_attrs
- Коммит 4f15 исправлена ошибка сборки с libc без malloc_stats, malloc_trim
- Коммит f974 исправлена обработка специальных символов внутри слов для результата CALL KEYWORDS
- Коммит 0920 исправлена поломка CALL KEYWORDS для распределённого индекса через API или удалённого агента
- Коммит fd68 исправлена передача agent_query_timeout распределённого индекса агентам как max_query_time
- Коммит 4ffa исправлен счётчик общего числа документов в дисковом чанке, который отключался командой OPTIMIZE и ломал расчёт веса
- Коммит dcaf исправлены множественные tail hits в RT индексе из blended
- Коммит eee3 исправлен deadlock при ротации
- опция sort_mode для CALL KEYWORDS
- DEBUG на VIP подключении может выполнять 'crash
' для намеренного вызова SIGEGV на сервере - DEBUG может выполнять 'malloc_stats' для дампа статистики malloc в searchd.log и 'malloc_trim' для вызова malloc_trim()
- улучшен backtrace при наличии gdb в системе
- Commit 0f3c исправлен сбой или ошибка rename в Windows
- Commit 1455 исправлены сбои сервера на 32-битных системах
- Commit ad37 исправлен сбой или зависание сервера при пустом выражении SNIPPET
- Commit b36d исправлена сломанная непрогрессивная оптимизация и исправлена прогрессивная оптимизация, чтобы не создавать kill-list для самого старого chunk на диске
- Commit 34b0 исправлен неправильный ответ queue_max_length для SQL и API в режиме рабочего потока пула потоков
- Commit ae4b исправлен сбой при добавлении запроса полного сканирования в индекс PQ с установленными опциями regexp или rlp
- Commit f80f исправлен сбой при вызове одного PQ за другим
- Commit 9742 рефакторинг AcquireAccum
- Commit 39e5 исправлена утечка памяти после вызова pq
- Commit 21bc косметический рефакторинг (c++11 стиль c-трушек, значения по умолчанию, nullptr)
- Commit 2d69 исправлена утечка памяти при попытке вставить дубликат в индекс PQ
- Commit 5ed9 исправлен сбой при использовании JSON поля IN с большими значениями
- Commit 4a52 исправлен сбой сервера при выполнении оператора CALL KEYWORDS для RT индекса с установленным ограничением расширения
- Commit 5526 исправлен неверный фильтр в запросах PQ matches;
- Commit 204f введен небольшой аллокатор объектов для ptr атрибутов
- Commit 2545 проведен рефакторинг ISphFieldFilter с добавлением подсчёта ссылок
- Commit 1366 исправлены неопределённое поведение/segfault при использовании strtod на нетерминированных строках
- Commit 94bc исправлена утечка памяти при обработке json наборов результатов
- Commit e78e исправлен выход за пределы блока памяти при применении атрибута add
- Commit fad5 рефакторинг CSphDict для версии с подсчётом ссылок
- Commit fd84 исправлена утечка внутреннего типа AOT за пределами
- Commit 5ee7 исправлена утечка памяти в управлении токенизатором
- Commit 116c исправлена утечка памяти в grouper
- Commit 56fd специальное освобождение/копирование для динамических указателей в matches (утечка памяти в grouper)
- Commit b1fc исправлена утечка памяти динамических строк для RT
- Commit 517b рефакторинг grouper
- Commit b1fc небольшой рефакторинг (c++11 c-трушки, некоторые переразметки)
- Commit 7034 рефакторинг ISphMatchComparator для версии с подсчётом ссылок
- Commit b1fc приватизация клонировщика
- Commit efbc упрощение native little-endian для MVA_UPSIZE, DOCINFO2ID_T, DOCINFOSETID
- Commit 6da0 добавлена поддержка valgrind в ubertests
- Commit 1d17 исправлен сбой из-за гонки флага 'success' при подключении
- Commit 5a09 переключен epoll на режим edge-triggered
- Commit 5d52 исправлен оператор IN в выражении с форматированием как у фильтра
- Commit bd8b исправлен сбой в RT индексе при коммите документа с большим docid
- Commit ce65 исправлены опции без аргументов в indextool
- Commit 08c9 исправлена утечка памяти расширенного ключевого слова
- Commit 30c7 исправлена утечка памяти json grouper
- Commit 6023 исправлена утечка глобальных пользовательских переменных
- Commit 7c13 исправлена утечка динамических строк при раннем отклонении matches
- Commit 9154 исправлена утечка при length(
) - Commit 43fc исправлена утечка памяти из-за strdup() в парсере
- Commit 71ff исправлен рефакторинг парсера выражений для точного соблюдения подсчёта ссылок
- совместимость с клиентами MySQL 8
- TRUNCATE С ПЕРЕОПРЕДЕЛЕНИЕМ
- снят счетчик памяти на SHOW STATUS для RT индексов
- глобальный кэш для нескольких агентов
- улучшен IOCP на Windows
- VIP соединения для HTTP протокола
- Manticore SQL DEBUG команда, которая может выполнять различные подкоманды
- shutdown_token - SHA1 хэш пароля, необходимый для вызова
shutdownс использованием команды DEBUG - новые статистики для SHOW AGENT STATUS (_ping, _has_perspool, _need_resolve)
- опция --verbose индексатора теперь принимает [debugvv] для печати отладочных сообщений
- Commit 3900 убрал wlock при оптимизации
- Commit 4c33 исправил wlock при перезагрузке настроек индекса
- Commit b5ea исправил утечку памяти при запросе с фильтром JSON
- Commit 930e исправил пустые документы в наборе результатов PQ
- Commit 53de исправил путаницу задач из-за удаленной
- Commit cad9 исправил неправильный подсчет удаленных хостов
- Commit 9000 исправил утечку памяти разобранных дескрипторов агентов
- Commit 978d исправил утечку в поиске
- Commit 0193 косметические изменения в явных/встраиваемых c-trs, использование override/final
- Commit 943e исправил утечку json в локальной/удаленной схеме
- Commit 02db исправил утечку json сортировки колонки expr в локальной/удаленной схеме
- Commit c74d исправил утечку константного псевдонима
- Commit 6e5b исправил утечку потока предварительного чтения
- Commit 39c7 исправил зависание при выходе из-за зависшего ожидания в netloop
- Commit adaf исправил зависание поведения 'ping' при изменении HA агента на обычный хост
- Commit 32c4 отдельный gc для хранилища панели управления
- Commit 511a исправил исправление указателя с подсчетом ссылок
- Commit 32c4 исправил сбой indextool на несуществующем индексе
- Commit 156e исправил имя вывода превышающего атрибута/поля в индексации xmlpipe
- Commit cdac исправил значение индексатора по умолчанию, если в конфигурации нет секции индексатора
- Commit e61e исправил неправильные встроенные стоп-слова в дисковом чанке по RT индексу после перезапуска сервера
- Commit 5fba исправил пропуск фантомных (уже закрытых, но не окончательно удаленных из поллера) соединений
- Commit f22a исправил смешанные (сиротские) сетевые задачи
- Commit 4689 исправил сбой при чтении действия после записи
- Commit 03f9 исправил сбои searchd при запуске тестов на Windows
- Commit e925 исправил обработку кода EINPROGRESS при обычном connect()
- Commit 248b исправил тайм-ауты соединения при работе с TFO
- улучшена производительность подстановочных знаков при сопоставлении нескольких документов в PQ
- поддержка полных запросов в PQ
- поддержка MVA атрибутов в PQ
- поддержка regexp и RLP для индексов перколяторов
- Commit 6885 исправил потерю строки запроса
- Commit 0f17 исправил пустую информацию в операторе SHOW THREADS
- Commit 53fa исправил сбой при сопоставлении с оператором NOTNEAR
- Commit 2602 исправил сообщение об ошибке при плохом фильтре для удаления PQ
- уменьшено количество системных вызовов для снижения влияния патчей Meltdown и Spectre
- внутренняя переработка управления локальными индексами
- рефакторинг удаленных сниппетов
- полная перезагрузка конфигурации
- все соединения между узлами теперь независимы
- улучшения протокола
- коммуникация в Windows переключена с wsapoll на порты завершения ввода-вывода (IO completion ports)
- TFO можно использовать для связи между мастером и узлами
- SHOW STATUS теперь выводит версию сервера и mysql_version_string
- добавлена опция
docs_idдля документов, вызываемых в CALL PQ. - фильтр перколяционных запросов теперь может содержать выражения
- распределенные индексы могут работать с FEDERATED
- фиктивные SHOW NAMES COLLATE и
SET wait_timeout(для лучшей совместимости с ProxySQL)
- Коммит 5bcf исправлено добавление неравенства к тегам PQ
- Коммит 9ebc исправлено добавление поля id документа в JSON-документ оператора CALL PQ
- Коммит 8ae0 исправлена очистка обработчиков операторов для индекса PQ
- Коммит c24b исправлена фильтрация PQ по JSON и строковым атрибутам
- Коммит 1b8b исправлен разбор пустой JSON-строки
- Коммит 1ad8 исправлен сбой при мультизапросе с фильтрами OR
- Коммит 69b8 исправлена работа indextool для использования общего раздела конфигурации (опция lemmatizer_base) для команд (dumpheader)
- Коммит 6dbe исправлена пустая строка в наборе результатов и фильтре
- Коммит 39c4 исправлены отрицательные значения id документа
- Коммит 266b исправлена длина обрезки слова для очень длинных индексируемых слов
- Коммит 4782 исправлено сопоставление нескольких документов для запросов с подстановочными знаками в PQ
- Поддержка движка MySQL FEDERATED
- Пакеты MySQL теперь возвращают флаг SERVER_STATUS_AUTOCOMMIT, что повышает совместимость с ProxySQL
- listen_tfo - включение TCP Fast Open соединений для всех слушателей
- indexer --dumpheader может также выгружать заголовок RT из файла .meta
- скрипт сборки cmake для Ubuntu Bionic
- Коммит 355b исправлены неверные записи кэша запросов для RT-индекса;
- Коммит 546e исправлена потеря настроек индекса после бесшовной ротации
- Коммит 0c45 исправлена установка длины инфикса против префикса; добавлено предупреждение о неподдерживаемой длине инфикса
- Коммит 8054 исправлен порядок автоматической очистки RT-индексов
- Коммит 705d исправлены проблемы со схемой набора результатов для индекса с несколькими атрибутами и запросов к нескольким индексам
- Коммит b0ba исправлена потеря некоторых совпадений при пакетной вставке с дубликатами документов
- Коммит 4510 исправлена ошибка, когда оптимизация не могла объединить дисковые чанки RT-индекса с большим количеством документов
- jemalloc при компиляции. Если jemalloc присутствует в системе, его можно включить с помощью флага cmake
-DUSE_JEMALLOC=1
- Коммит 85a6 исправлено логирование опции expand_keywords в журнал SQL-запросов Manticore
- Коммит caaa исправлен интерфейс HTTP для корректной обработки запросов большого размера
- Коммит e386 исправлен сбой сервера при DELETE в RT-индекс с включенной опцией index_field_lengths
- Коммит cd53 исправлена работа опции командной строки searchd cpustats в неподдерживаемых системах
- Коммит 8740 исправлено сопоставление подстрок utf8 с определенными минимальными длинами
- улучшена производительность Percolate Queries при использовании оператора NOT и для пакетных документов.
- percolate_query_call может использовать несколько потоков в зависимости от dist_threads
- новый оператор полнотекстового соответствия NOTNEAR/N
- LIMIT для SELECT на перколяционных индексах
- expand_keywords может принимать значения 'start','exact' (где 'star,exact' имеет тот же эффект, что и '1')
- ranged-main-query для joined fields, который использует диапазонный запрос, определенный sql_query_range
- Коммит 72dc исправлен сбой при поиске по сегментам в оперативной памяти; взаимоблокировка при сохранении дискового чанка с двойным буфером; взаимоблокировка при сохранении дискового чанка во время оптимизации
- Коммит 3613 исправлен сбой индексатора на встроенной xml-схеме с пустым именем атрибута
- Коммит 48d7 исправлено ошибочное удаление pid-файла, не принадлежащего процессу
- Коммит a556 исправлены оставшиеся иногда во временной папке "осиротевшие" fifo-файлы
- Коммит 2376 исправлен пустой набор результатов FACET с неправильной строкой NULL
- Коммит 4842 исправлена проблема с блокировкой индекса при запуске сервера как службы Windows
- Коммит be35 исправлены неправильные библиотеки iconv на Mac OS
- Коммит 8374 исправлен неправильный count(*)
- agent_retry_count в случае агентов с зеркалами дает значение количества повторных попыток на зеркало, а не на агента; общее количество повторных попыток на агента равно agent_retry_count*зеркала.
- agent_retry_count теперь можно указывать для каждого индекса, переопределяя глобальное значение. Добавлен псевдоним mirror_retry_count.
- retry_count можно указать в определении агента, и значение представляет количество повторных попыток на агента
- Percolate Queries теперь доступны в HTTP JSON API по адресу /json/pq.
