Исправление орфографии, также известное как:
- Автокоррекция
- Коррекция текста
- Исправление орфографических ошибок
- Допуск опечаток
- "Возможно, вы имели в виду?"
и так далее, это функциональность программного обеспечения, которая предлагает альтернативы или автоматически исправляет введённый вами текст. Концепция исправления набранного текста восходит к 1960-м годам, когда учёный-компьютерщик Уоррен Тейтельман, который также изобрёл команду "отменить", представил философию вычислений под названием D.W.I.M., или "Делай Что Я Имею в Виду". Вместо того чтобы программировать компьютеры на приём только идеально отформатированных инструкций, Тейтельман утверждал, что их следует программировать на распознавание очевидных ошибок.
Первым известным продуктом, предоставившим функциональность исправления орфографии, был Microsoft Word 6.0, выпущенный в 1993 году.
Есть несколько способов реализации исправления орфографии, но важно отметить, что не существует чисто программного способа с достойным качеством преобразовать вашу опечатку "ipone" в "iphone". В основном, необходима система, основанная на наборе данных. Набор данных может быть:
- Словарём правильно написанных слов, который, в свою очередь, может быть:
- Основан на ваших реальных данных. Идея здесь в том, что по большей части орфография в словаре, составленном из ваших данных, правильная, и система пытается найти слово, наиболее похожее на введённое (мы скоро обсудим, как это можно сделать с помощью Manticore).
- Или он может быть основан на внешнем словаре, не связанном с вашими данными. Проблема, которая может здесь возникнуть, заключается в том, что ваши данные и внешний словарь могут слишком сильно отличаться: некоторые слова могут отсутствовать в словаре, в то время как другие могут отсутствовать в ваших данных.
- Не только основанным на словаре, но и учитывающим контекст, например, "white ber" будет исправлено на "white bear", а "dark ber" — на "dark beer". Контекстом может быть не только соседнее слово в вашем запросе, но и ваше местоположение, время суток, грамматика текущего предложения (чтобы изменить "there" на "their" или нет), история ваших поисков и практически любые другие факторы, которые могут повлиять на ваше намерение.
- Ещё один классический подход — использовать предыдущие поисковые запросы в качестве набора данных для исправления орфографии. Это ещё более активно используется в функциональности автодополнения, но также имеет смысл и для автокоррекции. Идея в том, что пользователи в основном правы в орфографии, поэтому мы можем использовать слова из истории их поиска в качестве источника истины, даже если у нас нет этих слов в наших документах или мы не используем внешний словарь. Учёт контекста также возможен здесь.
Manticore предоставляет опцию нечёткого поиска и команды CALL QSUGGEST и CALL SUGGEST, которые могут быть использованы для целей автоматического исправления орфографии.
Функция нечёткого поиска позволяет осуществлять более гибкое сопоставление, учитывая небольшие вариации или опечатки в поисковом запросе. Она работает аналогично обычному оператору SQL SELECT или JSON-запросу /search, но предоставляет дополнительные параметры для управления поведением нечёткого сопоставления.
ПРИМЕЧАНИЕ: Опция
fuzzyтребует наличия Manticore Buddy. Если она не работает, убедитесь, что Buddy установлен.
ПРИМЕЧАНИЕ: Опция
fuzzyнедоступна для многозапросов.
SELECT
...
MATCH('...')
...
OPTION fuzzy={0|1}
[, distance=N]
[, preserve={0|1}]
[, layouts='{be,bg,br,ch,de,dk,es,fr,uk,gr,it,no,pt,ru,se,ua,us}']
}Примечание: При проведении нечёткого поиска через SQL, в выражении MATCH не должно быть никаких полнотекстовых операторов, кроме оператора поиска по фразе, и оно должно содержать только слова, которые вы намерены сопоставить.
- SQL
- SQL with additional filters
- JSON
- SQL with preserve option
- JSON with preserve option
SELECT * FROM mytable WHERE MATCH('someting') OPTION fuzzy=1, layouts='us,ua', distance=2;Пример более сложного запроса нечёткого поиска с дополнительными фильтрами:
SELECT * FROM mytable WHERE MATCH('someting') OPTION fuzzy=1 AND (category='books' AND price < 20);POST /search
{
"table": "test",
"query": {
"bool": {
"must": [
{
"match": {
"*": "ghbdtn"
}
}
]
}
},
"options": {
"fuzzy": true,
"layouts": ["us", "ru"],
"distance": 2
}
}SELECT * FROM mytable WHERE MATCH('hello wrld') OPTION fuzzy=1, preserve=1;POST /search
{
"table": "test",
"query": {
"bool": {
"must": [
{
"match": {
"*": "hello wrld"
}
}
]
}
},
"options": {
"fuzzy": true,
"preserve": 1
}
}+------+-------------+
| id | content |
+------+-------------+
| 1 | something |
| 2 | some thing |
+------+-------------+
2 rows in set (0.00 sec)+------+-------------+
| id | content |
+------+-------------+
| 1 | hello wrld |
| 2 | hello world |
+------+-------------+
2 rows in set (0.00 sec)POST /search
{
"table": "table_name",
"query": {
<full-text query>
},
"options": {
"fuzzy": {true|false}
[,"layouts": ["be","bg","br","ch","de","dk","es","fr","uk","gr","it","no","pt","ru","se","ua","us"]]
[,"distance": N]
[,"preserve": {0|1}]
}
}Примечание: Если вы используете query_string, имейте в виду, что он не поддерживает полнотекстовые операторы, кроме оператора поиска по фразе. Строка запроса должна состоять исключительно из слов, которые вы хотите сопоставить.
