Manticore Search is a database designed specifically for search, including full-text search.
Manticore was born in 2017 as a continuation of Sphinx Search. We took the best from Sphinx (C++ core and focus on low level data structures and fine-tuned algorithms), added a lot of new functionality, fixed hundreds of bugs, made it easier to use, kept it open source and made Manticore Search even more lightweight & extremely fast database for search.
- Over 20 full-text operators and over 20 ranking factors
- Custom ranking
- Stemming
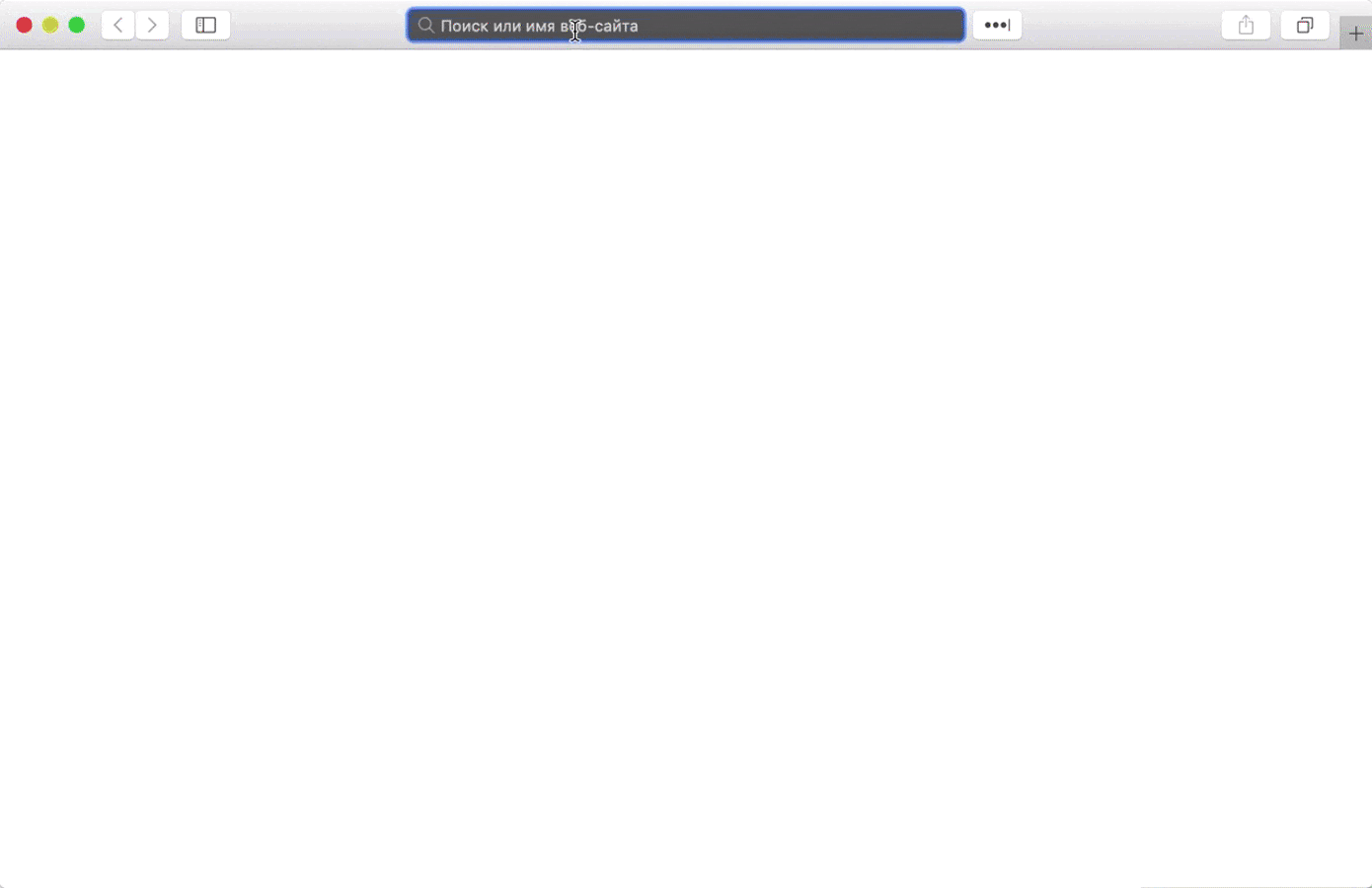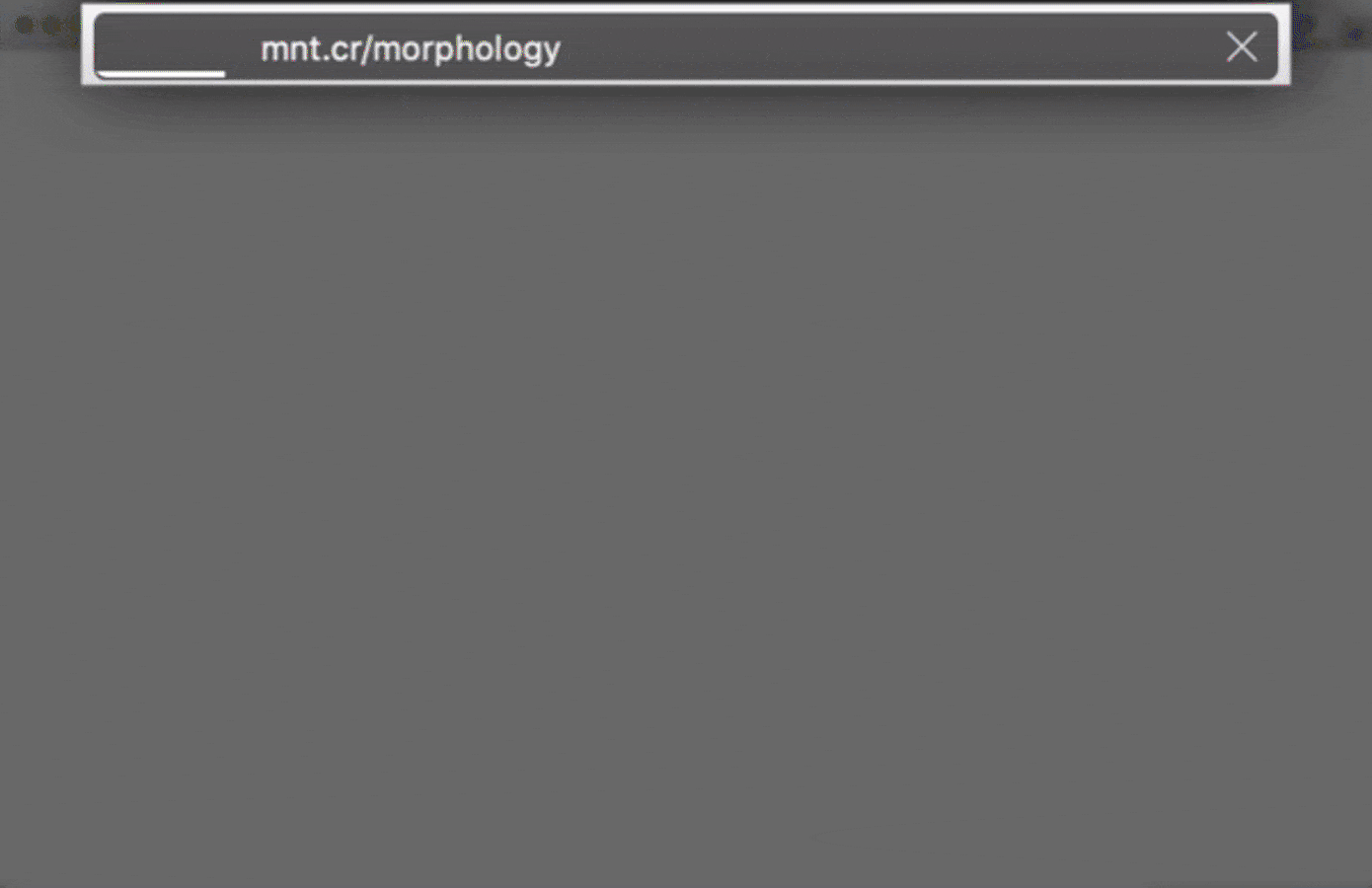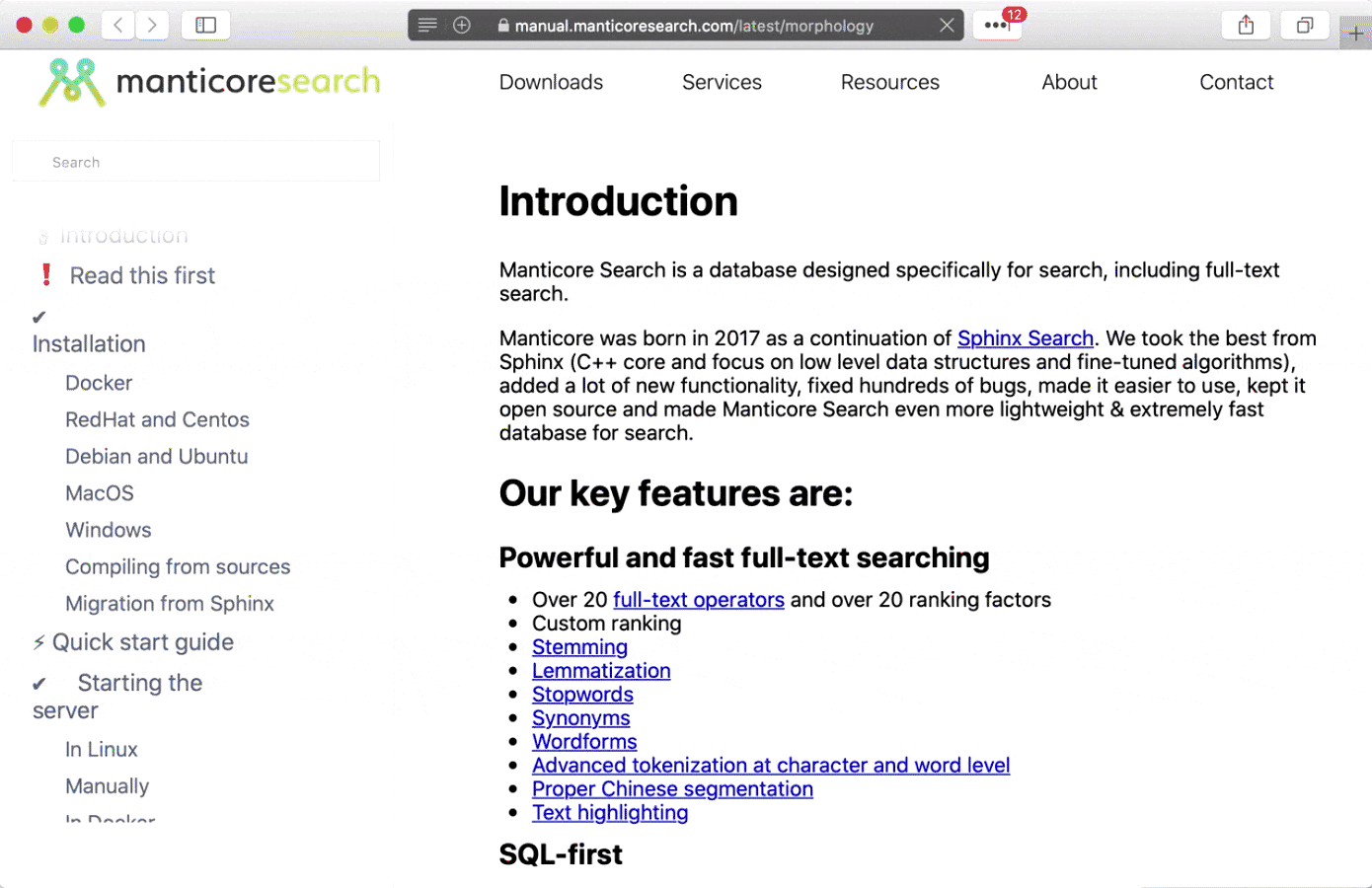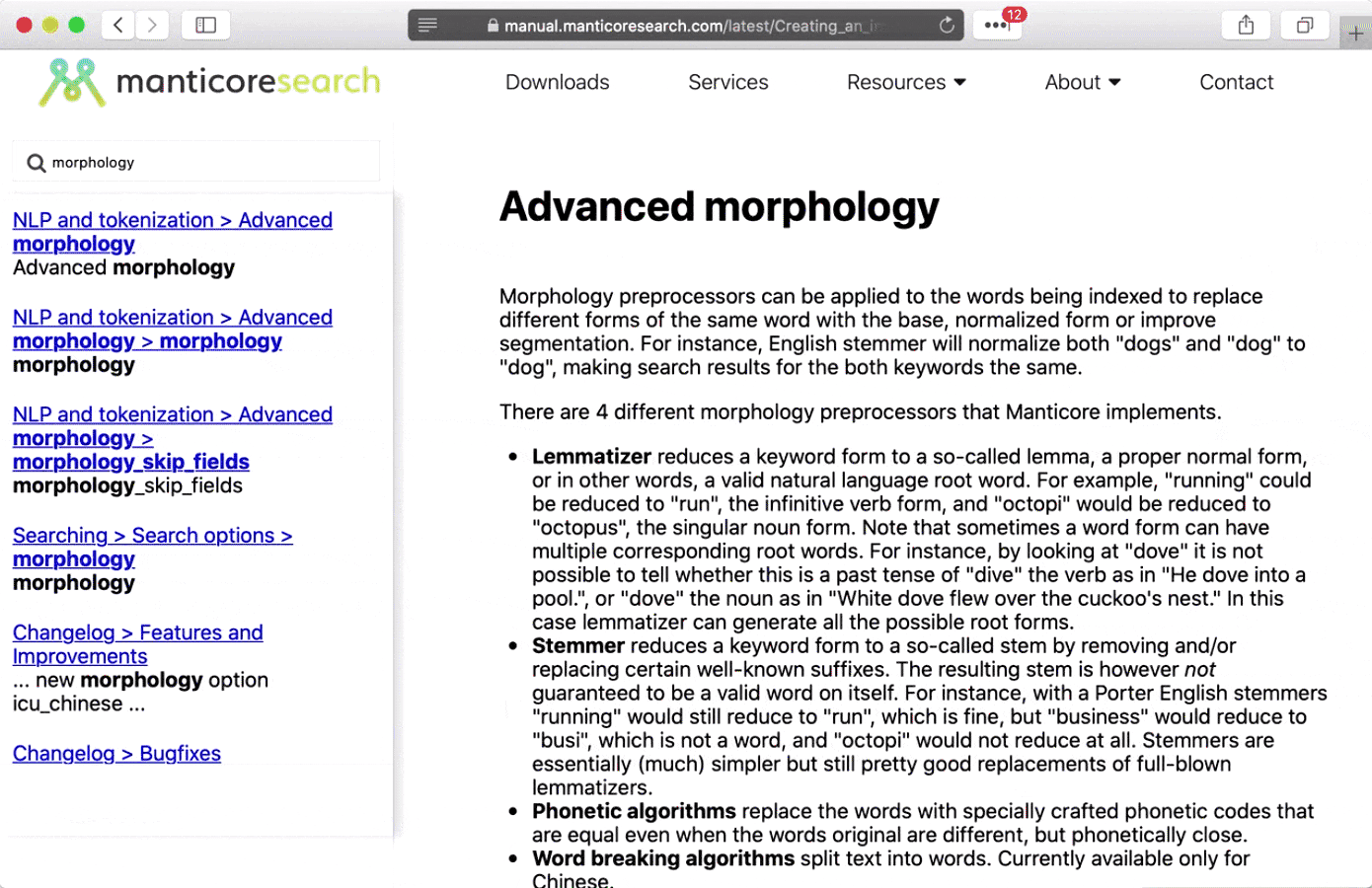
