Клауза MATCH позволяет выполнять полнотекстовый поиск по текстовым полям. Входная строка запроса токенизируется с использованием тех же настроек, которые применялись к тексту при индексировании. Помимо токенизации входного текста, строка запроса поддерживает ряд операторов полнотекстового поиска, которые накладывают различные правила на то, как ключевые слова должны обеспечивать валидное совпадение.
Клаузы полнотекстового поиска могут быть объединены с атрибутными фильтрами посредством логического И. Отношения ИЛИ между полнотекстовым поиском и атрибутными фильтрами не поддерживаются.
Запрос на полнотекстовый поиск всегда выполняется первым в процессе фильтрации, за ним следуют атрибутные фильтры. Атрибутные фильтры применяются к результирующему набору запроса полнотекстового поиска. Запрос без клаузы MATCH называется полным сканированием (fullscan).
В клаузе SELECT может быть не более одного MATCH().
Используя синтаксис полнотекстового запроса, поиск выполняется по всем индексированным текстовым полям документа, если выражение не требует совпадения внутри конкретного поля (как при поиске по фразе) или не ограничено операторами полей.
При использовании запросов с JOIN, MATCH() может принимать необязательный второй параметр, который указывает, к какой таблице следует применить полнотекстовый поиск. По умолчанию полнотекстовый запрос применяется к левой таблице в операции JOIN:
SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.id WHERE MATCH('search query', table2);Это позволяет выполнять полнотекстовый поиск по конкретным таблицам в операции соединения. Для получения более подробной информации об использовании MATCH с JOIN, см. раздел Соединение таблиц.
MATCH('search query' [, table_name])'search query': Строка запроса полнотекстового поиска, которая может включать различные операторы полнотекстового поиска.table_name: (Необязательно) Имя таблицы, к которой следует применить полнотекстовый поиск, используется в запросахJOINдля указания таблицы, отличной от таблицы по умолчанию (левой).
Оператор SELECT использует клаузу MATCH, которая должна следовать после WHERE, для выполнения полнотекстового поиска. MATCH() принимает входную строку, в которой доступны все операторы полнотекстового поиска.
- SQL
- MATCH with filters
SELECT * FROM myindex WHERE MATCH('"find me fast"/2');Пример более сложного запроса с использованием MATCH вместе с фильтрами WHERE.
SELECT * FROM myindex WHERE MATCH('cats|birds') AND (`title`='some title' AND `id`=123);+------+------+----------------+
| id | gid | title |
+------+------+----------------+
| 1 | 11 | first find me |
| 2 | 12 | second find me |
+------+------+----------------+
2 rows in set (0.00 sec)Полнотекстовый поиск доступен в эндпоинте /search и в HTTP-клиентах. Для выполнения полнотекстового поиска могут использоваться следующие клаузы:
"match" — это простой запрос, который ищет указанные ключевые слова в указанных полях.
"query":
{
"match": { "field": "keyword" }
}Вы можете указать список полей:
"match":
{
"field1,field2": "keyword"
}Или вы можете использовать _all или * для поиска по всем полям.
Вы можете искать по всем полям, кроме одного, используя "!field":
"match":
{
"!field1": "keyword"
}По умолчанию ключевые слова объединяются с помощью оператора ИЛИ. Однако это поведение можно изменить с помощью клаузы "operator":
"query":
{
"match":
{
"content,title":
{
"query":"keyword",
"operator":"or"
}
}
}"operator" может быть установлен в "or" или "and".
Также может быть применен модификатор boost. Он увеличивает IDF_score слова на указанный коэффициент в ранжирующих оценках, которые включают IDF в свои расчеты. Это никак не влияет на процесс поиска совпадений.
"query":
{
"match":
{
"field1":
{
"query": "keyword",
"boost": 2.0
}
}
}"match_phrase" — это запрос, который ищет точное совпадение всей фразы. Он аналогичен оператору фразы в SQL. Вот пример:
"query":
{
"match_phrase": { "_all" : "had grown quite" }
}"query_string" принимает входную строку как полнотекстовый запрос в синтаксисе MATCH().
"query":
{
"query_string": "Church NOTNEAR/3 street"
}"match_all" принимает пустой объект и возвращает документы из таблицы без выполнения какого-либо атрибутного фильтрования или полнотекстового поиска. Альтернативно, вы можете просто опустить клаузу query в запросе, что даст тот же эффект.
"query":
{
"match_all": {}
}Все клаузы полнотекстового поиска могут быть объединены с операторами must, must_not и should JSON bool запроса.
- match
- match_phrase
- query_string
- PHP
- Python
- Python-asyncio
- javascript
- Java
- C#
- Rust
- TypeScript
- Go
POST /search
-d
'{
"table" : "hn_small",
"query":
{
"match":
{
"*" : "find joe"
}
},
"_source": ["story_author","comment_author"],
"limit": 1
}'POST /search
-d
'{
"table" : "hn_small",
"query":
{
"match_phrase":
{
"*" : "find joe"
}
},
"_source": ["story_author","comment_author"],
"limit": 1
}'POST /search
-d
'{ "table" : "hn_small",
"query":
{
"query_string": "@comment_text \"find joe fast \"/2"
},
"_source": ["story_author","comment_author"],
"limit": 1
}'$search = new Search(new Client());
$result = $search->('@title find me fast');
foreach($result as $doc)
{
echo 'Document: '.$doc->getId();
foreach($doc->getData() as $field=>$value)
{
echo $field.': '.$value;
}
}searchApi.search({"table":"hn_small","query":{"query_string":"@comment_text \"find joe fast \"/2"}, "_source": ["story_author","comment_author"], "limit":1})await searchApi.search({"table":"hn_small","query":{"query_string":"@comment_text \"find joe fast \"/2"}, "_source": ["story_author","comment_author"], "limit":1})res = await searchApi.search({"table":"hn_small","query":{"query_string":"@comment_text \"find joe fast \"/2"}, "_source": ["story_author","comment_author"], "limit":1});query = new HashMap<String,Object>();
query.put("query_string", "@comment_text \"find joe fast \"/2");
searchRequest = new SearchRequest();
searchRequest.setIndex("hn_small");
searchRequest.setQuery(query);
searchRequest.addSourceItem("story_author");