fuzzy: Включает или выключает нечёткий поиск.distance: Устанавливает расстояние Левенштейна для сопоставления. По умолчанию2.preserve:0или1(по умолчанию:0). При установке в1сохраняет слова, не имеющие нечётких совпадений, в результатах поиска (например, "hello wrld" возвращает и "hello wrld", и "hello world"). При установке в0возвращает только слова с успешными нечёткими совпадениями (например, "hello wrld" возвращает только "hello world"). Особенно полезно для сохранения коротких слов или имён собственных, которых может не быть в Manticore Search.layouts: Раскладки клавиатуры для обнаружения ошибок ввода, вызванных несоответствием раскладки клавиатуры (например, ввод "ghbdtn" вместо "привет" при использовании неправильной раскладки). Manticore сравнивает позиции символов в разных раскладках, чтобы предложить исправления. Требуется как минимум 2 раскладки для эффективного обнаружения несоответствий. По умолчанию раскладки не используются. Используйте пустую строку''(SQL) или массив[](JSON), чтобы отключить это. Поддерживаемые раскладки включают:be- Бельгийская раскладка AZERTYbg- Стандартная болгарская раскладкаbr- Бразильская раскладка QWERTYch- Швейцарская раскладка QWERTZde- Немецкая раскладка QWERTZdk- Датская раскладка QWERTYes- Испанская раскладка QWERTYfr- Французская раскладка AZERTYuk- Британская раскладка QWERTYgr- Греческая раскладка QWERTYit- Итальянская раскладка QWERTYno- Норвежская раскладка QWERTYpt- Португальская раскладка QWERTYru- Русская раскладка JCUKENse- Шведская раскладка QWERTYua- Украинская раскладка JCUKENus- Американская раскладка QWERTY
- Это демо демонстрирует функциональность нечёткого поиска:
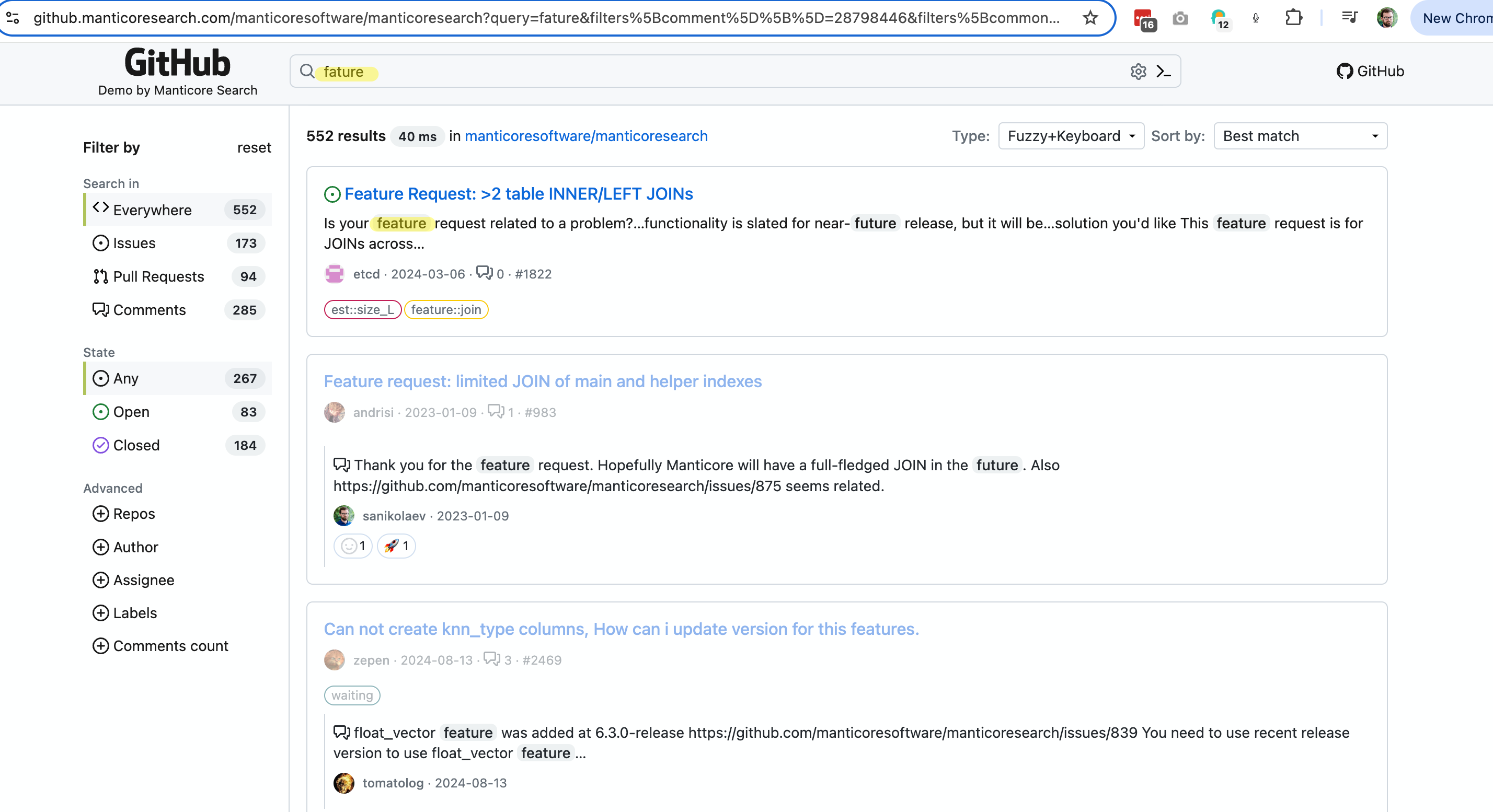
- Пост в блоге о Нечётком поиске и автодополнении - https://manticoresearch.com/blog/new-fuzzy-search-and-autocomplete/
Обе команды доступны через SQL и поддерживают запросы к локальным (plain и real-time) и распределённым таблицам. Синтаксис следующий:
CALL QSUGGEST(<word or words>, <table name> [,options])
CALL SUGGEST(<word or words>, <table name> [,options])
options: N as option_name[, M as another_option, ...]Эти команды предоставляют все предложения из словаря для заданного слова. Они работают только с таблицами, у которых включено инфиксирование и используется dict=keywords. Они возвращают предлагаемые ключевые слова, расстояние Левенштейна между предложенным и исходным ключевым словом, а также статистику документов по предложенному ключевому слову.