- Lemmatization
- Stopwords
- Synonyms
- Wordforms
- Advanced tokenization at character and word level
- Proper Chinese segmentation
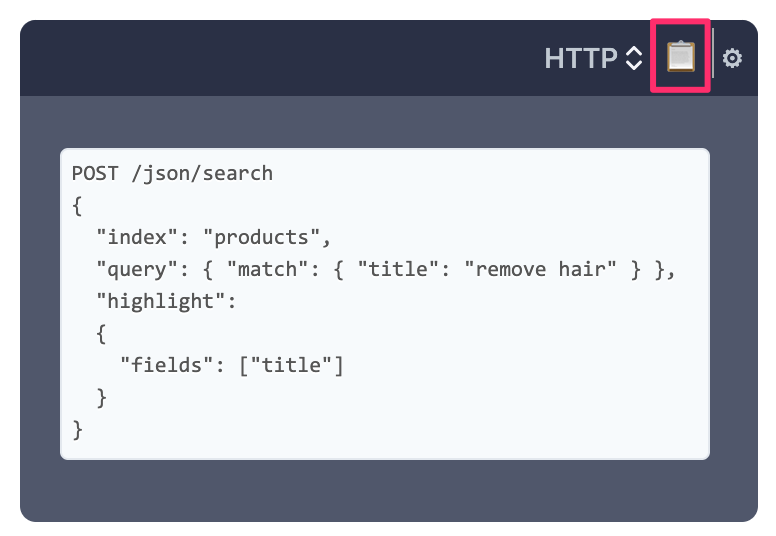
- Text highlighting
The native Manticore's syntax is SQL. It speaks SQL over HTTP and MySQL protocol. You can use your preferred mysql client to connect to Manticore Search server via SQL protocol in any programming language.
To provide more programmatic way to manage your data and schemas Manticore provides HTTP JSON protocol. It is very similar to the one from Elasticsearch.