searchRequest.addSourceItem("comment_author");
searchRequest.limit(1);
searchResponse = searchApi.search(searchRequest);object query = new { query_string="@comment_text \"find joe fast \"/2" };
var searchRequest = new SearchRequest("hn_small", query);
searchRequest.Source = new List<string> {"story_author", "comment_author"};
searchRequest.Limit = 1;
SearchResponse searchResponse = searchApi.Search(searchRequest);let query = SearchQuery {
query_string: Some(serde_json::json!("@comment_text \"find joe fast \"/2").into()),
..Default::default()
};
let search_req = SearchRequest {
table: "hn_small".to_string(),
query: Some(Box::new(query)),
source: serde_json::json!(["story_author", "comment_author"]),
limit: serde_json::json!(1),
..Default::default(),
};
let search_res = search_api.search(search_req).await;res = await searchApi.search({
index: 'test',
query: { query_string: "test document 1" },
"_source": ["content", "title"],
limit: 1
});searchRequest := manticoresearch.NewSearchRequest("test")
query := map[string]interface{} {"query_string": "test document 1"}
searchReq.SetSource([]string{"content", "title"})
searchReq.SetLimit(1)
resp, httpRes, err := search.SearchRequest(*searchRequest).Execute(){
"took" : 3,
"timed_out" : false,
"hits" : {
"hits" : [
{
"_id": 668018,
"_score" : 3579,
"_source" : {
"story_author" : "IgorPartola",
"comment_author" : "joe_the_user"
}
}
],
"total" : 88063,
"total_relation" : "eq"
}
}{
"took" : 3,
"timed_out" : false,
"hits" : {
"hits" : [
{
"_id": 807160,
"_score" : 2599,
"_source" : {
"story_author" : "rbanffy",
"comment_author" : "runjake"
}
}
],
"total" : 2,
"total_relation" : "eq"
}
}{
"took" : 3,
"timed_out" : false,
"hits" : {
"hits" : [
{
"_id": 807160,
"_score" : 2566,
"_source" : {
"story_author" : "rbanffy",
"comment_author" : "runjake"
}
}
],
"total" : 1864,
"total_relation" : "eq"
}
}Document: 1
title: first find me fast
gid: 11
Document: 2
title: second find me fast
gid: 12{'aggregations': None,
'hits': {'hits': [{'_id': '807160',
'_score': 2566,
'_source': {'comment_author': 'runjake',
'story_author': 'rbanffy'}}],
'max_score': None,
'total': 1864,
'total_relation': 'eq'},
'profile': None,
'timed_out': False,
'took': 2,
'warning': None}{'aggregations': None,
'hits': {'hits': [{'_id': '807160',
'_score': 2566,
'_source': {'comment_author': 'runjake',
'story_author': 'rbanffy'}}],
'max_score': None,
'total': 1864,
'total_relation': 'eq'},
'profile': None,
'timed_out': False,
'took': 2,
'warning': None}{
took: 1,
timed_out: false,
hits:
exports {
total: 1864,
total_relation: 'eq',
hits:
[ { _id: '807160',
_score: 2566,
_source: { story_author: 'rbanffy', comment_author: 'runjake' }
}
]
}
}class SearchResponse {
took: 1
timedOut: false
aggregations: null
hits: class SearchResponseHits {
maxScore: null
total: 1864
totalRelation: eq
hits: [{_id=807160, _score=2566, _source={story_author=rbanffy, comment_author=runjake}}]
}
profile: null
warning: null
}class SearchResponse {
took: 1
timedOut: false
aggregations: null
hits: class SearchResponseHits {
maxScore: null
total: 1864
totalRelation: eq
hits: [{_id=807160, _score=2566, _source={story_author=rbanffy, comment_author=runjake}}]
}
profile: null
warning: null
}class SearchResponse {
took: 1
timedOut: false
aggregations: null
hits: class SearchResponseHits {
maxScore: null
total: 1864
totalRelation: eq
hits: [{_id=807160, _score=2566, _source={story_author=rbanffy, comment_author=runjake}}]
}
profile: null
warning: null
}{
took: 1,
timed_out: false,
hits:
exports {
total: 5,
total_relation: 'eq',
hits:
[ { _id: '1',
_score: 2566,
_source: { content: 'This is a test document 1', title: 'Doc 1' }
}
]
}
}{
"hits": {
"hits": [
{
"_id": 1,
"_score": 2566,
"_source": {
"content": "This is a test document 1",
"title": "Doc 1"
}
}
],
"total": 5,
"total_relation": "eq"
},
"timed_out": false,
"took": 0
}Строка запроса может включать конкретные операторы, которые определяют условия того, как должны сопоставляться слова из строки запроса.
Неявный логический оператор AND всегда присутствует, поэтому "hello world" подразумевает, что оба слова "hello" и "world" должны быть найдены в сопоставляемом документе.
hello worldПримечание: явного оператора AND нет.
Логический оператор OR | имеет более высокий приоритет, чем AND, поэтому looking for cat | dog | mouse означает looking for (cat | dog | mouse), а не (looking for cat) | dog | mouse.
hello | worldПримечание: оператора OR не существует. Пожалуйста, используйте | вместо него.
hello MAYBE worldОператор MAYBE работает аналогично оператору |, но не возвращает документы, которые совпадают только с правым выражением дерева.
hello -world
hello !worldОператор отрицания задаёт правило, что слово не должно присутствовать.
Запросы, содержащие только отрицания, по умолчанию не поддерживаются. Чтобы включить поддержку, используйте опцию сервера not_terms_only_allowed.
@title hello @body worldОператор ограничения поля ограничивает последующие поиски указанным полем. По умолчанию запрос вызовет ошибку, если заданное имя поля отсутствует в искомой таблице. Тем не менее, это поведение можно подавить, указав опцию @@relaxed в начале запроса:
@@relaxed @nosuchfield my queryЭто может быть полезно при поиске по гетерогенным таблицам с разными схемами.
Ограничения позиции поля дополнительно ограничивают поиск первыми N позициями в данном поле (или полях). Например, @body [50] hello не совпадает с документами, где ключевое слово hello появляется на позиции 51 или далее в теле текста.
@body[50] helloОператор поиска по нескольким полям:
@(title,body) hello worldОператор игнорирования поля поиска (игнорирует любые совпадения 'hello world' из поля 'title'):
@!title hello worldОператор игнорирования поиска по нескольким полям (если существуют поля 'title', 'subject' и 'body', то @!(title) эквивалентен @(subject,body)):
@!(title,body) hello worldОператор поиска по всем полям:
@* hello"hello world"Оператор фразы требует, чтобы слова шли подряд друг за другом.