Если первый параметр содержит несколько слов, то:
CALL QSUGGESTвернёт предложения только для последнего слова, игнорируя остальные.CALL SUGGESTвернёт предложения только для первого слова.
Это единственное различие между ними. Поддерживается несколько опций для настройки:
| Опция | Описание | По умолчанию |
|---|---|---|
| limit | Возвращает N лучших совпадений | 5 |
| max_edits | Оставляет только слова из словаря с расстоянием Левенштейна меньше или равным N | 4 |
| result_stats | Предоставляет расстояние Левенштейна и количество документов для найденных слов | 1 (включено) |
| delta_len | Оставляет только слова из словаря с разницей в длине меньше N | 3 |
| max_matches | Количество совпадений для сохранения | 25 |
| reject | Отклонённые слова — это совпадения, которые не лучше уже находящихся в очереди совпадений. Они помещаются в очередь отклонённых, которая сбрасывается, если слово всё же может попасть в очередь совпадений. Этот параметр определяет размер очереди отклонённых (как reject*max(max_matched,limit)). Если очередь отклонённых заполнена, движок прекращает поиск потенциальных совпадений | 4 |
| result_line | альтернативный режим отображения данных, возвращающий все предложения, расстояния и количество документов каждое в отдельной строке | 0 |
| non_char | не пропускать слова из словаря с неалфавитными символами | 0 (пропускать такие слова) |
| sentence | Возвращает исходное предложение с заменой последнего слова на подобранное. | 0 (не возвращать полное предложение) |
| force_bigrams | Принудительно использовать биграммы (n-граммы из 2 символов) вместо триграмм для всех длин слов, что может улучшить сопоставление для слов с ошибками транспозиции | 0 (использовать триграммы для слов ≥6 символов) |
| search_mode | Уточняет предложения, выполняя поиск по индексу. Принимает 'phrase' для точного соответствия фразы или 'words' для соответствия по модели "мешок слов". При включении добавляет столбец found_docs, показывающий количество документов, и пересортировывает результаты по убыванию found_docs, затем по возрастанию distance. |
N/A (отключено по умолчанию) |
Чтобы показать, как это работает, создадим таблицу и добавим в неё несколько документов.
create table products(title text) min_infix_len='2';
insert into products values (0,'Crossbody Bag with Tassel'), (0,'microfiber sheet set'), (0,'Pet Hair Remover Glove');Как видно, слово с опечаткой "crossbUdy" исправляется на "crossbody". По умолчанию CALL SUGGEST/QSUGGEST возвращают:
distance— расстояние Левенштейна, означающее, сколько правок потребовалось, чтобы преобразовать заданное слово в предложенноеdocs— количество документов, содержащих предложенное слово
Чтобы отключить отображение этой статистики, можно использовать опцию 0 as result_stats.
- Example
call suggest('crossbudy', 'products');+-----------+----------+------+
| suggest | distance | docs |
+-----------+----------+------+
| crossbody | 1 | 1 |
+-----------+----------+------+Если первый параметр — не одно слово, а несколько, то CALL SUGGEST вернёт предложения только для первого слова.
- Example
call suggest('bagg with tasel', 'products');+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| bag | 1 | 1 |
+---------+----------+------+Если первый параметр — не одно слово, а несколько, то CALL SUGGEST вернёт предложения только для последнего слова.
- Example
CALL QSUGGEST('bagg with tasel', 'products');+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| tassel | 1 | 1 |
+---------+----------+------+Добавление 1 as sentence заставляет CALL QSUGGEST возвращать всё предложение с исправленным последним словом.
- Example
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence);+-------------------+----------+------+
| suggest | distance | docs |
+-------------------+----------+------+
| bag with tassel | 1 | 1 |
+-------------------+----------+------+Опция 1 as result_line меняет способ отображения предложений в выводе. Вместо показа каждого предложения в отдельной строке, она отображает все предложения, расстояния и количество документов в одной строке. Вот пример, демонстрирующий это:
CALL QSUGGEST('bagg with tasel', 'products', 1 as result_line);+----------+--------+
| name | value |
+----------+--------+
| suggests | tassel |
| distance | 1 |
| docs | 1 |
+----------+--------+Опция force_bigrams может помочь со словами, содержащими ошибки транспозиции, например, "ipohne" и "iphone". Используя биграммы вместо триграмм, алгоритм может лучше обрабатывать перестановки символов.
CALL SUGGEST('ipohne', 'products', 1 as force_bigrams);+--------+----------+------+
| suggest| distance | docs |
+--------+----------+------+
| iphone | 2 | 1 |
+--------+----------+------+Опция search_mode улучшает предложения, выполняя фактические поисковые запросы по индексу для подсчёта количества документов, содержащих каждую предложенную фразу или комбинацию слов. Это помогает ранжировать предложения на основе реальной релевантности документов, а не только статистики словаря.
Опция принимает два значения:
'phrase'- Выполняет поиск точных фраз. Например, при предложении "bag with tassel" выполняется поиск точной фразы"bag with tassel"и подсчитываются документы, содержащие эти слова как смежную фразу.'words'- Выполняет поиск по модели "мешок слов". Например, при предложении "bag with tassel" выполняется поискbag with tassel(без кавычек) и подсчитываются документы, содержащие все эти слова, независимо от порядка или наличия других слов между ними.
ПРИМЕЧАНИЕ: Опция
search_modeработает только тогда, когда включен режимsentence(т.е. когда ввод содержит несколько слов). Для запросов из одного словаsearch_modeигнорируется.