- Добавлены опции -h и -v (справка и версия) для исполняемых файлов
- Поддержка morphology_skip_fields для Real-Time индексов
- Коммит a40b исправлена работа ranged-main-query с sql_range_step при использовании на поле MVA
- Коммит f2f5 исправлена проблема с зависанием системного цикла blackhole и кажущимся отключением агентов blackhole
- Коммит 84e1 исправлен идентификатор запроса для обеспечения согласованности, исправлен дублирующийся идентификатор для сохраненных запросов
- Коммит 1948 исправлен сбой сервера при завершении работы из различных состояний
- Коммит 9a70 Коммит 3495 таймауты на длинные запросы
- Коммит 3359 рефакторинг сетевого опроса мастер-агента на системах, основанных на kqueue (Mac OS X, BSD).
- HTTP JSON: JSON-запросы теперь могут выполнять проверку равенства по атрибутам, MVA и JSON-атрибуты можно использовать при вставках и обновлениях, обновления и удаления через JSON API можно выполнять на распределенных индексах
- Percolate Queries
- Удалена поддержка 32-битных docid из кода. Также удален весь код, который преобразует/загружает устаревшие индексы с 32-битными docid.
- Морфология только для определенных полей. Новая директива индекса morphology_skip_fields позволяет определить список полей, для которых морфология не применяется.
- expand_keywords теперь может быть директивой времени выполнения запроса, устанавливаемой с помощью оператора OPTION
- Коммит 0cfa исправлен сбой в отладочной сборке сервера (и возможно неопределенное поведение в релизной) при сборке с rlp
- Коммит 3242 исправлена оптимизация RT-индекса с включенной опцией progressive, которая объединяет kill-листы в неправильном порядке
- Коммит ac0e незначительный сбой на Mac
- множество мелких исправлений после тщательного статического анализа кода
- другие мелкие исправления ошибок
В этом выпуске мы изменили внутренний протокол, используемый мастерами и агентами для взаимодействия друг с другом. В случае, если вы запускаете Manticoresearch в распределенной среде с несколькими экземплярами, убедитесь, что сначала обновляете агентов, а затем мастеров.
- JSON queries on HTTP API protocol. Supported search, insert, update, delete, replace operations. Data manipulation commands can be also bulked, also there are some limitations currently as MVA and JSON attributes can't be used for inserts, replaces or updates.
- RELOAD INDEXES command
- FLUSH LOGS command
- SHOW THREADS can show progress of optimize, rotation or flushes.
- GROUP N BY work correctly with MVA attributes
- blackhole agents are run on separate thread to not affect master query anymore
- implemented reference count on indexes, to avoid stalls caused by rotations and high load
- SHA1 hashing implemented, not exposed yet externally
- fixes for compiling on FreeBSD, macOS and Alpine
- Commit 9897 filter regression with block index
- Commit b1c3 rename PAGE_SIZE -> ARENA_PAGE_SIZE for compatibility with musl
- Commit f213 disable googletests for cmake < 3.1.0
- Commit f30e failed to bind socket on server restart
- Commit 0807 fixed crash of server on shutdown
- Commit 3e3a fixed show threads for system blackhole thread
- Commit 262c Refactored config check of iconv, fixes building on FreeBSD and Darwin
- OR operator in WHERE clause between attribute filters
- Maintenance mode ( SET MAINTENANCE=1)
- CALL KEYWORDS available on distributed indexes
- Grouping in UTC
- query_log_mode for custom log files permissions
- Field weights can be zero or negative
- max_query_time can now affect full-scans
- added net_wait_tm, net_throttle_accept and net_throttle_action for network thread fine tuning (in case of workers=thread_pool)
- COUNT DISTINCT works with facet searches
- IN can be used with JSON float arrays
- multi-query optimization is not broken anymore by integer/float expressions
- SHOW META shows a
multiplierrow when multi-query optimization is used
Manticore Search is built using cmake and the minimum gcc version required for compiling is 4.7.2.
- Manticore Search runs under
manticoreuser. - Default data folder is now
/var/lib/manticore/. - Default log folder is now
/var/log/manticore/. - Default pid folder is now
/var/run/manticore/.
- Commit a58c fixed SHOW COLLATION statement that breaks java connector
- Commit 631c fixed crashes on processing distributed indexes; added locks to distributed index hash; removed move and copy operators from agent
- Commit 942b fixed crashes on processing distributed indexes due to parallel reconnects
- Commit e5c1 fixed crash at crash handler on store query to server log
- Commit 4a4b fixed a crash with pooled attributes in multiqueries
- Commit 3873 fixed reduced core size by prevent index pages got included into core file
- Commit 11e6 fixed searchd crashes on startup when invalid agents are specified
- Commit 4ca6 fixed indexer reports error in sql_query_killlist query
- Commit 123a fixed fold_lemmas=1 vs hit count
- Commit cb99 fixed inconsistent behavior of html_strip
- Commit e406 fixed optimize rt index loose new settings; fixed optimize with sync option lock leaks;
- Commit 86ae fixed processing erroneous multiqueries
- Commit 2645 fixed result set depends on multi-query order
- Commit 7239 fixed server crash on multi-query with bad query
- Commit f353 fixed shared to exclusive lock
- Commit 3754 fixed server crash for query without indexes
- Commit 29f3 fixed dead lock of server
- Manticore branding
К сожалению, Manticore пока не на 100% свободен от ошибок, хотя команда разработчиков усердно работает над достижением этой цели. Со временем вы можете столкнуться с некоторыми проблемами. Очень важно сообщать как можно больше информации о каждой ошибке, чтобы исправить её эффективно. Чтобы исправить ошибку, её либо нужно воспроизвести и исправить, либо необходимо вывести причину на основе предоставленной вами информации. Для помощи в этом выполните следующие инструкции.
Ошибки и запросы на добавление функционала отслеживаются на Github. Вы можете создать новую задачу и подробно описать вашу ошибку, чтобы сэкономить время и себе, и разработчикам.
Обновления документации (текущего текста), также производятся на Github.
Manticore Search написан на C++, низкоуровневом языке программирования, который позволяет напрямую взаимодействовать с компьютером для более высокой производительности. Однако у этого подхода есть недостаток: в редких случаях невозможно корректно обработать ошибку, записав её в лог и проигнорировав команду, вызвавшую проблему. Вместо этого программа может аварийно завершиться, что приведёт к полному останову и необходимости перезапуска.
При сбое Manticore Search важно оповестить команду Manticore, оставив отчет об ошибке на GitHub или через профессиональный сервис Manticore в вашем личном хелпдеске. Команде Manticore потребуется следующая информация:
- Лог searchd
- Файл coredump
- Лог запросов
Дополнительно будет полезно, если вы сможете сделать следующее:
- Запустите gdb для анализа coredump:
gdb /usr/bin/searchd </path/to/coredump> - Найдите ID упавшего потока в имени файла coredump (убедитесь, что у вас есть
%pв /proc/sys/kernel/core_pattern), например,core.work_6.29050.server_name.1637586599означает thread_id=29050 - В gdb выполните:
set pagination off info threads # find thread number by it's id (e.g. for `LWP 29050` it will be thread number 8 thread apply all bt thread <thread number> bt full info locals quit - Предоставьте выводы
Если Manticore Search завис, необходимо собрать некоторую информацию, которая может помочь понять причину. Вот как это сделать:
- Выполните
show threads option format=allчерез VIP порт - Соберите вывод lsof, так как зависания могут быть вызваны слишком большим количеством соединений или открытых дескрипторов файлов.
lsof -p `cat /run/manticore/searchd.pid` - Создайте дамп памяти (core dump):
gcore `cat /run/manticore/searchd.pid`(Он будет сохранён в текущую директорию.)
- Установите и запустите gdb:
gdb /usr/bin/searchd `cat /run/manticore/searchd.pid`Обратите внимание, что это остановит запущенный searchd, но если он уже завис, это не проблема.
- В gdb выполните:
set pagination off info threads thread apply all bt quit - Соберите все выводы и файлы и предоставьте их в отчёте об ошибке.
Для экспертов: макросы, добавленные в этот коммит, могут быть полезны при отладке.
- Убедитесь, что вы запускаете searchd с
--coredump. Чтобы не менять скрипты, вы можете использовать метод https://manual.manticoresearch.com/Starting_the_server/Linux#Custom-startup-flags-using-systemd. Например::
[root@srv lib]# systemctl set-environment _ADDITIONAL_SEARCHD_PARAMS='--coredump'
[root@srv lib]# systemctl restart manticore
[root@srv lib]# ps aux|grep searchd
mantico+ 1955 0.0 0.0 61964 1580 ? S 11:02 0:00 /usr/bin/searchd --config /etc/manticoresearch/manticore.conf --coredump
mantico+ 1956 0.6 0.0 392744 2664 ? Sl 11:02 0:00 /usr/bin/searchd --config /etc/manticoresearch/manticore.conf --coredump-
Убедитесь, что ваша операционная система позволяет сохранять дампы памяти, проверив, что:
/proc/sys/kernel/core_patternне пуст. Это путь, куда будут сохраняться core dumps. Чтобы сохранить дампы памяти в файл, напримерcore.searchd.1773.centos-4gb-hel1-1.1636454937, выполните следующую команду:echo "/cores/core.%e.%p.%h.%t" > /proc/sys/kernel/core_pattern -
searchd должен запускаться с
ulimit -c unlimited. Если вы запускаете Manticore через systemctl, лимит автоматически устанавливается в бесконечность, что указано в manticore.service строке:[root@srv lib]# grep CORE /lib/systemd/system/manticore.service LimitCORE=infinity
Manticore Search и Manticore Columnar Library написаны на C++, что приводит к созданию скомпилированных бинарных файлов, оптимально работающих на вашей операционной системе. Однако при запуске бинарника ваша ОС не имеет полного доступа к именам переменных, функций, методов и классов. Эта информация содержится в отдельных пакетах "debuginfo" или "symbol".
Отладочные символы необходимы для устранения неисправностей и отладки, так как позволяют визуализировать состояние системы в момент сбоя, включая имена функций. Manticore Search предоставляет трассировку в логе searchd и создает coredump, если работает с флагом --coredump. Без символов вы увидите только внутренние смещения, что затруднит или сделает невозможным декодирование причины сбоя. Если вам нужно составить отчет об ошибке по поводу сбоя, команда Manticore часто потребует отладочные символы для помощи.
Чтобы установить отладочные символы для Manticore Search/Manticore Columnar Library, вам нужно установить пакет *debuginfo* для CentOS, пакет *dbgsym* для Ubuntu и Debian или пакет *dbgsymbols* для Windows и macOS. Эти пакеты должны соответствовать версии установленного Manticore. Например, если вы установили Manticore Search в CentOS 8 из пакета https://repo.manticoresearch.com/repository/manticoresearch/release/centos/8/x86_64/manticore-4.0.2_210921.af497f245-1.el8.x86_64.rpm, соответствующий пакет с символами будет https://repo.manticoresearch.com/repository/manticoresearch/release/centos/8/x86_64/manticore-debuginfo-4.0.2_210921.af497f245-1.el8.x86_64.rpm
Обратите внимание, что оба пакета имеют одинаковый commit id af497f245, соответствующий коммиту, из которого была собрана эта версия.
Если вы установили Manticore из APT/YUM репозитория, вы можете использовать один из следующих инструментов:
debuginfo-installв CentOS 7dnf debuginfo-installв CentOS 8find-dbgsym-packagesв Debian и Ubuntu
чтобы найти пакет с отладочными символами.
- Найдите build ID в выводе команды
file /usr/bin/searchd:
[root@srv lib]# file /usr/bin/searchd
/usr/bin/searchd: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=2c582e9f564ea1fbeb0c68406c271ba27034a6d3, strippedВ данном случае build ID — 2c582e9f564ea1fbeb0c68406c271ba27034a6d3.
- Найдите символы в
/usr/lib/debug/.build-idследующим образом:
[root@srv ~]# ls -la /usr/lib/debug/.build-id/2c/582e9f564ea1fbeb0c68406c271ba27034a6d3*
lrwxrwxrwx. 1 root root 23 Nov 9 10:42 /usr/lib/debug/.build-id/2c/582e9f564ea1fbeb0c68406c271ba27034a6d3 -> ../../../../bin/searchd
lrwxrwxrwx. 1 root root 27 Nov 9 10:42 /usr/lib/debug/.build-id/2c/582e9f564ea1fbeb0c68406c271ba27034a6d3.debug -> ../../usr/bin/searchd.debugЧтобы исправить ошибку, разработчикам часто необходимо воспроизвести её локально. Для этого им нужны ваш конфигурационный файл, файлы таблиц, бинарный лог (если есть), а иногда исходные данные (например, данные из внешних хранилищ или XML/CSV файлы) и запросы.
Приложите ваши данные при создании тикета на Github. Если данные слишком большие или конфиденциальные, вы можете загрузить их в наше хранилище S3 только для записи по адресу s3://s3.manticoresearch.com/write-only/.
Чтобы сделать это легко, мы предоставляем механизм загрузки с использованием Docker-образа. Этот образ создан из нашего открытого репозитория на github.com/manticoresoftware/s3-upload и помогает вам легко загружать данные в хранилище S3 Manticore только для записи. Вот как вы можете это сделать:
- Перейдите в каталог, содержащий файлы, которые вы хотите загрузить, и выполните:
docker run -it --rm -v $(pwd):/upload manticoresearch/upload - Это:
- Попросит вас ввести URL/номер связанного issue
- Загрузит все файлы в текущем каталоге в наше хранилище S3 только для записи
- В конце вы увидите путь загрузки. Пожалуйста, поделитесь этим путем с разработчиками.