Оператор поиска по фразе может включать модификатор match any term. Внутри оператора фразы термины имеют позиционное значение. При использовании модификатора 'match any term' позиции последующих терминов в запросе с фразой будут смещены. В результате модификатор 'match any' не влияет на производительность поиска.
Примечание: при использовании этого оператора с запросами, содержащими более 31 ключевого слова, статистика ранжирования (такая как tf, idf, bm25) для слов в позициях 31 и выше может учитываться с понижением точности. Это связано с внутренним использованием 32-битной маски для отслеживания вхождений терминов в совпадении. Логика сопоставления (нахождение документов) остаётся корректной, но рейтинг может быть искажен для очень длинных запросов.
"exact * phrase * * for terms"Вы также можете использовать оператор OR внутри кавычек. Оператор OR (|) должен быть заключён в скобки () при использовании внутри фраз. Каждый вариант проверяется на одной позиции, и фраза совпадает, если любой из вариантов подходит для этой позиции.
Верные примеры (со скобками):
"( a | b ) c"
"( ( a b c ) | d ) e"
"man ( happy | sad ) but all ( ( as good ) | ( as fast ) )"Неверные примеры (без скобок — такие не работают):
"a | b c"
"happy | sad""hello world"~10Расстояние близости измеряется в словах, учитывая количество слов, и применяется ко всем словам внутри кавычек. Например, запрос "cat dog mouse"~5 означает, что должен быть отрезок меньше 8 слов, содержащий все 3 слова. Поэтому документ с текстом CAT aaa bbb ccc DOG eee fff MOUSE не соответствует запросу, так как отрезок равен ровно 8 словам.
Примечание: при использовании этого оператора с запросами, содержащими более 31 ключевого слова, статистика ранжирования (такая как tf, idf, bm25) для слов в позициях 31 и выше может учитываться с понижением точности. Это связано с внутренним использованием 32-битной маски для отслеживания вхождений терминов в совпадении. Логика сопоставления (нахождение документов) остаётся корректной, но рейтинг может быть искажен для очень длинных запросов.
Вы также можете использовать оператор OR внутри поиска по близости. Оператор OR (|) должен быть заключён в скобки () при использовании внутри поисков по близости. Каждый вариант проверяется отдельно.
Верный пример (со скобками):
"( two | four ) fish chips"~5Неверный пример (без скобок — не работает):
"two | four fish chips"~5"the world is a wonderful place"/3Оператор кворумного совпадения вводит тип нечеткого поиска. Он совпадает только с теми документами, которые соответствуют заданному порогу по количеству указанных слов. В примере выше ("the world is a wonderful place"/3) совпадут все документы, содержащие не менее 3 из 6 указанных слов. Оператор ограничен 255 ключевыми словами. Вместо абсолютного числа можно указать значение от 0.0 до 1.0 (представляющее 0% и 100%), и Manticore будет совпадать только с документами, содержащими не менее указанного процента слов. Тот же пример выше можно записать как "the world is a wonderful place"/0.5, и он будет совпадать с документами, содержащими не менее 50% из 6 слов.
Оператор кворума поддерживает оператор OR (|). Оператор OR (|) должен быть заключён в скобки () при использовании внутри кворумного совпадения. Для совпадения учитывается только одно слово из каждой группы OR.
Верные примеры (со скобками):
"( ( a b c ) | d ) e f g"/0.5
"happy ( sad | angry ) man"/2Неверный пример (без скобок — не работает):
"a b c | d e f g"/0.5aaa << bbb << cccОператор строгого порядка (также известный как оператор "before") совпадает с документом только если ключевые слова аргумента появляются в документе именно в том порядке, который указан в запросе. Например, запрос black << cat совпадёт с документом "black and white cat", но не с документом "that cat was black". Оператор порядка имеет самый низкий приоритет. Его можно применять как к отдельным ключевым словам, так и к более сложным выражениям. Например, это корректный запрос:
(bag of words) << "exact phrase" << red|green|blueraining =cats and =dogs
="exact phrase"Модификатор ключевого слова точной формы совпадает с документом только если ключевое слово встречается в точно указанной форме. По умолчанию документ считается совпадающим, если совпадает основа/лемма ключевого слова. Например, запрос "runs" совпадает с документом, содержащим "runs", и с документом, содержащим "running", поскольку обе формы сводятся к основе "run". Однако запрос =runs совпадает только с первым документом. Модификатор точной формы требует включения опции index_exact_words.
Другой сценарий использования — предотвращение расширения ключевого слова до формы *keyword*. Например, при index_exact_words=1 + expand_keywords=1/star, запрос bcd найдет документ, содержащий abcde, а =bcd — нет.
Как модификатор, влияющий на ключевое слово, его можно использовать внутри операторов, таких как оператор фразы, близости и кворума. Применение модификатора точной формы к оператору фразы возможно, и в этом случае он внутренне добавляет модификатор точной формы ко всем терминам в фразе.
nation* *nation* *nationalТребует установки min_infix_len для префикса (расширение в конце) и/или суффикса (расширение в начале). Если требуется только префиксное расширение, можно использовать min_prefix_len.
Поиск пытается найти все расширения токенов с подстановочными символами, и каждое расширение фиксируется как совпадающее попадание. Количество расширений токена можно контролировать с помощью настройки таблицы expansion_limit. Токены с подстановочными символами могут существенно влиять на время поиска запросов, особенно если токены короткие. В таких случаях рекомендуется использовать ограничение расширения.
Оператор подстановки может автоматически применяться, если используется настройка таблицы expand_keywords.
Кроме того, поддерживаются следующие встроенные операторы подстановки:
?может соответствовать любому одному символу:t?stсовпадает сtest, но не сteast%может соответствовать нулю или одному символу:tes%совпадает сtesилиtest, но не сtesting
Встроенные операторы требуют dict=keywords (включено по умолчанию) и включения префиксного/вставочного режимов.
REGEX(/t.?e/)Требует установки min_infix_len или min_prefix_len и опций dict=keywords (по умолчанию).
Аналогично операторам подстановки, оператор REGEX пытается найти все токены, соответствующие заданному шаблону, и каждое расширение фиксируется как совпадающее попадание. Обратите внимание, это может существенно влиять на время поиска по запросу, так как просматривается весь словарь, и каждый термин проверяется на соответствие шаблону REGEX.
Шаблоны должны соответствовать синтаксису RE2. Разделитель выражения REGEX — первый символ после открывающей скобки. Иными словами, весь текст между открывающей скобкой с разделителем и разделителем с закрывающей скобкой считается выражением RE2.