ПРИМЕЧАНИЕ: Соображения производительности: Каждый кандидат на предложение запускает отдельный поисковый запрос к индексу. Если вам нужно оценить много кандидатов, рассмотрите использование меньшего значения
limit, чтобы сократить количество выполняемых поисков.
Когда search_mode включен, результаты включают столбец found_docs, показывающий количество документов для каждого предложения, и результаты пересортировываются по убыванию found_docs, а затем по возрастанию distance.
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence, 'phrase' as search_mode);+-------------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+-------------------+----------+------+-------------+
| bag with tassel | 1 | 13 | 10 |
| bag with tazer | 2 | 27 | 3 |
+-------------------+----------+------+-------------+-- With phrase matching: finds exact phrases only
CALL QSUGGEST('test carp', 'products', 1 as sentence, 'phrase' as search_mode);
-- With words matching: finds documents with all words regardless of order
CALL QSUGGEST('test carp', 'products', 1 as sentence, 'words' as search_mode);-- Phrase mode results:
+----------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+----------------+----------+------+-------------+
| test car | 1 | 17 | 5 |
| test carpet | 2 | 19 | 4 |
+----------------+----------+------+-------------+
-- Words mode results (more matches for "test carpet" due to word separation):
+----------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+----------------+----------+------+-------------+
| test carpet | 2 | 19 | 19 |
| test car | 1 | 17 | 5 |
+----------------+----------+------+-------------+Понимание разницы:
- Фразовое соответствие (
'phrase'): Ищет точные последовательности. Запрос"test carpet"соответствует только документам, где эти слова встречаются вместе в точном порядке (например, "test carpet cleaning" соответствует, а "test the carpet" или "carpet test" - нет). - Соответствие по модели "мешок слов" (
'words'): Ищет наличие всех слов в документе, порядок не имеет значения. Запросtest carpetсоответствует любому документу, содержащему оба слова "test" и "carpet" где угодно (например, "test the carpet", "test red carpet", "carpet test" - все соответствуют).
- Этот интерактивный курс показывает, как работает
CALL SUGGESTв небольшом веб-приложении.
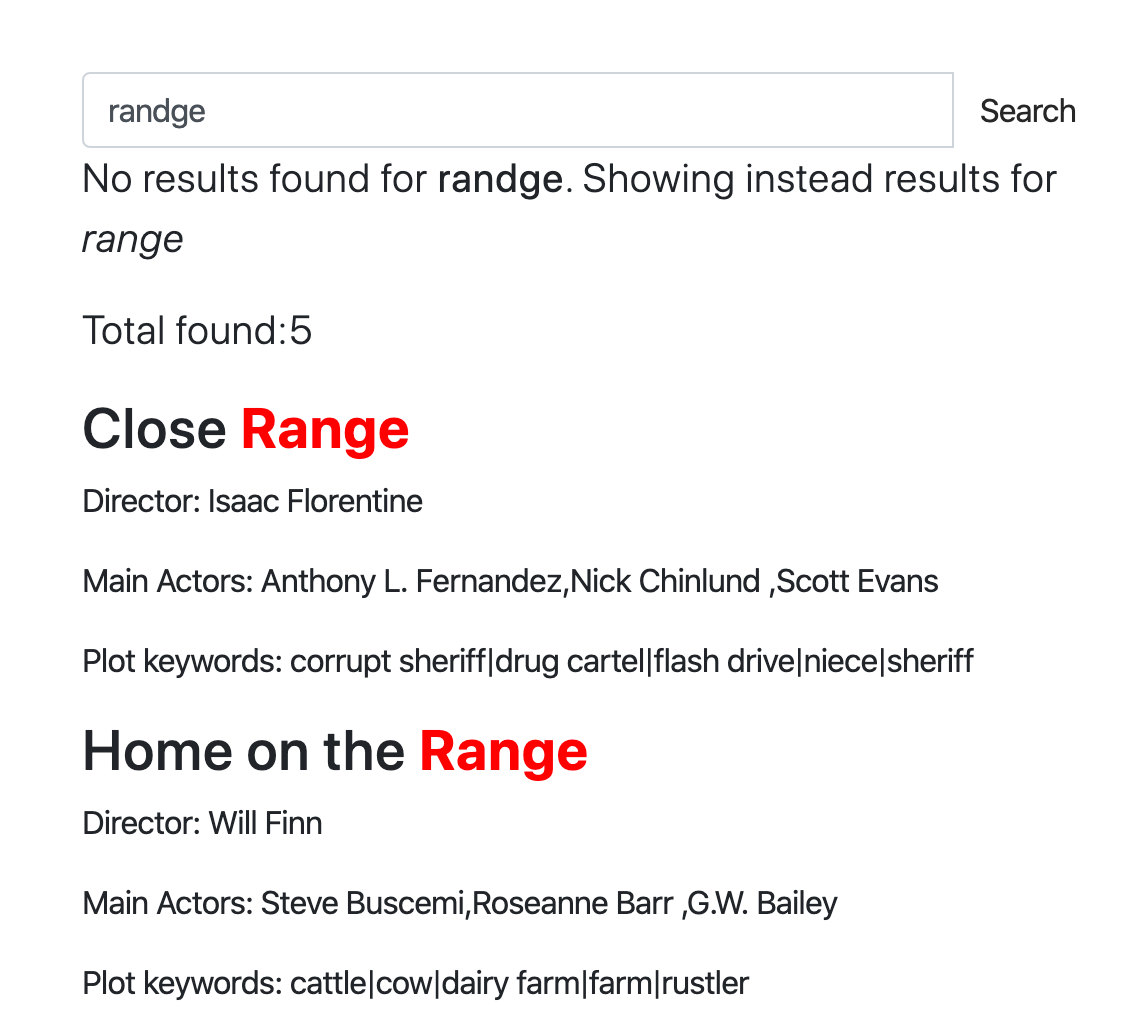
Исправление орфографии, также известное как:
- Автокоррекция
- Коррекция текста
- Исправление орфографических ошибок
- Допуск опечаток
- "Возможно, вы имели в виду?"
