Example of a complex query:
"hello world" @title "example program"~5 @body python -(php|perl) @* codeThe full meaning of this search is:
- Find the words 'hello' and 'world' adjacently in any field in a document;
- Additionally, the same document must also contain the words 'example' and 'program' in the title field, with up to, but not including, 5 words between the words in question; (E.g. "example PHP program" would be matched however "example script to introduce outside data into the correct context for your program" would not because two terms have 5 or more words between them)
- Additionally, the same document must contain the word 'python' in the body field, but not contain either 'php' or 'perl';
- Additionally, the same document must contain the word 'code' in any field.
OR operator precedence is higher than AND, so "looking for cat | dog | mouse" means "looking for ( cat | dog | mouse )" and not "(looking for cat) | dog | mouse".
To understand how a query will be executed, Manticore Search offer query profile tooling for viewing the query tree created by a query expression.
When using SQL statement the full-text query profiling needs to be enabled before running the desired query:
SET profiling =1;
SELECT * FROM test WHERE MATCH('@title abc* @body hey');To view the query tree, we must run SHOW PLAN right after the execution of the query:
SHOW PLAN;The command will return the structure of the executed query. Please note that the 3 statements - SET profiling, the query and SHOW - must run on the same session.
When using the HTTP JSON protocol we can just enable "profile":true to get in response the full-text query tree structure.
{
"index":"test",
"profile":true,
"query":
{
"match_phrase": { "_all" : "had grown quite" }
}
}The response will contain a profile object in which we can find a member query.
query property contains the transformed full-text query tree. Each node contains:
type: node type. Can be AND, OR, PHRASE, KEYWORD etc.description: query subtree for this node shown as a string (inSHOW PLANformat)children: child nodes, if anymax_field_pos: maximum position within a field
A keyword node will also provide:
word: transformed keyword.querypos: position of this keyword in a query.excluded: keyword excluded from query.expanded: keyword added by prefix expansion.field_start: keyword must occur at the very start of the field.field_end: keyword must occur at the very end of the field.boost: keyword IDF will be multiplied by this.
- SQL
- JSON
- PHP
- Python
- javascript
- Java
SET profiling=1;
SELECT * FROM test WHERE MATCH('@title abc* @body hey');
SHOW PLAN \GPOST /search
{
"index": "forum",
"query": {"query_string": "i me"},
"_source": { "excludes":["*"] },
"limit": 1,
"profile":true
}$result = $index->search('i me')->setSource(['excludes'=>['*']])->setLimit(1)->profile()->get();
print_r($result->getProfile());searchApi.search({"index":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":True})res = await searchApi.search({"index":"forum","query":{"query_string":"i me"},"_source":{"excludes":["*"]},"limit":1,"profile":true});query = new HashMap<String,Object>();
query.put("query_string","i me");
searchRequest = new SearchRequest();
searchRequest.setIndex("forum");
searchRequest.setQuery(query);
searchRequest.setProfile(true);
searchRequest.setLimit(1);
searchRequest.setSort(new ArrayList<String>(){{
add("*");
}});
searchResponse = searchApi.search(searchRequest);*************************** 1\. row ***************************
Variable: transformed_tree
Value: AND(
OR(fields=(title), KEYWORD(abcx, querypos=1, expanded), KEYWORD(abcm, querypos=1, expanded)),
AND(fields=(body), KEYWORD(hey, querypos=2)))
1 row in set (0.00 sec){
"took":1503,
"timed_out":false,
"hits":
{
"total":406301,
"hits":
[
{
"_id":"406443",
"_score":3493,
"_source":{}
}
]
},
"profile":
{
"query":
{
"type":"AND",
"description":"AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"children":
[
{
"type":"AND",
"description":"AND(KEYWORD(i, querypos=1))",
"children":
[
{
"type":"KEYWORD",
"word":"i",
"querypos":1
}
]
},
{
"type":"AND",
"description":"AND(KEYWORD(me, querypos=2))",
"children":
[
{
"type":"KEYWORD",
"word":"me",
"querypos":2
}
]
}
]
}
}
}Array
(
[query] => Array
(
[type] => AND
[description] => AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(KEYWORD(i, querypos=1))
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => i
[querypos] => 1
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(KEYWORD(me, querypos=2))
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => me
[querypos] => 2
)
)
)
)
)
){'hits': {'hits': [{u'_id': u'100', u'_score': 2500, u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'i'}],
u'description': u'AND(KEYWORD(i, querypos=1))',
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'me'}],
u'description': u'AND(KEYWORD(me, querypos=2))',
u'type': u'AND'}],
u'description': u'AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}{"hits": {"hits": [{"_id": "100", "_score": 2500, "_source": {}}],
"total": 1},
"profile": {"query": {"children": [{"children": [{"querypos": 1,
"type": "KEYWORD",
"word": "i"}],
"description": "AND(KEYWORD(i, querypos=1))",
"type": "AND"},
{"children": [{"querypos": 2,
"type": "KEYWORD",
"word": "me"}],
"description": "AND(KEYWORD(me, querypos=2))",
"type": "AND"}],
"description": "AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2)))",
"type": "AND"}},
"timed_out": False,
"took": 0}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=100, _score=2500, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(KEYWORD(i, querypos=1)), AND(KEYWORD(me, querypos=2))), children=[{type=AND, description=AND(KEYWORD(i, querypos=1)), children=[{type=KEYWORD, word=i, querypos=1}]}, {type=AND, description=AND(KEYWORD(me, querypos=2)), children=[{type=KEYWORD, word=me, querypos=2}]}]}}
}In some cases the evaluated query tree can be rather different from the original one because of expansions and other transformations.