- Example
docker run -it --rm -v $(pwd):/upload manticoresearch/upload🚀 Welcome to Manticore Search Upload Tool! 🚀
📂 Files to be uploaded:
tt (800)
🔗 Please enter the related issue URL/number
(e.g., https://github.com/manticoresoftware/manticoresearch/issues/123 or just 123):
123
📤 Starting upload process...
INFO: Cache file not found or empty, creating/populating it.
INFO: Compiling list of local files...
INFO: Running stat() and reading/calculating MD5 values on 23 files, this may take some time...
INFO: Summary: 23 local files to upload
upload: './tt/tt.0.spa' -> 's3://write-only/issue-20250219-123/tt/tt.0.spa' [1 of 23]
40 of 40 100% in 2s 15.03 B/s done
upload: './tt/tt.0.spd' -> 's3://write-only/issue-20250219-123/tt/tt.0.spd' [2 of 23]
1 of 1 100% in 0s 1.99 B/s done
upload: './tt/tt.0.spe' -> 's3://write-only/issue-20250219-123/tt/tt.0.spe' [3 of 23]
1 of 1 100% in 0s 2.02 B/s done
upload: './tt/tt.0.sph' -> 's3://write-only/issue-20250219-123/tt/tt.0.sph' [4 of 23]
420 of 420 100% in 0s 895.32 B/s done
upload: './tt/tt.0.sphi' -> 's3://write-only/issue-20250219-123/tt/tt.0.sphi' [5 of 23]
66 of 66 100% in 0s 142.67 B/s done
upload: './tt/tt.0.spi' -> 's3://write-only/issue-20250219-123/tt/tt.0.spi' [6 of 23]
18 of 18 100% in 0s 39.13 B/s done
upload: './tt/tt.0.spidx' -> 's3://write-only/issue-20250219-123/tt/tt.0.spidx' [7 of 23]
145 of 145 100% in 0s 313.38 B/s done
upload: './tt/tt.0.spm' -> 's3://write-only/issue-20250219-123/tt/tt.0.spm' [8 of 23]
4 of 4 100% in 0s 8.36 B/s done
upload: './tt/tt.0.spp' -> 's3://write-only/issue-20250219-123/tt/tt.0.spp' [9 of 23]
1 of 1 100% in 0s 2.15 B/s done
upload: './tt/tt.0.spt' -> 's3://write-only/issue-20250219-123/tt/tt.0.spt' [10 of 23]
36 of 36 100% in 0s 78.35 B/s done
upload: './tt/tt.1.spa' -> 's3://write-only/issue-20250219-123/tt/tt.1.spa' [11 of 23]
48 of 48 100% in 0s 81.35 B/s done
upload: './tt/tt.1.spd' -> 's3://write-only/issue-20250219-123/tt/tt.1.spd' [12 of 23]
1 of 1 100% in 0s 1.65 B/s done
upload: './tt/tt.1.spe' -> 's3://write-only/issue-20250219-123/tt/tt.1.spe' [13 of 23]
1 of 1 100% in 0s 1.95 B/s done
upload: './tt/tt.1.sph' -> 's3://write-only/issue-20250219-123/tt/tt.1.sph' [14 of 23]
420 of 420 100% in 0s 891.58 B/s done
upload: './tt/tt.1.sphi' -> 's3://write-only/issue-20250219-123/tt/tt.1.sphi' [15 of 23]
82 of 82 100% in 0s 166.42 B/s done
upload: './tt/tt.1.spi' -> 's3://write-only/issue-20250219-123/tt/tt.1.spi' [16 of 23]
18 of 18 100% in 0s 39.46 B/s done
upload: './tt/tt.1.spidx' -> 's3://write-only/issue-20250219-123/tt/tt.1.spidx' [17 of 23]
183 of 183 100% in 0s 374.04 B/s done
upload: './tt/tt.1.spm' -> 's3://write-only/issue-20250219-123/tt/tt.1.spm' [18 of 23]
4 of 4 100% in 0s 8.42 B/s done
upload: './tt/tt.1.spp' -> 's3://write-only/issue-20250219-123/tt/tt.1.spp' [19 of 23]
1 of 1 100% in 0s 1.28 B/s done
upload: './tt/tt.1.spt' -> 's3://write-only/issue-20250219-123/tt/tt.1.spt' [20 of 23]
50 of 50 100% in 1s 34.60 B/s done
upload: './tt/tt.lock' -> 's3://write-only/issue-20250219-123/tt/tt.lock' [21 of 23]
0 of 0 0% in 0s 0.00 B/s done
upload: './tt/tt.meta' -> 's3://write-only/issue-20250219-123/tt/tt.meta' [22 of 23]
456 of 456 100% in 0s 923.34 B/s done
upload: './tt/tt.settings' -> 's3://write-only/issue-20250219-123/tt/tt.settings' [23 of 23]
3 of 3 100% in 0s 6.41 B/s done
✅ Upload complete!
📋 Please share this path with the developers:
issue-20250219-123
💡 Tip: Make sure to include this path when communicating with the Manticore teamВ качестве альтернативы вы можете использовать S3 клиент Minio или инструмент Amazon s3cmd для того же самого, например:
- Установите клиент https://min.io/docs/minio/linux/reference/minio-mc.html#install-mc
Например, на 64-битном Linux:
curl https://dl.min.io/client/mc/release/linux-amd64/mc \ --create-dirs \ -o $HOME/minio-binaries/mc chmod +x $HOME/minio-binaries/mc export PATH=$PATH:$HOME/minio-binaries/ - Добавьте наш хост s3 (используйте полный путь к исполняемому файлу или перейдите в его каталог):
cd $HOME/minio-binariesи затем./mc alias set manticore http://s3.manticoresearch.com:9000 manticore manticore - Скопируйте ваши файлы (используйте полный путь к исполняемому файлу или перейдите в его каталог):
cd $HOME/minio-binariesи затем./mc cp -r issue-1234/ manticore/write-only/issue-1234. Убедитесь, что имя папки уникально, и лучше всего, если оно соответствует issue на GitHub, где вы описали ошибку.
DEBUG [ subcommand ]Оператор DEBUG предназначен для разработчиков и тестировщиков для вызова различных внутренних или VIP-команд. Однако он не предназначен для использования в рабочей среде, так как синтаксис компонента subcommand может свободно меняться в любой сборке.
Чтобы просмотреть список полезных команд и подкоманд оператора DEBUG, доступных в текущем контексте, просто вызовите DEBUG без параметров.
mysql> debug;
+-------------------------------------------------------------------------+----------------------------------------------------------------------------------------+
| command | meaning |
+-------------------------------------------------------------------------+----------------------------------------------------------------------------------------+
| flush logs | emulate USR1 signal |
| reload indexes | emulate HUP signal |
| debug token <password> | calculate token for password |
| debug malloc_stats | perform 'malloc_stats', result in searchd.log |
| debug malloc_trim | pefrorm 'malloc_trim' call |
| debug sleep <N> | sleep for <N> seconds |
| debug tasks | display global tasks stat (use select from @@system.tasks instead) |
| debug sched | display task manager schedule (use select from @@system.sched instead) |
| debug merge <TBL> [chunk] <X> [into] [chunk] <Y> [option sync=1,byid=0] | For RT table <TBL> merge disk chunk X into disk chunk Y |
| debug drop [chunk] <X> [from] <TBL> [option sync=1] | For RT table <TBL> drop disk chunk X |
| debug files <TBL> [option format=all|external] | list files belonging to <TBL>. 'all' - including external (wordforms, stopwords, etc.) |
| debug close | ask server to close connection from it's side |
| debug compress <TBL> [chunk] <X> [option sync=1] | Compress disk chunk X of RT table <TBL> (wipe out deleted documents) |
| debug split <TBL> [chunk] <X> on @<uservar> [option sync=1] | Split disk chunk X of RT table <TBL> using set of DocIDs from @uservar |
| debug wait <cluster> [like 'xx'] [option timeout=3] | wait <cluster> ready, but no more than 3 secs. |
| debug wait <cluster> status <N> [like 'xx'] [option timeout=13] | wait <cluster> commit achieve <N>, but no more than 13 secs |
| debug meta | Show max_matches/pseudo_shards. Needs set profiling=1 |
| debug trace OFF|'path/to/file' [<N>] | trace flow to file until N bytes written, or 'trace OFF' |
| debug curl <URL> | request given url via libcurl |
+-------------------------------------------------------------------------+----------------------------------------------------------------------------------------+
19 rows in set (0.00 sec)То же самое из VIP-подключения:
mysql> debug;
+-------------------------------------------------------------------------+----------------------------------------------------------------------------------------+
| command | meaning |
+-------------------------------------------------------------------------+----------------------------------------------------------------------------------------+
| flush logs | emulate USR1 signal |
| reload indexes | emulate HUP signal |
| debug shutdown <password> | emulate TERM signal |
| debug crash <password> | crash daemon (make SIGSEGV action) |
| debug token <password> | calculate token for password |
| debug malloc_stats | perform 'malloc_stats', result in searchd.log |
| debug malloc_trim | pefrorm 'malloc_trim' call |
| debug procdump | ask watchdog to dump us |
| debug setgdb on|off | enable or disable potentially dangerous crash dumping with gdb |
| debug setgdb status | show current mode of gdb dumping |
| debug sleep <N> | sleep for <N> seconds |
| debug tasks | display global tasks stat (use select from @@system.tasks instead) |
| debug sched | display task manager schedule (use select from @@system.sched instead) |
| debug merge <TBL> [chunk] <X> [into] [chunk] <Y> [option sync=1,byid=0] | For RT table <TBL> merge disk chunk X into disk chunk Y |
| debug drop [chunk] <X> [from] <TBL> [option sync=1] | For RT table <TBL> drop disk chunk X |
| debug files <TBL> [option format=all|external] | list files belonging to <TBL>. 'all' - including external (wordforms, stopwords, etc.) |
| debug close | ask server to close connection from it's side |
| debug compress <TBL> [chunk] <X> [option sync=1] | Compress disk chunk X of RT table <TBL> (wipe out deleted documents) |
| debug split <TBL> [chunk] <X> on @<uservar> [option sync=1] | Split disk chunk X of RT table <TBL> using set of DocIDs from @uservar |
| debug wait <cluster> [like 'xx'] [option timeout=3] | wait <cluster> ready, but no more than 3 secs. |
| debug wait <cluster> status <N> [like 'xx'] [option timeout=13] | wait <cluster> commit achieve <N>, but no more than 13 secs |
| debug meta | Show max_matches/pseudo_shards. Needs set profiling=1 |
| debug trace OFF|'path/to/file' [<N>] | trace flow to file until N bytes written, or 'trace OFF' |
| debug curl <URL> | request given url via libcurl |
+-------------------------------------------------------------------------+----------------------------------------------------------------------------------------+
24 rows in set (0.00 sec)Все команды debug XXX следует рассматривать как нестабильные и подверженные изменениям в любое время, так что не удивляйтесь, если они изменятся. Этот пример вывода может не отражать реально доступные команды, поэтому попробуйте это на своей системе, чтобы увидеть, что доступно на вашем экземпляре. Кроме того, подробная документация, помимо этой короткой колонки 'meaning', не предоставляется.
В качестве краткой иллюстрации ниже описаны две команды, доступные только VIP-клиентам — shutdown и crash. Обе требуют токен, который можно сгенерировать с помощью подкоманды debug token, и добавить его в параметр shutdown_token в секции searchd конфигурационного файла. Если такой секции не существует или предоставленный хеш пароля не совпадает с токеном, хранящимся в конфиге, подкоманды ничего не сделают.
mysql> debug token hello;
+-------------+------------------------------------------+
| command | result |
+-------------+------------------------------------------+
| debug token | aaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d |
+-------------+------------------------------------------+
1 row in set (0,00 sec)Подкоманда shutdown отправит сигнал TERM серверу, вызывая его завершение работы. Это может быть опасно, так как никто не хочет случайно остановить рабочую службу. Поэтому она требует VIP-подключения и пароля для использования.
Подкоманда crash буквально вызывает крах. Она может использоваться для целей тестирования, например, чтобы проверить, как системный менеджер поддерживает жизнеспособность службы, или проверить возможность отслеживания дампов памяти.
Если некоторые команды окажутся полезными в более общем контексте, они могут быть перемещены из подкоманд debug в более стабильное и общее место (как показано на примере debug tasks и debug sched в таблице).