и так далее, это функциональность программного обеспечения, которая предлагает альтернативы или автоматически исправляет введённый вами текст. Концепция исправления набранного текста восходит к 1960-м годам, когда учёный-компьютерщик Уоррен Тейтельман, который также изобрёл команду "отменить", представил философию вычислений под названием D.W.I.M., или "Делай Что Я Имею в Виду". Вместо того чтобы программировать компьютеры на приём только идеально отформатированных инструкций, Тейтельман утверждал, что их следует программировать на распознавание очевидных ошибок.
Первым известным продуктом, предоставившим функциональность исправления орфографии, был Microsoft Word 6.0, выпущенный в 1993 году.
Есть несколько способов реализации исправления орфографии, но важно отметить, что не существует чисто программного способа с достойным качеством преобразовать вашу опечатку "ipone" в "iphone". В основном, необходима система, основанная на наборе данных. Набор данных может быть:
- Словарём правильно написанных слов, который, в свою очередь, может быть:
- Основан на ваших реальных данных. Идея здесь в том, что по большей части орфография в словаре, составленном из ваших данных, правильная, и система пытается найти слово, наиболее похожее на введённое (мы скоро обсудим, как это можно сделать с помощью Manticore).
- Или он может быть основан на внешнем словаре, не связанном с вашими данными. Проблема, которая может здесь возникнуть, заключается в том, что ваши данные и внешний словарь могут слишком сильно отличаться: некоторые слова могут отсутствовать в словаре, в то время как другие могут отсутствовать в ваших данных.
- Не только основанным на словаре, но и учитывающим контекст, например, "white ber" будет исправлено на "white bear", а "dark ber" — на "dark beer". Контекстом может быть не только соседнее слово в вашем запросе, но и ваше местоположение, время суток, грамматика текущего предложения (чтобы изменить "there" на "their" или нет), история ваших поисков и практически любые другие факторы, которые могут повлиять на ваше намерение.
- Ещё один классический подход — использовать предыдущие поисковые запросы в качестве набора данных для исправления орфографии. Это ещё более активно используется в функциональности автодополнения, но также имеет смысл и для автокоррекции. Идея в том, что пользователи в основном правы в орфографии, поэтому мы можем использовать слова из истории их поиска в качестве источника истины, даже если у нас нет этих слов в наших документах или мы не используем внешний словарь. Учёт контекста также возможен здесь.
Manticore предоставляет опцию нечёткого поиска и команды CALL QSUGGEST и CALL SUGGEST, которые могут быть использованы для целей автоматического исправления орфографии.
Функция нечёткого поиска позволяет осуществлять более гибкое сопоставление, учитывая небольшие вариации или опечатки в поисковом запросе. Она работает аналогично обычному оператору SQL SELECT или JSON-запросу /search, но предоставляет дополнительные параметры для управления поведением нечёткого сопоставления.
ПРИМЕЧАНИЕ: Опция
fuzzyтребует наличия Manticore Buddy. Если она не работает, убедитесь, что Buddy установлен.
ПРИМЕЧАНИЕ: Опция
fuzzyнедоступна для многозапросов.
SELECT
...
MATCH('...')
...
OPTION fuzzy={0|1}
[, distance=N]
[, preserve={0|1}]
[, layouts='{be,bg,br,ch,de,dk,es,fr,uk,gr,it,no,pt,ru,se,ua,us}']
}Примечание: При проведении нечёткого поиска через SQL, в выражении MATCH не должно быть никаких полнотекстовых операторов, кроме оператора поиска по фразе, и оно должно содержать только слова, которые вы намерены сопоставить.
- SQL
- SQL with additional filters
- JSON
- SQL with preserve option
- JSON with preserve option
SELECT * FROM mytable WHERE MATCH('someting') OPTION fuzzy=1, layouts='us,ua', distance=2;Пример более сложного запроса нечёткого поиска с дополнительными фильтрами:
SELECT * FROM mytable WHERE MATCH('someting') OPTION fuzzy=1 AND (category='books' AND price < 20);POST /search
{
"table": "test",
"query": {
"bool": {
"must": [
{
"match": {
"*": "ghbdtn"
}
}
]
}
},
"options": {
"fuzzy": true,
"layouts": ["us", "ru"],
"distance": 2
}
}SELECT * FROM mytable WHERE MATCH('hello wrld') OPTION fuzzy=1, preserve=1;POST /search
{
"table": "test",
"query": {
"bool": {
"must": [
{
"match": {
"*": "hello wrld"
}
}
]
}
},
"options": {
"fuzzy": true,
"preserve": 1
}
}+------+-------------+
| id | content |
+------+-------------+
| 1 | something |
| 2 | some thing |
+------+-------------+
2 rows in set (0.00 sec)+------+-------------+
| id | content |
+------+-------------+
| 1 | hello wrld |
| 2 | hello world |
+------+-------------+
2 rows in set (0.00 sec)POST /search
{
"table": "table_name",
"query": {
<full-text query>
},
"options": {
"fuzzy": {true|false}
[,"layouts": ["be","bg","br","ch","de","dk","es","fr","uk","gr","it","no","pt","ru","se","ua","us"]]
[,"distance": N]
[,"preserve": {0|1}]
}
}Примечание: Если вы используете query_string, имейте в виду, что он не поддерживает полнотекстовые операторы, кроме оператора поиска по фразе. Строка запроса должна состоять исключительно из слов, которые вы хотите сопоставить.