- SQL
- JSON
- PHP
- Python
- javascript
- Java
SET profiling=1;
SELECT id FROM forum WHERE MATCH('@title way* @content hey') LIMIT 1;
SHOW PLAN;POST /search
{
"index": "forum",
"query": {"query_string": "@title way* @content hey"},
"_source": { "excludes":["*"] },
"limit": 1,
"profile":true
}$result = $index->search('@title way* @content hey')->setSource(['excludes'=>['*']])->setLimit(1)->profile()->get();
print_r($result->getProfile());searchApi.search({"index":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true})res = await searchApi.search({"index":"forum","query":{"query_string":"@title way* @content hey"},"_source":{"excludes":["*"]},"limit":1,"profile":true});query = new HashMap<String,Object>();
query.put("query_string","@title way* @content hey");
searchRequest = new SearchRequest();
searchRequest.setIndex("forum");
searchRequest.setQuery(query);
searchRequest.setProfile(true);
searchRequest.setLimit(1);
searchRequest.setSort(new ArrayList<String>(){{
add("*");
}});
searchResponse = searchApi.search(searchRequest);Query OK, 0 rows affected (0.00 sec)
+--------+
| id |
+--------+
| 711651 |
+--------+
1 row in set (0.04 sec)
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Variable | Value |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| transformed_tree | AND(
OR(
OR(
AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)),
OR(
AND(fields=(title), KEYWORD(ways, querypos=1, expanded)),
AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))),
AND(fields=(title), KEYWORD(way, querypos=1, expanded)),
OR(fields=(title), KEYWORD(way*, querypos=1, expanded))),
AND(fields=(content), KEYWORD(hey, querypos=2))) |
+------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec){
"took":33,
"timed_out":false,
"hits":
{
"total":105,
"hits":
[
{
"_id":"711651",
"_score":2539,
"_source":{}
}
]
},
"profile":
{
"query":
{
"type":"AND",
"description":"AND( OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded))), AND(fields=(content), KEYWORD(hey, querypos=2)))",
"children":
[
{
"type":"OR",
"description":"OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded)))",
"children":
[
{
"type":"OR",
"description":"OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))))",
"children":
[
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(wayne, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"wayne",
"querypos":1,
"expanded":true
}
]
},
{
"type":"OR",
"description":"OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))",
"children":
[
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(ways, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"ways",
"querypos":1,
"expanded":true
}
]
},
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"wayyy",
"querypos":1,
"expanded":true
}
]
}
]
}
]
},
{
"type":"AND",
"description":"AND(fields=(title), KEYWORD(way, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"way",
"querypos":1,
"expanded":true
}
]
},
{
"type":"OR",
"description":"OR(fields=(title), KEYWORD(way*, querypos=1, expanded))",
"fields":["title"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"way*",
"querypos":1,
"expanded":true
}
]
}
]
},
{
"type":"AND",
"description":"AND(fields=(content), KEYWORD(hey, querypos=2))",
"fields":["content"],
"max_field_pos":0,
"children":
[
{
"type":"KEYWORD",
"word":"hey",
"querypos":2
}
]
}
]
}
}
}Array
(
[query] => Array
(
[type] => AND
[description] => AND( OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded))), AND(fields=(content), KEYWORD(hey, querypos=2)))
[children] => Array
(
[0] => Array
(
[type] => OR
[description] => OR( OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))), AND(fields=(title), KEYWORD(way, querypos=1, expanded)), OR(fields=(title), KEYWORD(way*, querypos=1, expanded)))
[children] => Array
(
[0] => Array
(
[type] => OR
[description] => OR( AND(fields=(title), KEYWORD(wayne, querypos=1, expanded)), OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(wayne, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => wayne