- CREATE TABLE - Создает новую таблицу
- CREATE TABLE LIKE - Создает таблицу, используя другую как шаблон
- CREATE TABLE LIKE ... WITH DATA - Копирует таблицу
- CREATE SOURCE - Создает источник потребителя Kafka
- CREATE MATERIALIZED VIEW - Трансформация данных из сообщений Kafka
- CREATE MV - То же, что и предыдущая
- DESCRIBE - Выводит список полей таблицы и их типы
- ALTER TABLE - Изменяет схему / настройки таблицы
- ALTER TABLE REBUILD SECONDARY - Обновляет/восстанавливает вторичные индексы
- ALTER TABLE type='distributed' - Обновляет/восстанавливает вторичные индексы
- ALTER TABLE RENAME
- ALTER MATERIALIZED VIEW {name} suspended=1 - Приостанавливает или возобновляет потребление из источника Kafka
- DROP TABLE IF EXISTS - Удаляет таблицу (если она существует)
- SHOW TABLES - Показывает список таблиц
- SHOW SOURCES - Показывает список источников Kafka
- SHOW MATERIALIZED VIEWS - Показывает список материализованных представлений
- SHOW MVS - Псевдоним предыдущей команды
- SHOW CREATE TABLE - Показывает SQL-команду для создания таблицы
- SHOW TABLE INDEXES - Показывает информацию о доступных вторичных индексах для таблицы
- SHOW TABLE STATUS - Показывает информацию о текущем состоянии таблицы
- SHOW TABLE SETTINGS - Показывает настройки таблицы
- SHOW LOCKS - Показывает информацию о замороженных таблицах
- INSERT - Добавляет новые документы
- REPLACE - Заменяет существующие документы новыми
- REPLACE .. SET - Заменяет одно или несколько полей в таблице
- UPDATE - Выполняет обновление на месте в документах
- DELETE - Удаляет документы
- TRUNCATE TABLE - Удаляет все документы из таблицы
- BACKUP - Создает резервные копии ваших таблиц
- SELECT - Поиск
- WHERE - Фильтры
- GROUP BY - Группирует результаты поиска
- GROUP BY ORDER - Сортирует группы
- GROUP BY HAVING - Фильтрует группы
- OPTION - Опции запроса
- FACET - Фасетный поиск
- SUB-SELECTS - Об использовании подзапросов SELECT
- JOIN - Объединение таблиц в SELECT
- EXPLAIN QUERY - Показывает план выполнения запроса без его запуска
- SHOW META - Показывает расширенную информацию о выполненном запросе
- SHOW PROFILE - Показывает профилирование выполненного запроса
- SHOW PLAN - Показывает план выполнения запроса после его выполнения
- SHOW WARNINGS - Показывает предупреждения последнего запроса
- FLUSH ATTRIBUTES - Принудительно сбрасывает обновленные атрибуты на диск
- FLUSH HOSTNAMES - Обновляет IP-адреса, связанные с именами хостов агентов
- FLUSH LOGS - Инициирует переоткрытие файлов логов searchd и запросов (аналогично USR1)
- FLUSH RAMCHUNK - Принудительно создает новый диск
- FLUSH TABLE - Сбрасывает RAM-чанк таблицы реального времени на диск
- OPTIMIZE TABLE - Помещает таблицу реального времени в очередь на оптимизацию
- ATTACH TABLE - Переносит данные из обычной таблицы в таблицу реального времени
- IMPORT TABLE - Импортирует ранее созданную таблицу RT или PQ в сервер, работающий в режиме RT
- JOIN CLUSTER - Присоединяется к кластеру репликации
- ALTER CLUSTER - Добавляет/удаляет таблицу в кластере репликации
- SET CLUSTER - Изменяет настройки кластера репликации
- DELETE CLUSTER - Удаляет кластер репликации
- RELOAD TABLE - Вращает простую таблицу
- RELOAD TABLES - Вращает все простые таблицы
- CALL SUGGEST, CALL QSUGGEST - Предлагает слова с исправлением орфографии
- CALL SNIPPETS - Создаёт фрагмент с подсветкой результатов из предоставленных данных и запроса
- CALL PQ - Выполняет перколяционный запрос
- CALL KEYWORDS - Используется для проверки токенизации ключевых слов. Также позволяет получить токенизированные формы предоставленных ключевых слов
- CALL AUTOCOMPLETE - Автозаполняет ваш поисковый запрос
- CREATE FUNCTION - Устанавливает пользовательскую функцию (UDF)
- DROP FUNCTION - Удаляет пользовательскую функцию (UDF)
- CREATE PLUGIN - Устанавливает плагин
- CREATE BUDDY PLUGIN - Устанавливает плагин Buddy
- DROP PLUGIN - Удаляет плагин
- DROP BUDDY PLUGIN - Удаляет плагин Buddy
- RELOAD PLUGINS - Перезагружает все плагины из заданной библиотеки
- ENABLE BUDDY PLUGIN - Реактивирует ранее отключённый плагин Buddy
- DISABLE BUDDY PLUGIN - Деактивирует активный плагин Buddy
- SHOW STATUS - Отображает ряд полезных счетчиков производительности
- SHOW THREADS - Перечисляет все текущие активные потоки клиентов
- SHOW VARIABLES - Перечисляет переменные сервера и их значения
- SHOW VERSION - Предоставляет подробную информацию о версиях различных компонентов инстанса.
- /sql - Выполняет SQL-запрос через HTTP JSON
- /cli - Обеспечивает HTTP интерфейс командной строки
- /insert - Вставляет документ в таблицу реального времени
- /pq/tbl_name/doc - Добавляет правило PQ в перколяционную таблицу
- /update - Обновляет документ в таблице реального времени
- /replace - Заменяет существующий документ в таблице реального времени или вставляет его, если он не существует
- /pq/tbl_name/doc/N?refresh=1 - Заменяет правило PQ в перколяционной таблице
- /delete - Удаляет документ из таблицы
- /bulk - Выполняет несколько операций вставки, обновления или удаления за один вызов. Подробнее о массовых вставках здесь.
- /search - Выполняет поиск
- /search -> knn - Выполняет KNN векторный поиск
- /pq/tbl_name/search - Выполняет обратный поиск в перколяционной таблице
- /tbl_name/_mapping - Создаёт схему таблицы в стиле Elasticsearch
- access_plain_attrs
- access_blob_attrs
- access_doclists
- access_hitlists
- access_dict
- attr_update_reserve
- bigram_delimiter
- bigram_freq_words
- bigram_index
- blend_chars
- blend_mode
- charset_table
- dict
- docstore_block_size
- docstore_compression
- docstore_compression_level
- embedded_limit
- exceptions
- exceptions_list
- expand_keywords
- global_idf
- hitless_words
- hitless_words_list
- html_index_attrs
- html_remove_elements
- html_strip
- ignore_chars
- index_exact_words
- index_field_lengths
- index_sp
- index_token_filter
- index_zones
- infix_fields
- inplace_enable
- inplace_hit_gap
- inplace_reloc_factor
- inplace_write_factor
- jieba_hmm
- jieba_mode
- jieba_user_dict_path
- killlist_target
- max_substring_len
- min_infix_len
- min_prefix_len
- min_stemming_len
- min_word_len
- morphology
- morphology_skip_fields
- ngram_chars
- ngram_len
- overshort_step
- path
- phrase_boundary
- phrase_boundary_step
- prefix_fields
- preopen
- read_buffer_docs
- read_buffer_hits
- regexp_filter
- stopwords
- stopwords_list
- stopword_step
- stopwords_unstemmed
- type
- wordforms
- wordforms_list
- local
- agent
- agent_connect_timeout
- agent_blackhole
- agent_persistent
- agent_query_timeout
- agent_retry_count
- ha_strategy
- mirror_retry_count
- rt_attr_bigint
- rt_attr_bool
- rt_attr_float
- rt_attr_float_vector
- rt_attr_json
- rt_attr_multi_64
- rt_attr_multi
- rt_attr_string
- rt_attr_timestamp
- rt_attr_uint
- rt_field
- rt_mem_limit
- diskchunk_flush_write_timeout
- diskchunk_flush_search_timeout
- OR
- MAYBE
- NOT - оператор NOT
- @field - оператор поиска по полю
- @field[N] - модификатор ограничения позиции поля
- @(field1,field2,...) - оператор поиска по нескольким полям
- @!field - оператор игнорирования поля при поиске
- @!(field1,field2,...) - оператор игнорирования нескольких полей при поиске
- @* - оператор поиска по всем полям
- "word1 word2 ... " - оператор поиска фразы
- "word1 word2 ... "~N - оператор поиска по близости
- "word1 word2 ... "/N - оператор кворумного соответствия
- word1 << word2 << word3 - оператор строгого порядка
- =word1 - модификатор точной формы
- ^word1 - модификатор начала поля
- word2$ - модификатор конца поля
- word^N - модификатор усиления по IDF для ключевого слова
- word1 NEAR/N word2 - оператор NEAR, обобщенный оператор близости
- word1 NOTNEAR/N word2 - оператор NOTNEAR, оператор отрицательного утверждения
- word1 PARAGRAPH word2 PARAGRAPH "word3 word4" - оператор PARAGRAPH
- word1 SENTENCE word2 SENTENCE "word3 word4" - оператор SENTENCE
- ZONE:(h3,h4) - оператор ограничения по ZONE
- ZONESPAN:(h2) - оператор ограничения по ZONESPAN
- @@relaxed - подавляет ошибки об отсутствующих полях
- t?st - операторы подстановки
- REGEX(/pattern/) - оператор REGEX
- ABS() - Возвращает абсолютное значение
- ATAN2() - Возвращает арктангенс от двух аргументов
- BITDOT() - Возвращает сумму произведений каждого бита маски на его вес
- CEIL() - Возвращает наименьшее целое значение, большее или равное аргументу
- COS() - Возвращает косинус аргумента
- CRC32() - Возвращает значение CRC32 аргумента
- EXP() - Возвращает экспоненту аргумента
- FIBONACCI() - Возвращает N-е число Фибоначчи, где N - целочисленный аргумент
- FLOOR() - Возвращает наибольшее целое значение, меньшее или равное аргументу
- GREATEST() - Принимает JSON/MVA массив в качестве аргумента и возвращает наибольшее значение в этом массиве
- IDIV() - Возвращает результат целочисленного деления первого аргумента на второй аргумент
- LEAST() - Принимает JSON/MVA массив в качестве аргумента и возвращает наименьшее значение в этом массиве
- LN() - Возвращает натуральный логарифм аргумента
- LOG10() - Возвращает десятичный логарифм аргумента
- LOG2() - Возвращает двоичный логарифм аргумента
- MAX() - Возвращает больший из двух аргументов
- MIN() - Возвращает меньший из двух аргументов
- POW() - Возвращает первый аргумент, возведенный в степень второго аргумента
- RAND() - Возвращает случайное число с плавающей точкой от 0 до 1
- SIN() - Возвращает синус аргумента
- SQRT() - Возвращает квадратный корень аргумента
- BM25F() - Возвращает точное значение формулы BM25F
- EXIST() - Заменяет несуществующие столбцы значениями по умолчанию
- GROUP_CONCAT() - Создает список значений атрибутов всех документов в группе, разделенный запятыми
- HIGHLIGHT() - Подсвечивает результаты поиска
- MIN_TOP_SORTVAL() - Возвращает значение ключа сортировки худшего найденного элемента в текущих top-N совпадениях
- MIN_TOP_WEIGHT() - Возвращает вес худшего найденного элемента в текущих top-N совпадениях
- PACKEDFACTORS() - Выводит весовые коэффициенты
- REMOVE_REPEATS() - Удаляет повторяющиеся скорректированные строки с одинаковым значением 'column'
- WEIGHT() - Возвращает оценку полнотекстового совпадения
- ZONESPANLIST() - Возвращает пары совпавших зонных интервалов
- QUERY() - Возвращает текущий полнотекстовый запрос
- BIGINT() - Принудительно преобразует целочисленный аргумент к 64-битному типу
- DOUBLE() - Принудительно преобразует заданный аргумент к типу с плавающей точкой
- INTEGER() - Принудительно преобразует заданный аргумент к 64-битному знаковому типу
- TO_STRING() - Принудительно преобразует аргумент к строковому типу
- UINT() - Преобразует заданный аргумент к 32-битному беззнаковому целочисленному типу
- UINT64() - Преобразует заданный аргумент к 64-битному беззнаковому целочисленному типу
- SINT() - Интерпретирует 32-битное беззнаковое целое как 64-битное знаковое целое
- ALL() - Возвращает 1, если условие истинно для всех элементов массива
- ANY() - Возвращает 1, если условие истинно для любого элемента массива
- CONTAINS() - Проверяет, находится ли точка (x,y) внутри заданного полигона
- IF() - Проверяет, равен ли первый аргумент 0.0, возвращает второй аргумент, если он не равен нулю, или третий, если равен
- IN() - Возвращает 1, если первый аргумент равен любому из остальных аргументов, или 0 в противном случае
- INDEXOF() - Перебирает все элементы массива и возвращает индекс первого совпадающего элемента
- INTERVAL() - Возвращает индекс аргумента, который меньше первого аргумента
- LENGTH() - Возвращает количество элементов в MVA
- REMAP() - Позволяет создавать исключения для значений выражения в зависимости от значений условия
- NOW() - Возвращает текущую метку времени как INTEGER
- CURTIME() - Возвращает текущее время в локальном часовом поясе
- CURDATE() - Возвращает текущую дату в локальном часовом поясе
- UTC_TIME() - Возвращает текущее время в часовом поясе UTC
- UTC_TIMESTAMP() - Возвращает текущую дату/время в часовом поясе UTC
- SECOND() - Возвращает целую секунду из аргумента метки времени
- MINUTE() - Возвращает целую минуту из аргумента метки времени
- HOUR() - Возвращает целый час из аргумента метки времени
- DAY() - Возвращает целый день из аргумента метки времени
- MONTH() - Возвращает целый месяц из аргумента метки времени
- QUARTER() - Возвращает целый квартал года из аргумента метки времени
- YEAR() - Возвращает целый год из аргумента метки времени
- DAYNAME() - Возвращает название дня недели для заданного аргумента метки времени
- MONTHNAME() - Возвращает название месяца для заданного аргумента метки времени
- DAYOFWEEK() - Возвращает целочисленный индекс дня недели для заданного аргумента метки времени
- DAYOFYEAR() - Возвращает целочисленный день года для заданного аргумента метки времени
- YEARWEEK() - Возвращает целый год и код дня первого дня текущей недели для заданного аргумента метки времени
- YEARMONTH() - Возвращает целый год и код месяца из аргумента метки времени
- YEARMONTHDAY() - Возвращает целый год, месяц и код дня из аргумента метки времени
- TIMEDIFF() - Возвращает разницу между метками времени
- DATEDIFF() - Возвращает количество дней между двумя заданными метками времени
- DATE() - Форматирует часть даты из аргумента метки времени
- TIME() - Форматирует часть времени из аргумента метки времени
- DATE_FORMAT() - Возвращает форматированную строку на основе предоставленных аргументов даты и формата
- GEODIST() - Вычисляет расстояние по геосфере между двумя заданными точками
- GEOPOLY2D() - Создает полигон, учитывающий кривизну Земли
- POLY2D() - Создает простой полигон в плоском пространстве
- CONCAT() - Объединяет две или более строк
- REGEX() - Возвращает 1, если регулярное выражение совпало со строкой атрибута, и 0 в противном случае
- SNIPPET() - Подсвечивает результаты поиска
- SUBSTRING_INDEX() - Возвращает подстроку строки до указанного количества вхождений разделителя
- CONNECTION_ID() - Возвращает идентификатор текущего соединения
- KNN_DIST() - Возвращает расстояние поиска по векторам KNN
- LAST_INSERT_ID() - Возвращает идентификаторы документов, вставленных или замененных последним оператором в текущей сессии
- UUID_SHORT() - Возвращает "короткий" универсальный идентификатор, следующий тому же алгоритму, что и для генерации авто-ID.