fuzzy: Включает или выключает нечёткий поиск.distance: Устанавливает расстояние Левенштейна для сопоставления. По умолчанию2.preserve:0или1(по умолчанию:0). При установке в1сохраняет слова, не имеющие нечётких совпадений, в результатах поиска (например, "hello wrld" возвращает и "hello wrld", и "hello world"). При установке в0возвращает только слова с успешными нечёткими совпадениями (например, "hello wrld" возвращает только "hello world"). Особенно полезно для сохранения коротких слов или имён собственных, которых может не быть в Manticore Search.layouts: Раскладки клавиатуры для обнаружения ошибок ввода, вызванных несоответствием раскладки клавиатуры (например, ввод "ghbdtn" вместо "привет" при использовании неправильной раскладки). Manticore сравнивает позиции символов в разных раскладках, чтобы предложить исправления. Требуется как минимум 2 раскладки для эффективного обнаружения несоответствий. По умолчанию раскладки не используются. Используйте пустую строку''(SQL) или массив[](JSON), чтобы отключить это. Поддерживаемые раскладки включают:be- Бельгийская раскладка AZERTYbg- Стандартная болгарская раскладкаbr- Бразильская раскладка QWERTYch- Швейцарская раскладка QWERTZde- Немецкая раскладка QWERTZdk- Датская раскладка QWERTYes- Испанская раскладка QWERTYfr- Французская раскладка AZERTYuk- Британская раскладка QWERTYgr- Греческая раскладка QWERTYit- Итальянская раскладка QWERTYno- Норвежская раскладка QWERTYpt- Португальская раскладка QWERTYru- Русская раскладка JCUKENse- Шведская раскладка QWERTYua- Украинская раскладка JCUKENus- Американская раскладка QWERTY
- Это демо демонстрирует функциональность нечёткого поиска:
- Пост в блоге о Нечётком поиске и автодополнении - https://manticoresearch.com/blog/new-fuzzy-search-and-autocomplete/
Обе команды доступны через SQL и поддерживают запросы к локальным (plain и real-time) и распределённым таблицам. Синтаксис следующий:
CALL QSUGGEST(<word or words>, <table name> [,options])
CALL SUGGEST(<word or words>, <table name> [,options])
options: N as option_name[, M as another_option, ...]Эти команды предоставляют все предложения из словаря для заданного слова. Они работают только с таблицами, у которых включено инфиксирование и используется dict=keywords. Они возвращают предлагаемые ключевые слова, расстояние Левенштейна между предложенным и исходным ключевым словом, а также статистику документов по предложенному ключевому слову.
Если первый параметр содержит несколько слов, то:
CALL QSUGGESTвернёт предложения только для последнего слова, игнорируя остальные.CALL SUGGESTвернёт предложения только для первого слова.
Это единственное различие между ними. Поддерживается несколько опций для настройки:
| Опция | Описание | По умолчанию |
|---|---|---|
| limit | Возвращает N лучших совпадений | 5 |
| max_edits | Оставляет только слова из словаря с расстоянием Левенштейна меньше или равным N | 4 |
| result_stats | Предоставляет расстояние Левенштейна и количество документов для найденных слов | 1 (включено) |
| delta_len | Оставляет только слова из словаря с разницей в длине меньше N | 3 |
| max_matches | Количество совпадений для сохранения | 25 |
| reject | Отклонённые слова — это совпадения, которые не лучше уже находящихся в очереди совпадений. Они помещаются в очередь отклонённых, которая сбрасывается, если слово всё же может попасть в очередь совпадений. Этот параметр определяет размер очереди отклонённых (как reject*max(max_matched,limit)). Если очередь отклонённых заполнена, движок прекращает поиск потенциальных совпадений | 4 |
| result_line | альтернативный режим отображения данных, возвращающий все предложения, расстояния и количество документов каждое в отдельной строке | 0 |
| non_char | не пропускать слова из словаря с неалфавитными символами | 0 (пропускать такие слова) |
| sentence | Возвращает исходное предложение с заменой последнего слова на подобранное. | 0 (не возвращать полное предложение) |
| force_bigrams | Принудительно использовать биграммы (n-граммы из 2 символов) вместо триграмм для всех длин слов, что может улучшить сопоставление для слов с ошибками транспозиции | 0 (использовать триграммы для слов ≥6 символов) |
| search_mode | Уточняет предложения, выполняя поиск по индексу. Принимает 'phrase' для точного соответствия фразы или 'words' для соответствия по модели "мешок слов". При включении добавляет столбец found_docs, показывающий количество документов, и пересортировывает результаты по убыванию found_docs, затем по возрастанию distance. |
N/A (отключено по умолчанию) |
Чтобы показать, как это работает, создадим таблицу и добавим в неё несколько документов.
create table products(title text) min_infix_len='2';
insert into products values (0,'Crossbody Bag with Tassel'), (0,'microfiber sheet set'), (0,'Pet Hair Remover Glove');Как видно, слово с опечаткой "crossbUdy" исправляется на "crossbody". По умолчанию CALL SUGGEST/QSUGGEST возвращают:
distance— расстояние Левенштейна, означающее, сколько правок потребовалось, чтобы преобразовать заданное слово в предложенноеdocs— количество документов, содержащих предложенное слово
Чтобы отключить отображение этой статистики, можно использовать опцию 0 as result_stats.
- Example
call suggest('crossbudy', 'products');+-----------+----------+------+
| suggest | distance | docs |
+-----------+----------+------+
| crossbody | 1 | 1 |
+-----------+----------+------+Если первый параметр — не одно слово, а несколько, то CALL SUGGEST вернёт предложения только для первого слова.
- Example
call suggest('bagg with tasel', 'products');+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| bag | 1 | 1 |
+---------+----------+------+Если первый параметр — не одно слово, а несколько, то CALL SUGGEST вернёт предложения только для последнего слова.