Обратите внимание, что термины, хранящиеся в словаре, подвергаются преобразованию charset_table, то есть, например, REGEX может не распознать заглавные буквы, если все символы приведены к нижнему регистру в соответствии с charset_table (что происходит по умолчанию). Чтобы успешно сопоставить термин с помощью выражения REGEX, шаблон должен соответствовать всему токену целиком. Для частичного совпадения поставьте .* в начале и/или конце шаблона.
REGEX(/.{3}t/)
REGEX(/t.*\d*/)^hello world$Модификаторы ключевого слова начала и конца поля обеспечивают совпадение ключевого слова только если оно появляется в самом начале или в самом конце полнотекстового поля соответственно. Например, запрос "^hello world$" (в кавычках, чтобы объединить оператор фразы с модификаторами начала/конца) будет совпадать исключительно с документами, содержащими хотя бы одно поле с этими двумя конкретными ключевыми словами.
boosted^1.234 boostedfieldend$^1.234Модификатор усиления повышает оценку слова по IDF на указанный коэффициент в ранжировании, которое учитывает IDF. Он не влияет на процесс совпадения.
hello NEAR/3 world NEAR/4 "my test"Оператор NEAR является более универсальной версией оператора близости. Его синтаксис — NEAR/N, он чувствителен к регистру и не допускает пробелов между ключевым словом NEAR, слэшем и числом дистанции.
В то время как исходный оператор близости работает только с наборами ключевых слов, NEAR более универсален и может принимать произвольные подвыражения в качестве двух аргументов. Он совпадает с документом, когда оба подвыражения находятся на расстоянии не более N слов друг от друга, независимо от порядка. NEAR — левосторонне ассоциативный оператор с таким же (самым низким) приоритетом, как и BEFORE.
Важно отметить, что выражение one NEAR/7 two NEAR/7 three не полностью эквивалентно "one two three"~7. Главное отличие в том, что оператор близости допускает до 6 слов между всеми тремя совпадающими словами, а версия с NEAR менее строгая: она разрешает до 6 слов между one и two, а затем еще до 6 слов между найденной двухсловной группой и three.
Примечание: При использовании этого оператора с запросами, содержащими более 31 ключевого слова, статистика ранжирования (такая как tf, idf, bm25) для ключевых слов на позиции 31 и выше может быть недооценена. Это связано с использованием 32-битной маски для отслеживания вхождений терминов внутри совпадения. Логика сопоставления (поиск документов) остается корректной, но оценки ранжирования могут быть затронуты для очень длинных запросов.
Church NOTNEAR/3 streetОператор NOTNEAR служит отрицательным утверждением и функционирует как логическая инверсия оператора NEAR. Он находит совпадение в документе, когда левый аргумент присутствует, при условии, что правый аргумент либо отсутствует в документе, либо находится дальше указанного расстояния от левого аргумента.
Синтаксис: NOTNEAR/N, регистрозависимый, пробелы между ключевым словом NOTNEAR, знаком слэша и значением расстояния не допускаются.
Ключевые особенности:
- Симметричность: Как и
NEAR, операторNOTNEARприменяется независимо от порядка терминов в тексте. Он исключит совпадение, если правый аргумент будет найден в пределах указанного расстояния до или после левого аргумента. - Порог расстояния: Расстояние
Nпредставляет собой ближний диапазон (включительно). Если слова разделеныNсловами или меньше, совпадение отбрасывается. Правый аргумент должен находиться на расстоянииN + 1или более слов. - Аргументы: Оба аргумента этого оператора могут быть терминами, фразами или группами операторов.
all SENTENCE words SENTENCE "in one sentence""Bill Gates" PARAGRAPH "Steve Jobs"Операторы SENTENCE и PARAGRAPH находят совпадение в документе, когда оба их аргумента находятся в пределах одного предложения или одного абзаца текста, соответственно. Этими аргументами могут быть ключевые слова, фразы или экземпляры того же оператора.
Порядок аргументов внутри предложения или абзаца не имеет значения. Эти операторы работают только с таблицами, построенными с включенной функцией index_sp (индексация предложений и абзацев), и в противном случае сводятся к простой операции AND. Информацию о том, что считается предложением и абзацем, смотрите в документации директивы index_sp.
ZONE:(h3,h4)
only in these titlesОператор ZONE limit очень похож на оператор ограничения поля, но ограничивает совпадение указанной внутриполевой зоной или списком зон. Важно отметить, что последующие подвыражения не обязаны совпадать в пределах одного непрерывного сегмента данной зоны и могут совпадать в нескольких сегментах. Например, запрос (ZONE:th hello world) найдет совпадение в следующем примере документа:
<th>Table 1. Local awareness of Hello Kitty brand.</th>
.. some table data goes here ..
<th>Table 2. World-wide brand awareness.</th>Оператор ZONE действует на запрос до следующего оператора ограничения поля или ZONE, или до закрывающей скобки. Он работает исключительно с таблицами, построенными с поддержкой зон (см. index_zones), и в противном случае игнорируется.
ZONESPAN:(h2)
only in a (single) titleОператор ограничения ZONESPAN похож на оператор ZONE, но требует, чтобы совпадение происходило в пределах одного непрерывного сегмента. В приведенном ранее примере ZONESPAN:th hello world не нашел бы совпадения в документе, так как "hello" и "world" не появляются в одном сегменте.
Поскольку определенные символы функционируют как операторы в строке запроса, их необходимо экранировать, чтобы избежать ошибок запроса или непреднамеренных условий соответствия.
Следующие символы должны быть экранированы с помощью обратной косой черты (\):
! " $ ' ( ) - / < @ \ ^ | ~Чтобы экранировать одинарную кавычку ('), используйте одну обратную косую черту:
SELECT * FROM your_index WHERE MATCH('l\'italiano');Для остальных символов из упомянутого ранее списка, которые являются операторами или конструкциями запроса, они должны трактоваться движком как простые символы, с предшествующим символом экранирования. Сама обратная косая черта также должна быть экранирована, что приводит к двум обратным косым чертам:
SELECT * FROM your_index WHERE MATCH('r\\&b | \\(official video\\)');Чтобы использовать обратную косую черту как символ, вы должны экранировать и саму обратную косую черту как символ, и обратную косую черту как оператор экранирования, что требует четырех обратных косых черт:
SELECT * FROM your_index WHERE MATCH('\\\\ABC');Когда вы работаете с данными JSON в Manticore Search и вам нужно включить двойную кавычку (") внутрь строки JSON, важно обрабатывать её с правильным экранированием. В JSON двойная кавычка внутри строки экранируется с помощью обратной косой черты (\). Однако при вставке данных JSON через SQL-запрос Manticore Search интерпретирует обратную косую черту (\) как символ экранирования внутри строк.