Для размещения в секции common {} в файле конфигурации:
- lemmatizer_base - Базовый путь к словарям лемматизатора
- progressive_merge - Определяет порядок слияния дисковых чанков в реальном времени
- json_autoconv_keynames - Следует ли и как автоматически преобразовывать имена ключей в JSON-атрибутах
- json_autoconv_numbers - Автоматически обнаруживает и преобразует возможные JSON-строки, представляющие числа, в числовые атрибуты
- on_json_attr_error - Что делать при обнаружении ошибок формата JSON
- plugin_dir - Расположение динамических библиотек и UDF
indexer - это инструмент для создания обычных таблиц
Размещаются в разделе indexer {} конфигурационного файла:
- lemmatizer_cache - Размер кэша лемматизатора
- max_file_field_buffer - Максимальный размер адаптивного буфера поля файла
- max_iops - Максимальное количество операций ввода-вывода индексации в секунду
- max_iosize - Максимально допустимый размер операции ввода-вывода
- max_xmlpipe2_field - Максимально допустимый размер поля для типа источника XMLpipe2
- mem_limit - Ограничение на использование ОЗУ при индексации
- on_file_field_error - Способ обработки ошибок ввода-вывода в полях файлов
- write_buffer - Размер буфера записи
- ignore_non_plain - Игнорировать предупреждения о нестандартных таблицах
indexer [OPTIONS] [indexname1 [indexname2 [...]]]- --all - Перестраивает все таблицы из конфигурации
- --buildstops - Анализирует источник таблицы так, как при индексации данных, создавая список индексируемых терминов
- --buildfreqs - Добавляет счётчик частоты в таблицу для --buildstops
- --config, -c - Указывает путь к конфигурационному файлу
- --dump-rows - Выгружает строки, извлечённые из SQL источника(-ов), в указанный файл
- --help - Показывает все доступные параметры
- --keep-attrs - Позволяет повторно использовать существующие атрибуты при переиндексации
- --keep-attrs-names - Задаёт, какие атрибуты использовать из существующей таблицы
- --merge-dst-range - Применяет заданный диапазон фильтрации при слиянии
- --merge-killlists - Изменяет обработку списка исключений при слиянии таблиц
- --merge - Объединяет две простые таблицы в одну
- --nohup - Предотвращает отправку индексатором сигнала SIGHUP при включении данной опции
- --noprogress - Скрывает подробности прогресса
- --print-queries - Выводит SQL-запросы, отправляемые индексатором в базу данных
- --print-rt - Показывает данные, полученные из SQL источника(-ов), в виде INSERT-запросов в таблицу реального времени
- --quiet - Подавляет весь вывод
- --rotate - Запускает вращение таблиц после сборки всех таблиц
- --sighup-each - Запускает вращение каждой таблицы сразу после её сборки
- -v - Отображает версию индексатора
index_converter — это инструмент, предназначенный для конвертации таблиц, созданных с помощью Sphinx/Manticore Search 2.x, в формат таблиц Manticore Search 3.x.
index_converter {--config /path/to/config|--path}- --config, -c - Путь к файлу конфигурации таблицы
- --index - Указывает, какую таблицу конвертировать
- --path - Устанавливает путь, содержащий таблицу(ы), вместо файла конфигурации
- --strip-path - Удаляет путь из имён файлов, на которые ссылается таблица
- --large-docid - Позволяет конвертировать документы с идентификаторами больше 2^63
- --output-dir - Записывает новые файлы в указанную папку
- --all - Конвертирует все таблицы из файла конфигурации / пути
- --killlist-target - Устанавливает целевые таблицы для применения kill-листов
searchd — это сервер Manticore.
Для размещения в секции searchd {} файла конфигурации:
- access_blob_attrs - Определяет способ доступа к файлу blob-атрибутов таблицы
- access_doclists - Определяет способ доступа к файлу doclists таблицы
- access_hitlists - Определяет способ доступа к файлу hitlists таблицы
- access_plain_attrs - Определяет способ доступа поискового сервера к простым атрибутам таблицы
- access_dict - Определяет способ доступа к файлу словаря таблицы
- agent_connect_timeout - Таймаут подключения к удаленному агенту
- agent_query_timeout - Таймаут запроса к удаленному агенту
- agent_retry_count - Определяет количество попыток подключения и запроса к удаленным агентам, которые предпринимает Manticore
- agent_retry_delay - Определяет задержку перед повторной попыткой запроса к удаленному агенту в случае сбоя
- attr_flush_period - Устанавливает период времени между сбросом обновленных атрибутов на диск
- binlog_flush - Режим сброса/синхронизации транзакций бинарного лога
- binlog_max_log_size - Максимальный размер файла бинарного лога
- binlog_common - Общий файл бинарного лога для всех таблиц
- binlog_filename_digits - Количество цифр в имени файла бинарного лога
- binlog_flush - Стратегия сброса бинарного лога
- binlog_path - Путь к файлам бинарного лога
- client_timeout - Максимальное время ожидания между запросами при использовании постоянных соединений
- collation_libc_locale - Локаль libc сервера
- collation_server - Коллация сервера по умолчанию
- data_dir - Путь к каталогу данных, где Manticore хранит все данные (RT-режим)
- diskchunk_flush_write_timeout - Таймаут автоматического сброса RAM-чанка, если в него не было записей
- diskchunk_flush_search_timeout - Таймаут предотвращения автоматического сброса RAM-чанка, если в таблице не было поисковых запросов
- docstore_cache_size - Максимальный размер блоков документов из хранилища документов, хранящихся в памяти
- expansion_limit - Максимальное количество расширенных ключевых слов для одного символа подстановки
- grouping_in_utc - Включает использование часового пояса UTC для группировки временных полей
- ha_period_karma - Размер окна статистики зеркал агентов
- ha_ping_interval - Интервал между пингами зеркал агентов
- hostname_lookup - Стратегия обновления имен хостов
- jobs_queue_size - Определяет максимальное количество "задач", разрешенных в очереди одновременно
- join_batch_size - Определяет размер пакета для объединения таблиц для баланса производительности и использования памяти
- join_cache_size - Определяет размер кэша для повторного использования результатов запросов JOIN
- kibana_version_string – Строка версии сервера, отправляемая в ответ на запросы Kibana
- listen - Определяет IP-адрес и порт или путь к Unix-доменному сокету для прослушивания searchd
- listen_backlog - Размер очереди прослушивания TCP
- listen_tfo - Включает флаг TCP_FASTOPEN для всех слушателей
- log - Путь к файлу журнала сервера Manticore
- max_batch_queries - Ограничивает количество запросов в пакете
- max_connections - Максимальное количество активных соединений
- merge_chunks_per_job - Сколько RT-дисковых чанков объединяется за одну задачу OPTIMIZE
- max_filters - Максимально допустимое количество фильтров на запрос
- max_filter_values - Максимально допустимое количество значений на фильтр
- max_open_files - Максимальное количество файлов, разрешенных для открытия сервером
- max_packet_size - Максимально допустимый размер сетевого пакета
- mysql_version_string - Строка версии сервера, возвращаемая по протоколу MySQL
- net_throttle_accept - Определяет, сколько клиентов принимается на каждой итерации сетевого цикла
- net_throttle_action - Определяет, сколько запросов обрабатывается на каждой итерации сетевого цикла
- net_wait_tm - Управляет интервалом активного цикла сетевого потока
- net_workers - Количество сетевых потоков
- network_timeout - Сетевой таймаут для запросов клиентов
- node_address - Определяет сетевой адрес узла
- persistent_connections_limit - Максимальное количество одновременных постоянных соединений с удаленными постоянными агентами
- parallel_chunk_merges - Сколько слияний RT-дисковых чанков может выполняться параллельно во время OPTIMIZE
- pid_file - Путь к pid-файлу сервера Manticore
- preopen_tables - Определяет, следует ли принудительно предварительно открывать все таблицы при запуске
- pseudo_sharding - Включает псевдошардинг для поисковых запросов к обычным и реального времени таблицам
- qcache_max_bytes - Максимальный объем оперативной памяти, выделенный для кэшированных наборов результатов
- qcache_thresh_msec - Минимальный порог реального времени для кэширования результата запроса
- qcache_ttl_sec - Срок действия кэшированного набора результатов
- query_log - Путь к файлу журнала запросов
- query_log_format - Формат журнала запросов
- query_log_min_msec - Предотвращает логирование слишком быстрых запросов
- query_log_mode - Режим прав доступа к файлу журнала запросов
- read_buffer_docs - Размер буфера чтения на ключевое слово для списков документов
- read_buffer_hits - Размер буфера чтения на ключевое слово для списков попаданий
- read_unhinted - Размер чтения без подсказок
- rt_flush_period - Как часто Manticore сбрасывает RAM-чанки таблиц реального времени на диск
- rt_merge_iops - Максимальное количество операций ввода-вывода (в секунду), разрешенное для потока слияния чанков реального времени
- rt_merge_maxiosize - Максимальный размер операции ввода-вывода, разрешенный для потока слияния чанков реального времени
- seamless_rotate - Предотвращает простои searchd при ротации таблиц с огромными объемами данных для предварительного кэширования
- secondary_indexes - Включает использование вторичных индексов для поисковых запросов
- server_id - Идентификатор сервера, используемый как начальное значение для генерации уникального идентификатора документа
- shutdown_timeout - Таймаут
--stopwaitдля searchd - shutdown_token - SHA1-хэш пароля, необходимого для вызова команды
shutdownиз VIP SQL-соединения - skiplist_cache_size - Максимальный размер кэша в памяти для распакованных списков пропуска
- snippets_file_prefix - Префикс, добавляемый к локальным именам файлов при генерации сниппетов в режиме
load_files - sphinxql_state - Путь к файлу, в который будет сериализовано текущее состояние SQL
- sphinxql_timeout - Максимальное время ожидания между запросами от клиента MySQL
- ssl_ca - Путь к файлу сертификата центра сертификации SSL
- ssl_cert - Путь к SSL-сертификату сервера
- ssl_key - Путь к ключу SSL-сертификата сервера
- subtree_docs_cache - Максимальный размер кэша документов общего поддерева
- subtree_hits_cache - Максимальный размер кэша попаданий общего поддерева, на запрос
- timezone - Часовой пояс, используемый функциями, связанными с датой/временем
- thread_stack - Максимальный размер стека для задачи
- unlink_old - Удалять ли копии таблиц .old при успешной ротации
- watchdog - Включить или отключить сторожевой таймер сервера Manticore
searchd [OPTIONS]- --config, -c - Задает путь к файлу конфигурации
- --console - Принудительно запускает сервер в консольном режиме
- --coredump - Включает сохранение дампа памяти при аварийном завершении
- --cpustats - Включает отчетность о времени процессора
- --delete - Удаляет службу Manticore из консоли управления Microsoft и других мест, где регистрируются службы
- --force-preread - Запрещает серверу обслуживать входящие соединения до предварительного чтения файлов таблиц
- --help, -h - Отображает все доступные параметры
- --quiet, -q - Выводить только ошибки при запуске
- --table (--index) - Ограничивает сервер обслуживанием только указанной таблицы
- --install - Устанавливает searchd как службу в консоли управления Microsoft
- --iostats - Включает отчетность о вводе/выводе
- --listen, -l - Переопределяет listen из файла конфигурации
- --logdebug, --logdebugv, --logdebugvv - Включает дополнительный отладочный вывод в журнал сервера
- --logreplication - Включает дополнительный отладочный вывод по репликации в журнал сервера
- --new-cluster - Инициализирует кластер репликации и устанавливает сервер в качестве опорного узла с защитой от перезапуска кластера
- --new-cluster-force - Инициализирует кластер репликации и устанавливает сервер в качестве опорного узла, обходя защиту от перезапуска кластера
- --nodetach - Удерживает searchd работающим на переднем плане
- --ntservice - Используется консолью управления Microsoft для запуска searchd как службы на платформах Windows
- --pidfile - Переопределяет pid_file в файле конфигурации
- --port, p - Задает порт, на котором должен слушать searchd, игнорируя порт, указанный в файле конфигурации
- --replay-flags - Устанавливает дополнительные параметры воспроизведения бинарного лога
- --servicename - Присваивает searchd заданное имя при установке или удалении службы, как оно отображается в консоли управления Microsoft
- --status - Запрашивает статус у запущенной службы search
- --stop - Останавливает сервер Manticore
- --stopwait - Корректно останавливает сервер Manticore
- --strip-path - Удаляет имена путей из всех имен файлов, на которые ссылается таблица
- -v - Отображает информацию о версии
- MANTICORE_TRACK_DAEMON_SHUTDOWN - Включает подробное логирование во время завершения работы searchd
Различные функции обслуживания таблиц, полезные для устранения неполадок.
indextool <command> [options]Используется для вывода различных отладочных данных, связанных с физической таблицей.
indextool <command> [options]- --config, -c - Указывает путь к файлу конфигурации
- --quiet, -q - Отключает вывод информационного баннера indextool и др.