- Example
CALL QSUGGEST('bagg with tasel', 'products');+---------+----------+------+
| suggest | distance | docs |
+---------+----------+------+
| tassel | 1 | 1 |
+---------+----------+------+Добавление 1 as sentence заставляет CALL QSUGGEST возвращать всё предложение с исправленным последним словом.
- Example
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence);+-------------------+----------+------+
| suggest | distance | docs |
+-------------------+----------+------+
| bag with tassel | 1 | 1 |
+-------------------+----------+------+Опция 1 as result_line меняет способ отображения предложений в выводе. Вместо показа каждого предложения в отдельной строке, она отображает все предложения, расстояния и количество документов в одной строке. Вот пример, демонстрирующий это:
CALL QSUGGEST('bagg with tasel', 'products', 1 as result_line);+----------+--------+
| name | value |
+----------+--------+
| suggests | tassel |
| distance | 1 |
| docs | 1 |
+----------+--------+Опция force_bigrams может помочь со словами, содержащими ошибки транспозиции, например, "ipohne" и "iphone". Используя биграммы вместо триграмм, алгоритм может лучше обрабатывать перестановки символов.
CALL SUGGEST('ipohne', 'products', 1 as force_bigrams);+--------+----------+------+
| suggest| distance | docs |
+--------+----------+------+
| iphone | 2 | 1 |
+--------+----------+------+Опция search_mode улучшает предложения, выполняя фактические поисковые запросы по индексу для подсчёта количества документов, содержащих каждую предложенную фразу или комбинацию слов. Это помогает ранжировать предложения на основе реальной релевантности документов, а не только статистики словаря.
Опция принимает два значения:
'phrase'- Выполняет поиск точных фраз. Например, при предложении "bag with tassel" выполняется поиск точной фразы"bag with tassel"и подсчитываются документы, содержащие эти слова как смежную фразу.'words'- Выполняет поиск по модели "мешок слов". Например, при предложении "bag with tassel" выполняется поискbag with tassel(без кавычек) и подсчитываются документы, содержащие все эти слова, независимо от порядка или наличия других слов между ними.
ПРИМЕЧАНИЕ: Опция
search_modeработает только тогда, когда включен режимsentence(т.е. когда ввод содержит несколько слов). Для запросов из одного словаsearch_modeигнорируется.
ПРИМЕЧАНИЕ: Соображения производительности: Каждый кандидат на предложение запускает отдельный поисковый запрос к индексу. Если вам нужно оценить много кандидатов, рассмотрите использование меньшего значения
limit, чтобы сократить количество выполняемых поисков.
Когда search_mode включен, результаты включают столбец found_docs, показывающий количество документов для каждого предложения, и результаты пересортировываются по убыванию found_docs, а затем по возрастанию distance.
CALL QSUGGEST('bag with tasel', 'products', 1 as sentence, 'phrase' as search_mode);+-------------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+-------------------+----------+------+-------------+
| bag with tassel | 1 | 13 | 10 |
| bag with tazer | 2 | 27 | 3 |
+-------------------+----------+------+-------------+-- With phrase matching: finds exact phrases only
CALL QSUGGEST('test carp', 'products', 1 as sentence, 'phrase' as search_mode);
-- With words matching: finds documents with all words regardless of order
CALL QSUGGEST('test carp', 'products', 1 as sentence, 'words' as search_mode);-- Phrase mode results:
+----------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+----------------+----------+------+-------------+
| test car | 1 | 17 | 5 |
| test carpet | 2 | 19 | 4 |
+----------------+----------+------+-------------+
-- Words mode results (more matches for "test carpet" due to word separation):
+----------------+----------+------+-------------+
| suggest | distance | docs | found_docs |
+----------------+----------+------+-------------+
| test carpet | 2 | 19 | 19 |
| test car | 1 | 17 | 5 |
+----------------+----------+------+-------------+Понимание разницы:
- Фразовое соответствие (
'phrase'): Ищет точные последовательности. Запрос"test carpet"соответствует только документам, где эти слова встречаются вместе в точном порядке (например, "test carpet cleaning" соответствует, а "test the carpet" или "carpet test" - нет). - Соответствие по модели "мешок слов" (
'words'): Ищет наличие всех слов в документе, порядок не имеет значения. Запросtest carpetсоответствует любому документу, содержащему оба слова "test" и "carpet" где угодно (например, "test the carpet", "test red carpet", "carpet test" - все соответствуют).
- Этот интерактивный курс показывает, как работает
CALL SUGGESTв небольшом веб-приложении.
Кэш запросов хранит сжатые наборы результатов в памяти и повторно использует их для последующих запросов, когда это возможно. Вы можете настроить его с помощью следующих директив:
- qcache_max_bytes — ограничение на использование RAM для хранения кэшированных запросов. По умолчанию установлено в 16 МБ. Установка
qcache_max_bytesв 0 полностью отключает кэш запросов. - qcache_thresh_msec — минимальное время выполнения запроса в миллисекундах для кеширования. Запросы, которые выполняются быстрее этого времени, не будут кешироваться. По умолчанию 3000 мс, или 3 секунды.
- qcache_ttl_sec — время жизни кэшированной записи, или TTL. Запросы будут оставаться в кэше в течение этого времени. По умолчанию 60 секунд, или 1 минута.
Эти настройки можно изменить на лету, используя оператор SET GLOBAL:
mysql> SET GLOBAL qcache_max_bytes=128000000;Эти изменения применяются немедленно, и кэшированные наборы результатов, которые больше не соответствуют ограничениям, сразу же отбрасываются. При уменьшении размера кэша на лету выигрыш получают наиболее недавно использованные (MRU) наборы результатов.
Кэш запросов работает следующим образом. При включении каждый результат полнотекстового поиска полностью сохраняется в памяти. Это происходит после полнотекстового совпадения, фильтрации и ранжирования, так что по сути мы сохраняем пары {docid,weight} для total_found. Сжатые совпадения могут занимать в среднем от 2 до 12 байт на совпадение, в основном в зависимости от дельт между последовательными docid. По завершении запроса мы проверяем пороги времени и размера, и либо сохраняем сжатый набор результатов для повторного использования, либо отбрасываем его.