Чтобы гарантировать корректную вставку двойной кавычки в данные JSON, вам нужно экранировать саму обратную косую черту. Это приводит к использованию двух обратных косых черт (\\) перед двойной кавычкой. Например:
insert into tbl(j) values('{"a": "\\"abc\\""}');Драйверы MySQL предоставляют функции экранирования (например, mysqli_real_escape_string в PHP или conn.escape_string в Python), но они экранируют только определенные символы.
Вам все равно потребуется добавить экранирование для символов из ранее упомянутого списка, которые не экранируются соответствующими функциями.
Поскольку эти функции экранируют обратную косую черту за вас, вам нужно добавить только одну обратную косую черту.
Это также применимо к драйверам, использующим подготовленные выражения (на стороне клиента или сервера). Manticore поддерживает подготовленные выражения на стороне сервера по протоколу MySQL, но MATCH() по-прежнему ожидает экранированную строку запроса. Например, при использовании подготовленных выражений PHP PDO вам нужно добавить обратную косую черту для символа $:
$statement = $ln_sph->prepare( "SELECT * FROM index WHERE MATCH(:match)");
$match = '\$manticore';
$statement->bindParam(':match',$match,PDO::PARAM_STR);
$results = $statement->execute();Это приводит к итоговому запросу SELECT * FROM index WHERE MATCH('\\$manticore');
Те же правила для SQL-протокола применяются, за исключением того, что для JSON двойная кавычка должна быть экранирована одной обратной косой чертой, в то время как остальные символы требуют двойного экранирования.
При использовании JSON-библиотек или функций, которые преобразуют структуры данных в JSON-строки, двойная кавычка и одинарная обратная косая черта автоматически экранируются этими функциями и не требуют явного экранирования.
Официальные клиенты используют под капотом распространенные JSON-библиотеки/функции, доступные в соответствующих языках программирования. Применяются те же правила экранирования, упомянутые ранее.
Звездочка (*) — это уникальный символ, который служит двум целям:
- как расширитель префикса/суффикса с подстановочным знаком
- как модификатор любого термина внутри фразового поиска.
В отличие от других специальных символов, которые функционируют как операторы, звездочку нельзя экранировать, когда она находится в позиции, обеспечивающей одну из её функциональностей.
В запросах без подстановочных знаков звездочка не требует экранирования, независимо от того, находится ли она в charset_table или нет.
В запросах с подстановочными знаками звездочка в середине слова не требует экранирования. Как оператор подстановочного знака (в начале или конце слова) звездочка всегда будет интерпретироваться как оператор подстановочного знака, даже если применено экранирование.
Для экранирования специальных символов в узлах JSON используйте обратную кавычку. Например:
MySQL [(none)]> select * from t where json.`a=b`=234;
+---------------------+-------------+------+
| id | json | text |
+---------------------+-------------+------+
| 8215557549554925578 | {"a=b":234} | |
+---------------------+-------------+------+
MySQL [(none)]> select * from t where json.`a:b`=123;
+---------------------+-------------+------+
| id | json | text |
+---------------------+-------------+------+
| 8215557549554925577 | {"a:b":123} | |
+---------------------+-------------+------+Рассмотрим этот сложный пример запроса:
"hello world" @title "example program"~5 @body python -(php|perl) @* codeПолное значение этого поиска:
- Найти слова 'hello' и 'world' рядом в любом поле документа;
- Кроме того, тот же документ должен содержать слова 'example' и 'program' в поле title, с расстоянием до, но не включая, 5 слов между ними; (Например, "example PHP program" подойдет, а "example script to introduce outside data into the correct context for your program" — нет, так как между двумя терминами 5 или более слов)
- Более того, тот же документ должен иметь слово 'python' в поле body, исключая 'php' или 'perl';
- Наконец, тот же документ должен включать слово 'code' в любом поле.
Оператор OR имеет приоритет над AND, поэтому "looking for cat | dog | mouse" означает "looking for (cat | dog | mouse)", а не "(looking for cat) | dog | mouse".
Чтобы понять, как будет выполнен запрос, Manticore Search предоставляет инструменты профилирования запросов для изучения дерева запросов, сгенерированного выражением запроса.
Чтобы включить профилирование полнотекстового запроса с помощью SQL-запроса, необходимо активировать его перед выполнением нужного запроса:
SET profiling =1;
SELECT * FROM test WHERE MATCH('@title abc* @body hey');Чтобы просмотреть дерево запросов, выполните команду SHOW PLAN сразу после выполнения запроса:
SHOW PLAN;Эта команда вернет структуру выполненного запроса. Имейте в виду, что 3 оператора - SET profiling, запрос и SHOW - должны быть выполнены в рамках одной сессии.
При использовании протокола HTTP JSON мы можем просто включить "profile":true, чтобы получить в ответе структуру дерева полнотекстового запроса.
{
"table":"test",
"profile":true,
"query":
{
"match_phrase": { "_all" : "had grown quite" }
}
}Ответ будет включать объект profile, содержащий член query.
Свойство query содержит преобразованное дерево полнотекстового запроса. Каждый узел состоит из:
type: тип узла, который может быть AND, OR, PHRASE, KEYWORD и т.д.description: поддерево запроса для этого узла, представленное в виде строки (в форматеSHOW PLAN)children: любые дочерние узлы, если они присутствуютmax_field_pos: максимальная позиция внутри поля
Узел ключевого слова дополнительно будет включать:
word: преобразованное ключевое слово.querypos: позиция этого ключевого слова в запросе.excluded: ключевое слово исключено из запроса.expanded: ключевое слово добавлено путем расширения префикса.field_start: ключевое слово должно появляться в начале поля.field_end: ключевое слово должно появляться в конце поля.boost: IDF ключевого слова будет умножено на это значение.