- --help, -h - Показывает все доступные параметры
- -v - Отображает информацию о версии
- Indextool - Проверяет файл конфигурации
- --buildidf - Создает IDF-файл из одного или нескольких дампов словаря
- --build-infixes - Создает инфиксы для существующей таблицы dict=keywords
- --dumpheader - Быстро выводит предоставленный файл заголовка таблицы
- --dumpconfig - Выводит определение таблицы из указанного файла заголовка таблицы в формате почти совместимом с manticore.conf
- --dumpheader - Выводит заголовок таблицы по имени таблицы с поиском пути к заголовку в файле конфигурации
- --dumpdict - Выводит словарь таблицы
- --dumpdocids - Выводит идентификаторы документов по имени таблицы
- --dumphitlist - Выводит все вхождения указанного ключевого слова/ID в заданной таблице
- --docextract - Выполняет проверку таблицы на всем словаре/документах/вхождениях и собирает все слова и вхождения, относящиеся к запрошенному документу
- --fold - Тестирует токенизацию на основе настроек таблицы
- --htmlstrip - Фильтрует STDIN используя настройки удаления HTML для указанной таблицы
- --mergeidf - Объединяет несколько файлов .idf в один файл
- --morph - Применяет морфологию к предоставленному STDIN и выводит результат в stdout
- --check - Проверяет файлы данных таблицы на целостность
- --check-id-dups - Проверяет на дублирование идентификаторов
- --check-disk-chunk - Проверяет один диск-чанк RT-таблицы
- --strip-path - Удаляет пути из всех имен файлов, на которые ссылается таблица
- --rotate - Определяет, проверять ли таблицу в ожидании ротации при использовании
--check - --apply-killlists - Применяет kill-листы ко всем таблицам, перечисленным в файле конфигурации
Разделяет составные слова на компоненты.
wordbreaker [-dict path/to/dictionary_file] {split|test|bench}- STDIN - Принимает строку для разбивки на части
- -dict - Указывает файл словаря для использования
- split|test|bench - Указывает команду
Извлекает содержимое файла словаря в формате ispell или MySpell
spelldump [options] <dictionary> <affix> [result] [locale-name]- dictionary - Главный файл словаря
- affix - Файл аффиксов для словаря
- result - Указывает место вывода данных словаря
- locale-name - Указывает локаль для использования
Полный алфавитный список ключевых слов, в настоящее время зарезервированных в синтаксисе Manticore SQL (поэтому их нельзя использовать как идентификаторы).
AND, AS, BY, COLUMNARSCAN, DISTINCT, DIV, DOCIDINDEX, EXPLAIN, FACET, FALSE, FORCE, FROM, HYBRID_MATCH, IGNORE, IN, INDEXES, INNER, IS, JOIN, KNN, LEFT, LIMIT, MOD, NOT, NO_COLUMNARSCAN, NO_DOCIDINDEX, NO_SECONDARYINDEX, NULL, OFFSET, ON, OR, ORDER, RELOAD, SECONDARYINDEX, SELECT, SYSFILTERS, TRUE- 2.4.1
- 2.5.1
- 2.6.0
- 2.6.1
- 2.6.2
- 2.6.3
- 2.6.4
- 2.7.0
- 2.7.1
- 2.7.2
- 2.7.3
- 2.7.4
- 2.7.5
- 2.8.0
- 2.8.1
- 2.8.2
- 3.0.0
- 3.0.2
- 3.1.0
- 3.1.2
- 3.2.0
- 3.2.2
- 3.3.0
- 3.4.0
- 3.4.2
- 3.5.0
- 3.5.2
- 3.5.4
- 4.0.2
- 4.2.0
- 5.0.2. Страница установки
- 6.0.0. Страница установки
- 6.0.2. Страница установки
- 6.0.4. Страница установки
- 6.2.0. Страница установки
- 6.2.12. Страница установки
- 6.3.0. Страница установки
- 6.3.2. Страница установки
- 6.3.4. Страница установки
- 6.3.6. Страница установки
- 6.3.8. Страница установки
- 7.0.0. Страница установки
- 7.4.6. Страница установки
- 9.2.14. Страница установки
- 9.3.2. Страница установки
- 10.1.0. Страница установки
- 13.2.3. Страница установки
- 13.6.7. Страница установки
- 13.11.0. Страница установки
- 13.11.1. Страница установки
- 13.13.0. Страница установки
- 14.1.0. Страница установки
- 15.1.0. Страница установки
- 17.5.1. Страница установки
- 25.0.0. Страница установки
- CREATE TABLE - Создает новую таблицу
- CREATE TABLE LIKE - Создает таблицу, используя другую как шаблон
- CREATE TABLE LIKE ... WITH DATA - Копирует таблицу
- CREATE SOURCE - Создает источник потребителя Kafka
- CREATE MATERIALIZED VIEW - Трансформация данных из сообщений Kafka
- CREATE MV - То же, что и предыдущая
- DESCRIBE - Выводит список полей таблицы и их типы
- ALTER TABLE - Изменяет схему / настройки таблицы
- ALTER TABLE REBUILD SECONDARY - Обновляет/восстанавливает вторичные индексы
- ALTER TABLE type='distributed' - Обновляет/восстанавливает вторичные индексы
- ALTER TABLE RENAME
- ALTER MATERIALIZED VIEW {name} suspended=1 - Приостанавливает или возобновляет потребление из источника Kafka
- DROP TABLE IF EXISTS - Удаляет таблицу (если она существует)
- SHOW TABLES - Показывает список таблиц
- SHOW SOURCES - Показывает список источников Kafka
- SHOW MATERIALIZED VIEWS - Показывает список материализованных представлений
- SHOW MVS - Псевдоним предыдущей команды
- SHOW CREATE TABLE - Показывает SQL-команду для создания таблицы
- SHOW TABLE INDEXES - Показывает информацию о доступных вторичных индексах для таблицы
- SHOW TABLE STATUS - Показывает информацию о текущем состоянии таблицы
- SHOW TABLE SETTINGS - Показывает настройки таблицы
- SHOW LOCKS - Показывает информацию о замороженных таблицах
- INSERT - Добавляет новые документы
- REPLACE - Заменяет существующие документы новыми
- REPLACE .. SET - Заменяет одно или несколько полей в таблице
- UPDATE - Выполняет обновление на месте в документах
- DELETE - Удаляет документы
- TRUNCATE TABLE - Удаляет все документы из таблицы
- BACKUP - Создает резервные копии ваших таблиц
- SELECT - Поиск
- WHERE - Фильтры
- GROUP BY - Группирует результаты поиска
- GROUP BY ORDER - Сортирует группы
- GROUP BY HAVING - Фильтрует группы
- OPTION - Опции запроса
- FACET - Фасетный поиск
- SUB-SELECTS - Об использовании подзапросов SELECT
- JOIN - Объединение таблиц в SELECT
- EXPLAIN QUERY - Показывает план выполнения запроса без его запуска
- SHOW META - Показывает расширенную информацию о выполненном запросе
- SHOW PROFILE - Показывает профилирование выполненного запроса
- SHOW PLAN - Показывает план выполнения запроса после его выполнения
- SHOW WARNINGS - Показывает предупреждения последнего запроса
- FLUSH ATTRIBUTES - Принудительно сбрасывает обновленные атрибуты на диск
- FLUSH HOSTNAMES - Обновляет IP-адреса, связанные с именами хостов агентов
- FLUSH LOGS - Инициирует переоткрытие файлов логов searchd и запросов (аналогично USR1)
- FLUSH RAMCHUNK - Принудительно создает новый диск
- FLUSH TABLE - Сбрасывает RAM-чанк таблицы реального времени на диск
- OPTIMIZE TABLE - Помещает таблицу реального времени в очередь на оптимизацию
- ATTACH TABLE - Переносит данные из обычной таблицы в таблицу реального времени
- IMPORT TABLE - Импортирует ранее созданную таблицу RT или PQ в сервер, работающий в режиме RT
- JOIN CLUSTER - Присоединяется к кластеру репликации
- ALTER CLUSTER - Добавляет/удаляет таблицу в кластере репликации
- SET CLUSTER - Изменяет настройки кластера репликации
- DELETE CLUSTER - Удаляет кластер репликации
- RELOAD TABLE - Вращает простую таблицу
- RELOAD TABLES - Вращает все простые таблицы
- CALL SUGGEST, CALL QSUGGEST - Предлагает слова с исправлением орфографии
- CALL SNIPPETS - Создаёт фрагмент с подсветкой результатов из предоставленных данных и запроса
- CALL PQ - Выполняет перколяционный запрос
- CALL KEYWORDS - Используется для проверки токенизации ключевых слов. Также позволяет получить токенизированные формы предоставленных ключевых слов
- CALL AUTOCOMPLETE - Автозаполняет ваш поисковый запрос
- CREATE FUNCTION - Устанавливает пользовательскую функцию (UDF)
- DROP FUNCTION - Удаляет пользовательскую функцию (UDF)
- CREATE PLUGIN - Устанавливает плагин
- CREATE BUDDY PLUGIN - Устанавливает плагин Buddy
- DROP PLUGIN - Удаляет плагин
- DROP BUDDY PLUGIN - Удаляет плагин Buddy
- RELOAD PLUGINS - Перезагружает все плагины из заданной библиотеки
- ENABLE BUDDY PLUGIN - Реактивирует ранее отключённый плагин Buddy
- DISABLE BUDDY PLUGIN - Деактивирует активный плагин Buddy
- SHOW STATUS - Отображает ряд полезных счетчиков производительности
- SHOW THREADS - Перечисляет все текущие активные потоки клиентов
- SHOW VARIABLES - Перечисляет переменные сервера и их значения
- SHOW VERSION - Предоставляет подробную информацию о версиях различных компонентов инстанса.
- /sql - Выполняет SQL-запрос через HTTP JSON
- /cli - Обеспечивает HTTP интерфейс командной строки
- /insert - Вставляет документ в таблицу реального времени
- /pq/tbl_name/doc - Добавляет правило PQ в перколяционную таблицу
- /update - Обновляет документ в таблице реального времени
- /replace - Заменяет существующий документ в таблице реального времени или вставляет его, если он не существует
- /pq/tbl_name/doc/N?refresh=1 - Заменяет правило PQ в перколяционной таблице
- /delete - Удаляет документ из таблицы
- /bulk - Выполняет несколько операций вставки, обновления или удаления за один вызов. Подробнее о массовых вставках здесь.