You can create / update / delete indexes online as well as providing schemas in a configuration file.
Being written fully in C++ Manticore Search starts fast and doesn't take much RAM. Low-level optimizations give good performance.
After a new document is added or updated it can be read immediately.
We provide interactive courses for easier learning.
Manticore is not fully ACID-compliant, but it supports isolated transactions for atomic changes and binary logging for safe writes.
Data can be distributed across servers and data-centers. Any Manticore Search node can be both a load balancer and a data node. Manticore implements synchronous multi-master replication using Galera library which guarantees consistency between all data nodes and no data loss.
Manticore indexer tool and rich configuration syntax helps to sync existing data from MySQL, PostgreSQL, any database which speaks ODBC and any other technology which can generate a simple XML or CSV.
You can integrate Manticore Search with MySQL/MariaDB server via a FEDERATED engine or use Manticore through ProxySQL
Manticore has a special index type called "percolate" which implements search in reverse when you index your queries rather than data. It's an extremely powerful tool for full-text data stream filtering: just put all your queries in the index, process your data stream by sending each batch of documents to Manticore Search and you'll get only those back that match some of your stored queries.
Manticore's possible applications are not limited by, but include:
- Full-text search
- when used with small data volume you can benefit from powerful full-text search syntax and low RAM consumption (as little as 7-8 megabytes)
- when used with big data you can benefit from Manticore's high availability capabilities and ability to serve very large indexes, each taking hundreds of gigabytes of RAM
- Faceted search
- Geo-spatial search
- Spell correction
- Autocomplete
- Data stream filtering