- SQL
- JSON
- PHP
- Python
- Python-asyncio
- javascript
- Java
- C#
- Rust
- TypeScript
- Go
SET profiling=1;
SELECT * FROM test WHERE MATCH('@title abc* @body hey');
SHOW PLAN \GPOST /search
{
"table": "forum",
"query": {"query_string": "i me"},
"_source": { "excludes":["*"] },
"limit": 1,
"profile":true
}$result = $index->search('i me')->setSource(['excludes'=>['*']])->setLimit(1)->profile()->get();
print_r($result->getProfile());searchApi.search({"table":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":True})await searchApi.search({"table":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":True})res = await searchApi.search({"table":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":true});query = new HashMap<String,Object>();
query.put("query_string","i me");
searchRequest = new SearchRequest();
searchRequest.setIndex("forum");
searchRequest.setQuery(query);
searchRequest.setProfile(true);
searchRequest.setLimit(1);
searchRequest.setSort(new ArrayList<String>(){{
add("*");
}});
searchResponse = searchApi.search(searchRequest);object query = new { query_string="i me" };
var searchRequest = new SearchRequest("forum", query);
searchRequest.Profile = true;
searchRequest.Limit = 1;
searchRequest.Sort = new List<Object> { "*" };
var searchResponse = searchApi.Search(searchRequest);let query = SearchQuery {
query_string: Some(serde_json::json!("i me").into()),
..Default::default()
};
let search_req = SearchRequest {
table: "forum".to_string(),
query: Some(Box::new(query)),
sort: serde_json::json!(["*"]),
limit: serde_json::json!(1),
profile: serde_json::json!(true),
..Default::default(),
};
let search_res = search_api.search(search_req).await;res = await searchApi.search({
index: 'test',
query: { query_string: 'Text' },
_source: { excludes: ['*'] },
limit: 1,
profile: true
});searchRequest := manticoresearch.NewSearchRequest("test")
query := map[string]interface{} {"query_string": "Text"}
source := map[string]interface{} { "excludes": []string {"*"} }
searchRequest.SetQuery(query)
searchRequest.SetSource(source)
searchReq.SetLimit(1)
searchReq.SetProfile(true)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()*************************** 1\. row ***************************
Variable: transformed_tree
Value: AND(
OR(fields=(title), KEYWORD(abcx, querypos=1, expanded), KEYWORD(abcm, querypos=1, expanded)),
AND(fields=(body), KEYWORD(hey, querypos=2)))
1 row in set (0.00 sec){
"took":1503,
"timed_out":false,
"hits":
{
"total":406301,
"hits":
[
{
"_id": 406443,
"_score":3493,
"_source":{}
}
]
},
"profile":
{
"query":
{
"type":"AND",
"description":"AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"children":
[
{
"type":"AND",
"description":"AND(KEYWORD(i, querypos=1))",
"children":
[
{
"type":"KEYWORD",
"word":"i",
"querypos":1
}
]
},
{
"type":"AND",
"description":"AND(KEYWORD(me, querypos=2))",
"children":
[
{
"type":"KEYWORD",
"word":"me",
"querypos":2
}
]
}
]
}
}
}Array
(
[query] => Array
(
[type] => AND
[description] => AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(KEYWORD(i, querypos=1))
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => i
[querypos] => 1
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(KEYWORD(me, querypos=2))
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => me
[querypos] => 2
)
)
)
)
)
){'hits': {'hits': [{u'_id': u'100', u'_score': 2500, u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'i'}],
u'description': u'AND(KEYWORD(i, querypos=1))',
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'me'}],
u'description': u'AND(KEYWORD(me, querypos=2))',
u'type': u'AND'}],
u'description': u'AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}{'hits': {'hits': [{u'_id': u'100', u'_score': 2500, u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'i'}],
u'description': u'AND(KEYWORD(i, querypos=1))',
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'me'}],
u'description': u'AND(KEYWORD(me, querypos=2))',
u'type': u'AND'}],
u'description': u'AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}{"hits": {"hits": [{"_id": 100, "_score": 2500, "_source": {}}],
"total": 1},
"profile": {"query": {"children": [{"children": [{"querypos": 1,
"type": "KEYWORD",
"word": "i"}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"},
{"children": [{"querypos": 2,
"type": "KEYWORD",
"word": "me"}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"}},
"timed_out": False,
"took": 0}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=100, _score=2500, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2))), children=[{type=AND, description=AND(KEYWORD(i, querypos=1)), children=[{type=KEYWORD, word=i, querypos=1}]}, {type=AND, description=AND(KEYWORD(me, querypos=2)), children=[{type=KEYWORD, word=me, querypos=2}]}]}}
}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=100, _score=2500, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2))), children=[{type=AND, description=AND(KEYWORD(i, querypos=1)), children=[{type=KEYWORD, word=i, querypos=1}]}, {type=AND, description=AND(KEYWORD(me, querypos=2)), children=[{type=KEYWORD, word=me, querypos=2}]}]}}
}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=100, _score=2500, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2))), children=[{type=AND, description=AND(KEYWORD(i, querypos=1)), children=[{type=KEYWORD, word=i, querypos=1}]}, {type=AND, description=AND(KEYWORD(me, querypos=2)), children=[{type=KEYWORD, word=me, querypos=2}]}]}}
}{
"hits":
{
"hits":
[{
"_id": 1,
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query": {
"children":
[{
"children":
[{
"querypos": 1,
"type": "KEYWORD",
"word": "i"
}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"
},
{
"children":
[{
"querypos": 2,
"type": "KEYWORD",
"word": "me"
}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"
}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"
}
},
"timed_out": False,
"took": 0
}{
"hits":
{
"hits":
[{
"_id": 1,
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query": {
"children":
[{
"children":
[{
"querypos": 1,
"type": "KEYWORD",
"word": "i"
}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"
},
{
"children":
[{
"querypos": 2,
"type": "KEYWORD",
"word": "me"
}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"
}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"
}
},
"timed_out": False,
"took": 0
}В некоторых случаях оцениваемое дерево запросов может значительно отличаться от исходного из-за расширений и других преобразований.