- /search - Выполняет поиск
- /search -> knn - Выполняет KNN векторный поиск
- /pq/tbl_name/search - Выполняет обратный поиск в перколяционной таблице
- /tbl_name/_mapping - Создаёт схему таблицы в стиле Elasticsearch
- access_plain_attrs
- access_blob_attrs
- access_doclists
- access_hitlists
- access_dict
- attr_update_reserve
- bigram_delimiter
- bigram_freq_words
- bigram_index
- blend_chars
- blend_mode
- charset_table
- dict
- docstore_block_size
- docstore_compression
- docstore_compression_level
- embedded_limit
- exceptions
- exceptions_list
- expand_keywords
- global_idf
- hitless_words
- hitless_words_list
- html_index_attrs
- html_remove_elements
- html_strip
- ignore_chars
- index_exact_words
- index_field_lengths
- index_sp
- index_token_filter
- index_zones
- infix_fields
- inplace_enable
- inplace_hit_gap
- inplace_reloc_factor
- inplace_write_factor
- jieba_hmm
- jieba_mode
- jieba_user_dict_path
- killlist_target
- max_substring_len
- min_infix_len
- min_prefix_len
- min_stemming_len
- min_word_len
- morphology
- morphology_skip_fields
- ngram_chars
- ngram_len
- overshort_step
- path
- phrase_boundary
- phrase_boundary_step
- prefix_fields
- preopen
- read_buffer_docs
- read_buffer_hits
- regexp_filter
- stopwords
- stopwords_list
- stopword_step
- stopwords_unstemmed
- type
- wordforms
- wordforms_list
- local
- agent
- agent_connect_timeout
- agent_blackhole
- agent_persistent
- agent_query_timeout
- agent_retry_count
- ha_strategy
- mirror_retry_count
- rt_attr_bigint
- rt_attr_bool
- rt_attr_float
- rt_attr_float_vector
- rt_attr_json
- rt_attr_multi_64
- rt_attr_multi
- rt_attr_string
- rt_attr_timestamp
- rt_attr_uint
- rt_field
- rt_mem_limit
- diskchunk_flush_write_timeout
- diskchunk_flush_search_timeout
- OR
- MAYBE
- NOT - оператор NOT
- @field - оператор поиска по полю
- @field[N] - модификатор ограничения позиции поля
- @(field1,field2,...) - оператор поиска по нескольким полям
- @!field - оператор игнорирования поля при поиске
- @!(field1,field2,...) - оператор игнорирования нескольких полей при поиске
- @* - оператор поиска по всем полям
- "word1 word2 ... " - оператор поиска фразы
- "word1 word2 ... "~N - оператор поиска по близости
- "word1 word2 ... "/N - оператор кворумного соответствия
- word1 << word2 << word3 - оператор строгого порядка
- =word1 - модификатор точной формы
- ^word1 - модификатор начала поля
- word2$ - модификатор конца поля
- word^N - модификатор усиления по IDF для ключевого слова
- word1 NEAR/N word2 - оператор NEAR, обобщенный оператор близости
- word1 NOTNEAR/N word2 - оператор NOTNEAR, оператор отрицательного утверждения
- word1 PARAGRAPH word2 PARAGRAPH "word3 word4" - оператор PARAGRAPH
- word1 SENTENCE word2 SENTENCE "word3 word4" - оператор SENTENCE
- ZONE:(h3,h4) - оператор ограничения по ZONE
- ZONESPAN:(h2) - оператор ограничения по ZONESPAN
- @@relaxed - подавляет ошибки об отсутствующих полях
- t?st - операторы подстановки
- REGEX(/pattern/) - оператор REGEX
- ABS() - Возвращает абсолютное значение
- ATAN2() - Возвращает арктангенс от двух аргументов
- BITDOT() - Возвращает сумму произведений каждого бита маски на его вес
- CEIL() - Возвращает наименьшее целое значение, большее или равное аргументу
- COS() - Возвращает косинус аргумента
- CRC32() - Возвращает значение CRC32 аргумента
- EXP() - Возвращает экспоненту аргумента
- FIBONACCI() - Возвращает N-е число Фибоначчи, где N - целочисленный аргумент
- FLOOR() - Возвращает наибольшее целое значение, меньшее или равное аргументу
- GREATEST() - Принимает JSON/MVA массив в качестве аргумента и возвращает наибольшее значение в этом массиве
- IDIV() - Возвращает результат целочисленного деления первого аргумента на второй аргумент
- LEAST() - Принимает JSON/MVA массив в качестве аргумента и возвращает наименьшее значение в этом массиве
- LN() - Возвращает натуральный логарифм аргумента
- LOG10() - Возвращает десятичный логарифм аргумента
- LOG2() - Возвращает двоичный логарифм аргумента
- MAX() - Возвращает больший из двух аргументов
- MIN() - Возвращает меньший из двух аргументов
- POW() - Возвращает первый аргумент, возведенный в степень второго аргумента
- RAND() - Возвращает случайное число с плавающей точкой от 0 до 1
- SIN() - Возвращает синус аргумента
- SQRT() - Возвращает квадратный корень аргумента
- BM25F() - Возвращает точное значение формулы BM25F
- EXIST() - Заменяет несуществующие столбцы значениями по умолчанию
- GROUP_CONCAT() - Создает список значений атрибутов всех документов в группе, разделенный запятыми
- HIGHLIGHT() - Подсвечивает результаты поиска
- MIN_TOP_SORTVAL() - Возвращает значение ключа сортировки худшего найденного элемента в текущих top-N совпадениях
- MIN_TOP_WEIGHT() - Возвращает вес худшего найденного элемента в текущих top-N совпадениях
- PACKEDFACTORS() - Выводит весовые коэффициенты
- REMOVE_REPEATS() - Удаляет повторяющиеся скорректированные строки с одинаковым значением 'column'
- WEIGHT() - Возвращает оценку полнотекстового совпадения
- ZONESPANLIST() - Возвращает пары совпавших зонных интервалов
- QUERY() - Возвращает текущий полнотекстовый запрос
- BIGINT() - Принудительно преобразует целочисленный аргумент к 64-битному типу
- DOUBLE() - Принудительно преобразует заданный аргумент к типу с плавающей точкой
- INTEGER() - Принудительно преобразует заданный аргумент к 64-битному знаковому типу
- TO_STRING() - Принудительно преобразует аргумент к строковому типу
- UINT() - Преобразует заданный аргумент к 32-битному беззнаковому целочисленному типу
- UINT64() - Преобразует заданный аргумент к 64-битному беззнаковому целочисленному типу
- SINT() - Интерпретирует 32-битное беззнаковое целое как 64-битное знаковое целое
- ALL() - Возвращает 1, если условие истинно для всех элементов массива
- ANY() - Возвращает 1, если условие истинно для любого элемента массива
- CONTAINS() - Проверяет, находится ли точка (x,y) внутри заданного полигона
- IF() - Проверяет, равен ли первый аргумент 0.0, возвращает второй аргумент, если он не равен нулю, или третий, если равен
- IN() - Возвращает 1, если первый аргумент равен любому из остальных аргументов, или 0 в противном случае
- INDEXOF() - Перебирает все элементы массива и возвращает индекс первого совпадающего элемента
- INTERVAL() - Возвращает индекс аргумента, который меньше первого аргумента
- LENGTH() - Возвращает количество элементов в MVA
- REMAP() - Позволяет создавать исключения для значений выражения в зависимости от значений условия
- NOW() - Возвращает текущую метку времени как INTEGER
- CURTIME() - Возвращает текущее время в локальном часовом поясе
- CURDATE() - Возвращает текущую дату в локальном часовом поясе
- UTC_TIME() - Возвращает текущее время в часовом поясе UTC
- UTC_TIMESTAMP() - Возвращает текущую дату/время в часовом поясе UTC
- SECOND() - Возвращает целую секунду из аргумента метки времени
- MINUTE() - Возвращает целую минуту из аргумента метки времени
- HOUR() - Возвращает целый час из аргумента метки времени
- DAY() - Возвращает целый день из аргумента метки времени
- MONTH() - Возвращает целый месяц из аргумента метки времени
- QUARTER() - Возвращает целый квартал года из аргумента метки времени
- YEAR() - Возвращает целый год из аргумента метки времени
- DAYNAME() - Возвращает название дня недели для заданного аргумента метки времени
- MONTHNAME() - Возвращает название месяца для заданного аргумента метки времени
- DAYOFWEEK() - Возвращает целочисленный индекс дня недели для заданного аргумента метки времени
- DAYOFYEAR() - Возвращает целочисленный день года для заданного аргумента метки времени
- YEARWEEK() - Возвращает целый год и код дня первого дня текущей недели для заданного аргумента метки времени
- YEARMONTH() - Возвращает целый год и код месяца из аргумента метки времени
- YEARMONTHDAY() - Возвращает целый год, месяц и код дня из аргумента метки времени
- TIMEDIFF() - Возвращает разницу между метками времени
- DATEDIFF() - Возвращает количество дней между двумя заданными метками времени
- DATE() - Форматирует часть даты из аргумента метки времени
- TIME() - Форматирует часть времени из аргумента метки времени
- DATE_FORMAT() - Возвращает форматированную строку на основе предоставленных аргументов даты и формата
- GEODIST() - Вычисляет расстояние по геосфере между двумя заданными точками
- GEOPOLY2D() - Создает полигон, учитывающий кривизну Земли
- POLY2D() - Создает простой полигон в плоском пространстве
- CONCAT() - Объединяет две или более строк
- REGEX() - Возвращает 1, если регулярное выражение совпало со строкой атрибута, и 0 в противном случае
- SNIPPET() - Подсвечивает результаты поиска
- SUBSTRING_INDEX() - Возвращает подстроку строки до указанного количества вхождений разделителя
- CONNECTION_ID() - Возвращает идентификатор текущего соединения
- KNN_DIST() - Возвращает расстояние поиска по векторам KNN
- LAST_INSERT_ID() - Возвращает идентификаторы документов, вставленных или замененных последним оператором в текущей сессии
- UUID_SHORT() - Возвращает "короткий" универсальный идентификатор, следующий тому же алгоритму, что и для генерации авто-ID.
Для размещения в секции common {} в файле конфигурации:
- lemmatizer_base - Базовый путь к словарям лемматизатора
- progressive_merge - Определяет порядок слияния дисковых чанков в реальном времени
- json_autoconv_keynames - Следует ли и как автоматически преобразовывать имена ключей в JSON-атрибутах
- json_autoconv_numbers - Автоматически обнаруживает и преобразует возможные JSON-строки, представляющие числа, в числовые атрибуты
- on_json_attr_error - Что делать при обнаружении ошибок формата JSON
- plugin_dir - Расположение динамических библиотек и UDF
indexer - это инструмент для создания обычных таблиц
Размещаются в разделе indexer {} конфигурационного файла:
- lemmatizer_cache - Размер кэша лемматизатора
- max_file_field_buffer - Максимальный размер адаптивного буфера поля файла
- max_iops - Максимальное количество операций ввода-вывода индексации в секунду
- max_iosize - Максимально допустимый размер операции ввода-вывода
- max_xmlpipe2_field - Максимально допустимый размер поля для типа источника XMLpipe2
- mem_limit - Ограничение на использование ОЗУ при индексации
- on_file_field_error - Способ обработки ошибок ввода-вывода в полях файлов
- write_buffer - Размер буфера записи
- ignore_non_plain - Игнорировать предупреждения о нестандартных таблицах
indexer [OPTIONS] [indexname1 [indexname2 [...]]]- --all - Перестраивает все таблицы из конфигурации
- --buildstops - Анализирует источник таблицы так, как при индексации данных, создавая список индексируемых терминов
- --buildfreqs - Добавляет счётчик частоты в таблицу для --buildstops
- --config, -c - Указывает путь к конфигурационному файлу
- --dump-rows - Выгружает строки, извлечённые из SQL источника(-ов), в указанный файл
- --help - Показывает все доступные параметры
- --keep-attrs - Позволяет повторно использовать существующие атрибуты при переиндексации
- --keep-attrs-names - Задаёт, какие атрибуты использовать из существующей таблицы
- --merge-dst-range - Применяет заданный диапазон фильтрации при слиянии
- --merge-killlists - Изменяет обработку списка исключений при слиянии таблиц
- --merge - Объединяет две простые таблицы в одну
- --nohup - Предотвращает отправку индексатором сигнала SIGHUP при включении данной опции
- --noprogress - Скрывает подробности прогресса
- --print-queries - Выводит SQL-запросы, отправляемые индексатором в базу данных
- --print-rt - Показывает данные, полученные из SQL источника(-ов), в виде INSERT-запросов в таблицу реального времени
- --quiet - Подавляет весь вывод
- --rotate - Запускает вращение таблиц после сборки всех таблиц
- --sighup-each - Запускает вращение каждой таблицы сразу после её сборки
- -v - Отображает версию индексатора
index_converter — это инструмент, предназначенный для конвертации таблиц, созданных с помощью Sphinx/Manticore Search 2.x, в формат таблиц Manticore Search 3.x.
index_converter {--config /path/to/config|--path}- --config, -c - Путь к файлу конфигурации таблицы
- --index - Указывает, какую таблицу конвертировать
- --path - Устанавливает путь, содержащий таблицу(ы), вместо файла конфигурации
- --strip-path - Удаляет путь из имён файлов, на которые ссылается таблица
- --large-docid - Позволяет конвертировать документы с идентификаторами больше 2^63
- --output-dir - Записывает новые файлы в указанную папку
- --all - Конвертирует все таблицы из файла конфигурации / пути
- --killlist-target - Устанавливает целевые таблицы для применения kill-листов
searchd — это сервер Manticore.