Обратите внимание, что влияние кэша запросов на RAM не ограничивается qcache_max_bytes! Например, если у вас выполняется 10 одновременных запросов, каждый из которых находит до 1 млн совпадений (после фильтров), то пиковое временное использование RAM окажется в диапазоне от 40 МБ до 240 МБ, даже если запросы достаточно быстрые и не кэшируются.
Запросы могут использовать кэш, когда совпадают таблица, полнотекстовый запрос (то есть содержимое MATCH()), ранжировщик и совместимы фильтры. Это значит:
- Полнотекстовая часть внутри
MATCH()должна совпадать посимвольно. Добавьте один пробел — и это уже другой запрос, с точки зрения кэша запросов. - Ранжировщик (и его параметры, если есть, для пользовательских ранжировщиков) должен совпадать посимвольно.
- Фильтры должны быть надмножеством оригинальных фильтров. Вы можете добавить дополнительные фильтры и все равно попасть в кэш. (В этом случае дополнительные фильтры будут применены к кэшированному результату.) Но если вы уберёте какой-то фильтр, это уже будет новый запрос.
Записи кэша истекают по TTL и также инвалидируются при ротации таблиц, или при выполнении TRUNCATE, или ATTACH. Обратите внимание, что в настоящее время записи не инвалидируются при произвольных записях в RT-таблицу! Поэтому кэшированный запрос может возвращать старые результаты в течение времени жизни TTL.
Вы можете проверить текущий статус кэша с помощью SHOW STATUS через переменные qcache_XXX:
mysql> SHOW STATUS LIKE 'qcache%';
+-----------------------+----------+
| Counter | Value |
+-----------------------+----------+
| qcache_max_bytes | 16777216 |
| qcache_thresh_msec | 3000 |
| qcache_ttl_sec | 60 |
| qcache_cached_queries | 0 |
| qcache_used_bytes | 0 |
| qcache_hits | 0 |
+-----------------------+----------+
6 rows in set (0.00 sec)Сортировки в первую очередь влияют на сравнения строковых атрибутов. Они определяют как кодировку набора символов, так и стратегию, которую Manticore использует для сравнения строк при выполнении ORDER BY или GROUP BY с участием строкового атрибута.
Строковые атрибуты хранятся в неизменном виде во время индексирования, и к ним не прикрепляется информация о наборе символов или языке. Это приемлемо, пока Manticore нужно лишь хранить и возвращать строки вызывающему приложению дословно. Однако, когда вы просите Manticore отсортировать по строковому значению, запрос сразу же становится неоднозначным.
Во-первых, строки с одним байтом (ASCII, ISO-8859-1 или Windows-1251) требуют иной обработки, чем строки UTF-8, которые могут кодировать каждый символ переменным числом байт. Поэтому нам нужно знать тип набора символов, чтобы правильно интерпретировать сырые байты как осмысленные символы.
Во-вторых, нам также необходимо знать правила сортировки, специфичные для языка. Например, при сортировке по правилам США в локали en_US, акцентированный символ ï (малая буква i с диарезой) должен размещаться где-то после z. Однако при сортировке с учётом французских правил и локали fr_FR, его следует поместить между i и j. Другой набор правил может вовсе игнорировать акценты, позволяя ï и i смешиваться произвольно.
В-третьих, в некоторых случаях требуется чувствительная к регистру сортировка, а в других — регистронезависимая.
Сортировки инкапсулируют всё перечисленное: набор символов, языковые правила и чувствительность к регистру. В настоящее время Manticore предоставляет четыре сортировки:
libc_cilibc_csutf8_general_cibinary
Первые две сортировки опираются на несколько стандартных вызовов библиотеки C (libc) и, таким образом, могут поддерживать любую локаль, установленную в вашей системе. Они обеспечивают регистронезависимые (_ci) и регистрозависимые (_cs) сравнения соответственно. По умолчанию используется локаль C, что фактически сводит сортировку к побайтовому сравнению. Чтобы изменить это, необходимо указать другую доступную локаль с помощью директивы collation_libc_locale. Список локалей, доступных в вашей системе, обычно можно получить с помощью команды locale:
$ locale -a
C
en_AG
en_AU.utf8
en_BW.utf8
en_CA.utf8
en_DK.utf8
en_GB.utf8
en_HK.utf8
en_IE.utf8
en_IN
en_NG
en_NZ.utf8
en_PH.utf8
en_SG.utf8
en_US.utf8
en_ZA.utf8
en_ZW.utf8
es_ES
fr_FR
POSIX
ru_RU.utf8
ru_UA.utf8Конкретный список системных локалей может варьироваться. Обратитесь к документации вашей ОС для установки дополнительных нужных локалей.
Локали utf8_general_ci и binary встроены в Manticore. Первая — это универсальная сортировка для UTF-8 данных (без так называемой языковой адаптации); она должна вести себя аналогично сортировке utf8_general_ci в MySQL. Вторая — простое побайтовое сравнение.
Сортировка может быть переопределена через SQL на уровне сессии с помощью оператора SET collation_connection. Все последующие SQL-запросы будут использовать эту сортировку. В противном случае все запросы будут использовать сортировку, установленную по умолчанию на сервере, или указанную в конфигурационной директиве collation_server. В настоящее время по умолчанию в Manticore используется сортировка libc_ci.
Сортировки влияют на все сравнения строковых атрибутов, включая сортировки в ORDER BY и GROUP BY, поэтому можно получить результаты, отсортированные или сгруппированные по-разному в зависимости от выбранной сортировки. Обратите внимание, что сортировки не влияют на полнотекстовый поиск; для этого используйте charset_table.