- SQL
- JSON
- PHP
- Python
- Python-asyncio
- javascript
- Java
- C#
- Rust
- TypeScript
- Go
SET profiling=1;
SELECT id FROM forum WHERE MATCH('@title way* @content hey') LIMIT 1;
SHOW PLAN;POST /search
{
"table": "forum",
"query": {"query_string": "@title way* @content hey"},
"_source": { "excludes":["*"] },
"limit": 1,
"profile":true
}$result = $index->search('@title way* @content hey')->setSource(['excludes'=>['*']])->setLimit(1)->profile()->get();
print_r($result->getProfile());searchApi.search({"table":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true})await searchApi.search({"table":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true})res = await searchApi.search({"table":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true});query = new HashMap<String,Object>();
query.put("query_string","@title way* @content hey");
searchRequest = new SearchRequest();
searchRequest.setIndex("forum");
searchRequest.setQuery(query);
searchRequest.setProfile(true);
searchRequest.setLimit(1);
searchRequest.setSort(new ArrayList<String>(){{
add("*");
}});
searchResponse = searchApi.search(searchRequest);object query = new { query_string="@title way* @content hey" };
var searchRequest = new SearchRequest("forum", query);
searchRequest.Profile = true;
searchRequest.Limit = 1;
searchRequest.Sort = new List<Object> { "*" };
var searchResponse = searchApi.Search(searchRequest);let query = SearchQuery {
query_string: Some(serde_json::json!("@title way* @content hey").into()),
..Default::default()
};
let search_req = SearchRequest {
table: "forum".to_string(),
query: Some(Box::new(query)),
sort: serde_json::json!(["*"]),
limit: serde_json::json!(1),
profile: serde_json::json!(true),
..Default::default(),
};
let search_res = search_api.search(search_req).await;res = await searchApi.search({
index: 'test',
query: { query_string: '@content 1'},
_source: { excludes: ["*"] },
limit:1,
profile":true
});searchRequest := manticoresearch.NewSearchRequest("test")
query := map[string]interface{} {"query_string": "1*"}
source := map[string]interface{} { "excludes": []string {"*"} }
searchRequest.SetQuery(query)
searchRequest.SetSource(source)
searchReq.SetLimit(1)
searchReq.SetProfile(true)
res, _, _ := apiClient.SearchAPI.Search(context.Background()).SearchRequest(*searchRequest).Execute()Query OK, 0 rows affected (0.00 sec)
+--------+
| id |
+--------+
| 711651 |
+--------+
1 row in set (0.04 sec)
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Variable | Value |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| transformed_tree | AND(
OR(
OR(
AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)),
OR(
AND(fields=(title), KEYWORD(ways, querypos=1, expanded)),
AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))),
AND(fields=(title), KEYWORD(way, querypos=1, expanded)),
OR(fields=(title), KEYWORD(way*, querypos=1, expanded))),
AND(fields=(content), KEYWORD(hey, querypos=2))) |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec){
"took":33,
"timed_out":false,
"hits":
{
"total":105,
"hits":
[
{
"_id": 711651,
"_score":2539,
"_source":{}
}
]
},
"profile":
{
"query":
{
"type":"AND",
"description":"AND( OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded))), AND(fields=(content), KEYWORD(hey, querypos=2)))",
"children":
[
{
"type":"OR",
"description":"OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded)))",
"children":
[
{
"type":"OR",
"description":"OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))))",
"children":
[
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(wayne, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"wayne",
"querypos":1,
"expanded":true
}
]
},
{
"type":"OR",
"description":"OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))",
"children":
[
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(ways, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"ways",
"querypos":1,
"expanded":true
}
]
},
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"wayyy",
"querypos":1,
"expanded":true
}
]
}
]
}
]
},
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(way, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"way",
"querypos":1,
"expanded":true
}
]
},
{
"type":"OR",
"description":"OR(fields=(title), KEYWORD(way*, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"way*",
"querypos":1,
"expanded":true
}
]
}
]
},
{
"type":"AND",
"description":"AND(fields=(content), KEYWORD(hey, querypos=2))",
"fields":["content"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"hey",
"querypos":2
}
]
}
]
}
}
}Array
(
[query] => Array
(
[type] => AND
[description] => AND( OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded))), AND(fields=(content), KEYWORD(hey, querypos=2)))
[children] => Array
(
[0] => Array
(
[type] => OR
[description] => OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded)))
[children] => Array
(
[0] => Array
(
[type] => OR
[description] => OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(wayne, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => wayne
[querypos] => 1
[expanded] => 1
)
)
)
[1] => Array
(
[type] => OR
[description] => OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(ways, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => ways
[querypos] => 1
[expanded] => 1
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => wayyy
[querypos] => 1
[expanded] => 1
)
)
)
)
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(way, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => way
[querypos] => 1
[expanded] => 1
)
)
)
[2] => Array
(
[type] => OR
[description] => OR(fields=(title), KEYWORD(way*, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => way*
[querypos] => 1
[expanded] => 1
)
)
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(content), KEYWORD(hey, querypos=2))
[fields] => Array
(
[0] => content
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => hey
[querypos] => 2
)
)
)
)
)
){'hits': {'hits': [{u'_id': u'2811025403043381551',
u'_score': 2643,
u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'expanded': True,
u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'way*'}],
u'description': u'AND(fields=(title), KEYWORD(way*, querypos=1, expanded))',
u'fields': [u'title'],
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'hey'}],
u'description': u'AND(fields=(content), KEYWORD(hey, querypos=2))',
u'fields': [u'content'],
u'type': u'AND'}],
u'description': u'AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}{'hits': {'hits': [{u'_id': u'2811025403043381551',
u'_score': 2643,
u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'expanded': True,
u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'way*'}],
u'description': u'AND(fields=(title), KEYWORD(way*, querypos=1, expanded))',
u'fields': [u'title'],
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'hey'}],
u'description': u'AND(fields=(content), KEYWORD(hey, querypos=2))',
u'fields': [u'content'],
u'type': u'AND'}],
u'description': u'AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}{"hits": {"hits": [{"_id": 2811025403043381551,
"_score": 2643,
"_source": {}}],
"total": 1},
"profile": {"query": {"children": [{"children": [{"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "way*"}],
"description": "AND(fields=(title), KEYWORD(way*, querypos=1, expanded))",
"fields": ["title"],
"type": "AND"},
{"children": [{"querypos": 2,
"type": "KEYWORD",
"word": "hey"}],
"description": "AND(fields=(content), KEYWORD(hey, querypos=2))",
"fields": ["content"],
"type": "AND"}],
"description": "AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))",
"type": "AND"}},
"timed_out": False,
"took": 0}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=2811025403043381551, _score=2643, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2))), children=[{type=AND, description=AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), fields=[title], children=[{type=KEYWORD, word=way*, querypos=1, expanded=true}]}, {type=AND, description=AND(fields=(content), KEYWORD(hey, querypos=2)), fields=[content], children=[{type=KEYWORD, word=hey, querypos=2}]}]}}
}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=2811025403043381551, _score=2643, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2))), children=[{type=AND, description=AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), fields=[title], children=[{type=KEYWORD, word=way*, querypos=1, expanded=true}]}, {type=AND, description=AND(fields=(content), KEYWORD(hey, querypos=2)), fields=[content], children=[{type=KEYWORD, word=hey, querypos=2}]}]}}
}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=2811025403043381551, _score=2643, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2))), children=[{type=AND, description=AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), fields=[title], children=[{type=KEYWORD, word=way*, querypos=1, expanded=true}]}, {type=AND, description=AND(fields=(content), KEYWORD(hey, querypos=2)), fields=[content], children=[{type=KEYWORD, word=hey, querypos=2}]}]}}
}{
"hits":
{
"hits":
[{
"_id": 1,
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query":
{
"children":
[{
"children":
[{
"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "1*"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1, expanded))",
"fields": ["content"],
"type": "AND"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1))",
"type": "AND"
}},
"timed_out": False,
"took": 0
}{
"hits":
{
"hits":
[{
"_id": 1,
"_score": 1480,
"_source": {}
}],
"total": 1
},
"profile":
{
"query":
{
"children":
[{
"children":
[{
"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "1*"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1, expanded))",
"fields": ["content"],
"type": "AND"
}],
"description": "AND(fields=(content), KEYWORD(1*, querypos=1))",
"type": "AND"
}},
"timed_out": False,
"took": 0
}SQL-запрос EXPLAIN QUERY позволяет отобразить дерево выполнения для заданного полнотекстового запроса без фактического выполнения поискового запроса по таблице.