Для размещения в секции searchd {} файла конфигурации:
- access_blob_attrs - Определяет способ доступа к файлу blob-атрибутов таблицы
- access_doclists - Определяет способ доступа к файлу doclists таблицы
- access_hitlists - Определяет способ доступа к файлу hitlists таблицы
- access_plain_attrs - Определяет способ доступа поискового сервера к простым атрибутам таблицы
- access_dict - Определяет способ доступа к файлу словаря таблицы
- agent_connect_timeout - Таймаут подключения к удаленному агенту
- agent_query_timeout - Таймаут запроса к удаленному агенту
- agent_retry_count - Определяет количество попыток подключения и запроса к удаленным агентам, которые предпринимает Manticore
- agent_retry_delay - Определяет задержку перед повторной попыткой запроса к удаленному агенту в случае сбоя
- attr_flush_period - Устанавливает период времени между сбросом обновленных атрибутов на диск
- binlog_flush - Режим сброса/синхронизации транзакций бинарного лога
- binlog_max_log_size - Максимальный размер файла бинарного лога
- binlog_common - Общий файл бинарного лога для всех таблиц
- binlog_filename_digits - Количество цифр в имени файла бинарного лога
- binlog_flush - Стратегия сброса бинарного лога
- binlog_path - Путь к файлам бинарного лога
- client_timeout - Максимальное время ожидания между запросами при использовании постоянных соединений
- collation_libc_locale - Локаль libc сервера
- collation_server - Коллация сервера по умолчанию
- data_dir - Путь к каталогу данных, где Manticore хранит все данные (RT-режим)
- diskchunk_flush_write_timeout - Таймаут автоматического сброса RAM-чанка, если в него не было записей
- diskchunk_flush_search_timeout - Таймаут предотвращения автоматического сброса RAM-чанка, если в таблице не было поисковых запросов
- docstore_cache_size - Максимальный размер блоков документов из хранилища документов, хранящихся в памяти
- expansion_limit - Максимальное количество расширенных ключевых слов для одного символа подстановки
- grouping_in_utc - Включает использование часового пояса UTC для группировки временных полей
- ha_period_karma - Размер окна статистики зеркал агентов
- ha_ping_interval - Интервал между пингами зеркал агентов
- hostname_lookup - Стратегия обновления имен хостов
- jobs_queue_size - Определяет максимальное количество "задач", разрешенных в очереди одновременно
- join_batch_size - Определяет размер пакета для объединения таблиц для баланса производительности и использования памяти
- join_cache_size - Определяет размер кэша для повторного использования результатов запросов JOIN
- kibana_version_string – Строка версии сервера, отправляемая в ответ на запросы Kibana
- listen - Определяет IP-адрес и порт или путь к Unix-доменному сокету для прослушивания searchd
- listen_backlog - Размер очереди прослушивания TCP
- listen_tfo - Включает флаг TCP_FASTOPEN для всех слушателей
- log - Путь к файлу журнала сервера Manticore
- max_batch_queries - Ограничивает количество запросов в пакете
- max_connections - Максимальное количество активных соединений
- merge_chunks_per_job - Сколько RT-дисковых чанков объединяется за одну задачу OPTIMIZE
- max_filters - Максимально допустимое количество фильтров на запрос
- max_filter_values - Максимально допустимое количество значений на фильтр
- max_open_files - Максимальное количество файлов, разрешенных для открытия сервером
- max_packet_size - Максимально допустимый размер сетевого пакета
- mysql_version_string - Строка версии сервера, возвращаемая по протоколу MySQL
- net_throttle_accept - Определяет, сколько клиентов принимается на каждой итерации сетевого цикла
- net_throttle_action - Определяет, сколько запросов обрабатывается на каждой итерации сетевого цикла
- net_wait_tm - Управляет интервалом активного цикла сетевого потока
- net_workers - Количество сетевых потоков
- network_timeout - Сетевой таймаут для запросов клиентов
- node_address - Определяет сетевой адрес узла
- persistent_connections_limit - Максимальное количество одновременных постоянных соединений с удаленными постоянными агентами
- parallel_chunk_merges - Сколько слияний RT-дисковых чанков может выполняться параллельно во время OPTIMIZE
- pid_file - Путь к pid-файлу сервера Manticore
- preopen_tables - Определяет, следует ли принудительно предварительно открывать все таблицы при запуске
- pseudo_sharding - Включает псевдошардинг для поисковых запросов к обычным и реального времени таблицам
- qcache_max_bytes - Максимальный объем оперативной памяти, выделенный для кэшированных наборов результатов
- qcache_thresh_msec - Минимальный порог реального времени для кэширования результата запроса
- qcache_ttl_sec - Срок действия кэшированного набора результатов
- query_log - Путь к файлу журнала запросов
- query_log_format - Формат журнала запросов
- query_log_min_msec - Предотвращает логирование слишком быстрых запросов
- query_log_mode - Режим прав доступа к файлу журнала запросов
- read_buffer_docs - Размер буфера чтения на ключевое слово для списков документов
- read_buffer_hits - Размер буфера чтения на ключевое слово для списков попаданий
- read_unhinted - Размер чтения без подсказок
- rt_flush_period - Как часто Manticore сбрасывает RAM-чанки таблиц реального времени на диск
- rt_merge_iops - Максимальное количество операций ввода-вывода (в секунду), разрешенное для потока слияния чанков реального времени
- rt_merge_maxiosize - Максимальный размер операции ввода-вывода, разрешенный для потока слияния чанков реального времени
- seamless_rotate - Предотвращает простои searchd при ротации таблиц с огромными объемами данных для предварительного кэширования
- secondary_indexes - Включает использование вторичных индексов для поисковых запросов
- server_id - Идентификатор сервера, используемый как начальное значение для генерации уникального идентификатора документа
- shutdown_timeout - Таймаут
--stopwaitдля searchd - shutdown_token - SHA1-хэш пароля, необходимого для вызова команды
shutdownиз VIP SQL-соединения - skiplist_cache_size - Максимальный размер кэша в памяти для распакованных списков пропуска
- snippets_file_prefix - Префикс, добавляемый к локальным именам файлов при генерации сниппетов в режиме
load_files - sphinxql_state - Путь к файлу, в который будет сериализовано текущее состояние SQL
- sphinxql_timeout - Максимальное время ожидания между запросами от клиента MySQL
- ssl_ca - Путь к файлу сертификата центра сертификации SSL
- ssl_cert - Путь к SSL-сертификату сервера
- ssl_key - Путь к ключу SSL-сертификата сервера
- subtree_docs_cache - Максимальный размер кэша документов общего поддерева
- subtree_hits_cache - Максимальный размер кэша попаданий общего поддерева, на запрос
- timezone - Часовой пояс, используемый функциями, связанными с датой/временем
- thread_stack - Максимальный размер стека для задачи
- unlink_old - Удалять ли копии таблиц .old при успешной ротации
- watchdog - Включить или отключить сторожевой таймер сервера Manticore
searchd [OPTIONS]- --config, -c - Задает путь к файлу конфигурации
- --console - Принудительно запускает сервер в консольном режиме
- --coredump - Включает сохранение дампа памяти при аварийном завершении
- --cpustats - Включает отчетность о времени процессора
- --delete - Удаляет службу Manticore из консоли управления Microsoft и других мест, где регистрируются службы
- --force-preread - Запрещает серверу обслуживать входящие соединения до предварительного чтения файлов таблиц
- --help, -h - Отображает все доступные параметры
- --quiet, -q - Выводить только ошибки при запуске
- --table (--index) - Ограничивает сервер обслуживанием только указанной таблицы
- --install - Устанавливает searchd как службу в консоли управления Microsoft
- --iostats - Включает отчетность о вводе/выводе
- --listen, -l - Переопределяет listen из файла конфигурации
- --logdebug, --logdebugv, --logdebugvv - Включает дополнительный отладочный вывод в журнал сервера
- --logreplication - Включает дополнительный отладочный вывод по репликации в журнал сервера
- --new-cluster - Инициализирует кластер репликации и устанавливает сервер в качестве опорного узла с защитой от перезапуска кластера
- --new-cluster-force - Инициализирует кластер репликации и устанавливает сервер в качестве опорного узла, обходя защиту от перезапуска кластера
- --nodetach - Удерживает searchd работающим на переднем плане
- --ntservice - Используется консолью управления Microsoft для запуска searchd как службы на платформах Windows
- --pidfile - Переопределяет pid_file в файле конфигурации
- --port, p - Задает порт, на котором должен слушать searchd, игнорируя порт, указанный в файле конфигурации
- --replay-flags - Устанавливает дополнительные параметры воспроизведения бинарного лога
- --servicename - Присваивает searchd заданное имя при установке или удалении службы, как оно отображается в консоли управления Microsoft
- --status - Запрашивает статус у запущенной службы search
- --stop - Останавливает сервер Manticore
- --stopwait - Корректно останавливает сервер Manticore
- --strip-path - Удаляет имена путей из всех имен файлов, на которые ссылается таблица
- -v - Отображает информацию о версии
- MANTICORE_TRACK_DAEMON_SHUTDOWN - Включает подробное логирование во время завершения работы searchd
Различные функции обслуживания таблиц, полезные для устранения неполадок.
indextool <command> [options]Используется для вывода различных отладочных данных, связанных с физической таблицей.
indextool <command> [options]- --config, -c - Указывает путь к файлу конфигурации
- --quiet, -q - Отключает вывод информационного баннера indextool и др.
- --help, -h - Показывает все доступные параметры
- -v - Отображает информацию о версии
- Indextool - Проверяет файл конфигурации
- --buildidf - Создает IDF-файл из одного или нескольких дампов словаря
- --build-infixes - Создает инфиксы для существующей таблицы dict=keywords
- --dumpheader - Быстро выводит предоставленный файл заголовка таблицы
- --dumpconfig - Выводит определение таблицы из указанного файла заголовка таблицы в формате почти совместимом с manticore.conf
- --dumpheader - Выводит заголовок таблицы по имени таблицы с поиском пути к заголовку в файле конфигурации
- --dumpdict - Выводит словарь таблицы
- --dumpdocids - Выводит идентификаторы документов по имени таблицы
- --dumphitlist - Выводит все вхождения указанного ключевого слова/ID в заданной таблице
- --docextract - Выполняет проверку таблицы на всем словаре/документах/вхождениях и собирает все слова и вхождения, относящиеся к запрошенному документу
- --fold - Тестирует токенизацию на основе настроек таблицы
- --htmlstrip - Фильтрует STDIN используя настройки удаления HTML для указанной таблицы
- --mergeidf - Объединяет несколько файлов .idf в один файл
- --morph - Применяет морфологию к предоставленному STDIN и выводит результат в stdout
- --check - Проверяет файлы данных таблицы на целостность
- --check-id-dups - Проверяет на дублирование идентификаторов
- --check-disk-chunk - Проверяет один диск-чанк RT-таблицы
- --strip-path - Удаляет пути из всех имен файлов, на которые ссылается таблица
- --rotate - Определяет, проверять ли таблицу в ожидании ротации при использовании
--check - --apply-killlists - Применяет kill-листы ко всем таблицам, перечисленным в файле конфигурации
Разделяет составные слова на компоненты.
wordbreaker [-dict path/to/dictionary_file] {split|test|bench}- STDIN - Принимает строку для разбивки на части
- -dict - Указывает файл словаря для использования
- split|test|bench - Указывает команду
Извлекает содержимое файла словаря в формате ispell или MySpell
spelldump [options] <dictionary> <affix> [result] [locale-name]- dictionary - Главный файл словаря
- affix - Файл аффиксов для словаря
- result - Указывает место вывода данных словаря
- locale-name - Указывает локаль для использования
Полный алфавитный список ключевых слов, в настоящее время зарезервированных в синтаксисе Manticore SQL (поэтому их нельзя использовать как идентификаторы).
AND, AS, BY, COLUMNARSCAN, DISTINCT, DIV, DOCIDINDEX, EXPLAIN, FACET, FALSE, FORCE, FROM, HYBRID_MATCH, IGNORE, IN, INDEXES, INNER, IS, JOIN, KNN, LEFT, LIMIT, MOD, NOT, NO_COLUMNARSCAN, NO_DOCIDINDEX, NO_SECONDARYINDEX, NULL, OFFSET, ON, OR, ORDER, RELOAD, SECONDARYINDEX, SELECT, SYSFILTERS, TRUE- 2.4.1
- 2.5.1
- 2.6.0
- 2.6.1
- 2.6.2
- 2.6.3
- 2.6.4
- 2.7.0
- 2.7.1
- 2.7.2
- 2.7.3
- 2.7.4
- 2.7.5
- 2.8.0
- 2.8.1
- 2.8.2
- 3.0.0
- 3.0.2
- 3.1.0
- 3.1.2
- 3.2.0
- 3.2.2
- 3.3.0
- 3.4.0
- 3.4.2
- 3.5.0
- 3.5.2
- 3.5.4
- 4.0.2
- 4.2.0
- 5.0.2. Страница установки
- 6.0.0. Страница установки
- 6.0.2. Страница установки
- 6.0.4. Страница установки
- 6.2.0. Страница установки
- 6.2.12. Страница установки
- 6.3.0. Страница установки
- 6.3.2. Страница установки
- 6.3.4. Страница установки
- 6.3.6. Страница установки
- 6.3.8. Страница установки
- 7.0.0. Страница установки
- 7.4.6. Страница установки
- 9.2.14. Страница установки
- 9.3.2. Страница установки
- 10.1.0. Страница установки
- 13.2.3. Страница установки
- 13.6.7. Страница установки
- 13.11.0. Страница установки
- 13.11.1. Страница установки
- 13.13.0. Страница установки
- 14.1.0. Страница установки
- 15.1.0. Страница установки
- 17.5.1. Страница установки
- 25.0.0. Страница установки