- SQL
EXPLAIN QUERY index_base '@title running @body dog'\G EXPLAIN QUERY index_base '@title running @body dog'\G
*************************** 1\. row ***************************
Variable: transformed_tree
Value: AND(
OR(
AND(fields=(title), KEYWORD(run, querypos=1, morphed)),
AND(fields=(title), KEYWORD(running, querypos=1, morphed))))
AND(fields=(body), KEYWORD(dog, querypos=2, morphed)))EXPLAIN QUERY ... option format=dot позволяет отобразить дерево выполнения предоставленного полнотекстового запроса в иерархическом формате, подходящем для визуализации существующими инструментами, такими как https://dreampuf.github.io/GraphvizOnline:
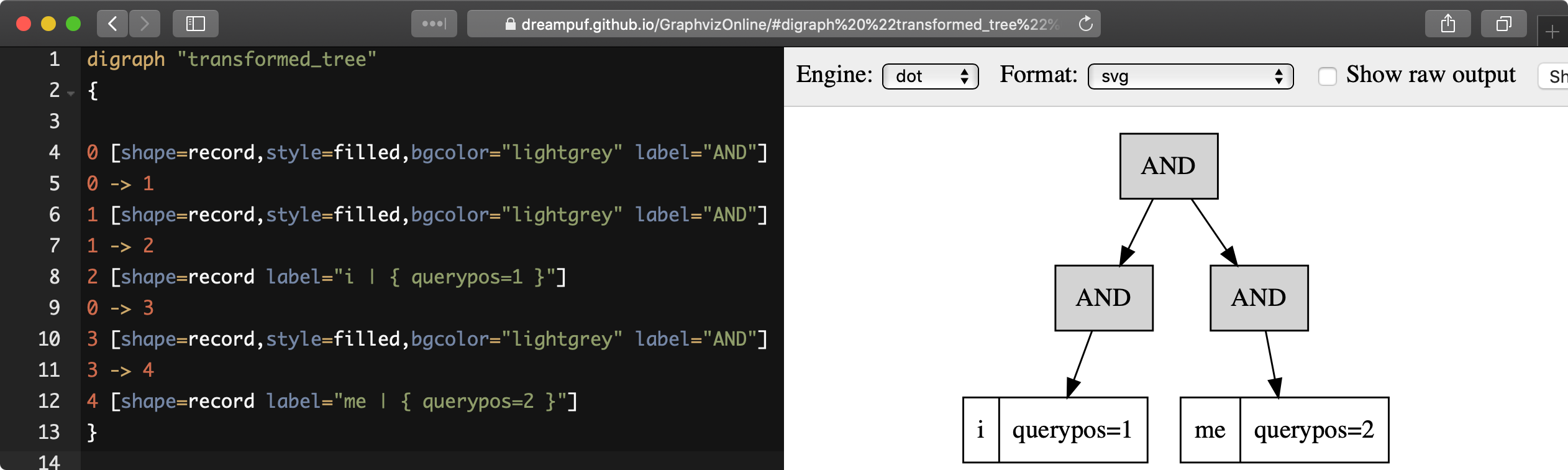
- SQL
EXPLAIN QUERY tbl 'i me' option format=dot\GEXPLAIN QUERY tbl 'i me' option format=dot\G
*************************** 1. row ***************************
Variable: transformed_tree
Value: digraph "transformed_tree"
{
0 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
0 -> 1
1 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
1 -> 2
2 [shape=record label="i | { querypos=1 }"]
0 -> 3
3 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
3 -> 4
4 [shape=record label="me | { querypos=2 }"]
}При использовании ранкера выражений можно раскрыть значения вычисленных факторов с помощью функции PACKEDFACTORS().
Функция возвращает:
- Значения факторов на уровне документа (таких как bm25, field_mask, doc_word_count)
- Список каждого поля, в котором было найдено совпадение (включая lcs, hit_count, word_count, sum_idf, min_hit_pos и т.д.)
- Список каждого ключевого слова из запроса вместе с их значениями tf и idf
Эти значения могут быть использованы для понимания того, почему определенные документы получают более низкие или более высокие оценки при поиске, или для уточнения существующего ранжирующего выражения.
- SQL
SELECT id, PACKEDFACTORS() FROM test1 WHERE MATCH('test one') OPTION ranker=expr('1')\G id: 1
packedfactors(): bm25=569, bm25a=0.617197, field_mask=2, doc_word_count=2,
field1=(lcs=1, hit_count=2, word_count=2, tf_idf=0.152356,
min_idf=-0.062982, max_idf=0.215338, sum_idf=0.152356, min_hit_pos=4,
min_best_span_pos=4, exact_hit=0, max_window_hits=1, min_gaps=2,
exact_order=1, lccs=1, wlccs=0.215338, atc=-0.003974),
word0=(tf=1, idf=-0.062982),
word1=(tf=1, idf=0.215338)
1 row in set (0.00 sec)