[querypos] => 1
[expanded] => 1
)
)
)
[1] => Array
(
[type] => OR
[description] => OR( AND(fields=(title), KEYWORD(ways, querypos=1, expanded)), AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded)))
[children] => Array
(
[0] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(ways, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => ways
[querypos] => 1
[expanded] => 1
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(wayyy, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => wayyy
[querypos] => 1
[expanded] => 1
)
)
)
)
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(title), KEYWORD(way, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => way
[querypos] => 1
[expanded] => 1
)
)
)
[2] => Array
(
[type] => OR
[description] => OR(fields=(title), KEYWORD(way*, querypos=1, expanded))
[fields] => Array
(
[0] => title
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => way*
[querypos] => 1
[expanded] => 1
)
)
)
)
)
[1] => Array
(
[type] => AND
[description] => AND(fields=(content), KEYWORD(hey, querypos=2))
[fields] => Array
(
[0] => content
)
[max_field_pos] => 0
[children] => Array
(
[0] => Array
(
[type] => KEYWORD
[word] => hey
[querypos] => 2
)
)
)
)
)
){'hits': {'hits': [{u'_id': u'2811025403043381551',
u'_score': 2643,
u'_source': {}}],
'total': 1},
'profile': {u'query': {u'children': [{u'children': [{u'expanded': True,
u'querypos': 1,
u'type': u'KEYWORD',
u'word': u'way*'}],
u'description': u'AND(fields=(title), KEYWORD(way*, querypos=1, expanded))',
u'fields': [u'title'],
u'type': u'AND'},
{u'children': [{u'querypos': 2,
u'type': u'KEYWORD',
u'word': u'hey'}],
u'description': u'AND(fields=(content), KEYWORD(hey, querypos=2))',
u'fields': [u'content'],
u'type': u'AND'}],
u'description': u'AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))',
u'type': u'AND'}},
'timed_out': False,
'took': 0}{"hits": {"hits": [{"_id": "2811025403043381551",
"_score": 2643,
"_source": {}}],
"total": 1},
"profile": {"query": {"children": [{"children": [{"expanded": True,
"querypos": 1,
"type": "KEYWORD",
"word": "way*"}],
"description": "AND(fields=(title), KEYWORD(way*, querypos=1, expanded))",
"fields": ["title"],
"type": "AND"},
{"children": [{"querypos": 2,
"type": "KEYWORD",
"word": "hey"}],
"description": "AND(fields=(content), KEYWORD(hey, querypos=2))",
"fields": ["content"],
"type": "AND"}],
"description": "AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2)))",
"type": "AND"}},
"timed_out": False,
"took": 0}class SearchResponse {
took: 18
timedOut: false
hits: class SearchResponseHits {
total: 1
hits: [{_id=2811025403043381551, _score=2643, _source={}}]
aggregations: null
}
profile: {query={type=AND, description=AND( AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), AND(fields=(content), KEYWORD(hey, querypos=2))), children=[{type=AND, description=AND(fields=(title), KEYWORD(way*, querypos=1, expanded)), fields=[title], children=[{type=KEYWORD, word=way*, querypos=1, expanded=true}]}, {type=AND, description=AND(fields=(content), KEYWORD(hey, querypos=2)), fields=[content], children=[{type=KEYWORD, word=hey, querypos=2}]}]}}
}The SQL statement EXPLAIN QUERY allows displaying the execution tree of a provided full-text query without running an actual search query on the table.
- SQL
EXPLAIN QUERY index_base '@title running @body dog'\G EXPLAIN QUERY index_base '@title running @body dog'\G
*************************** 1\. row ***************************
Variable: transformed_tree
Value: AND(
OR(
AND(fields=(title), KEYWORD(run, querypos=1, morphed)),
AND(fields=(title), KEYWORD(running, querypos=1, morphed))))
AND(fields=(body), KEYWORD(dog, querypos=2, morphed)))EXPLAIN QUERY ... option format=dot allows displaying the execution tree of a provided full-text query in hierarchical format suitable for visualization by existing tools, for example https://dreampuf.github.io/GraphvizOnline :
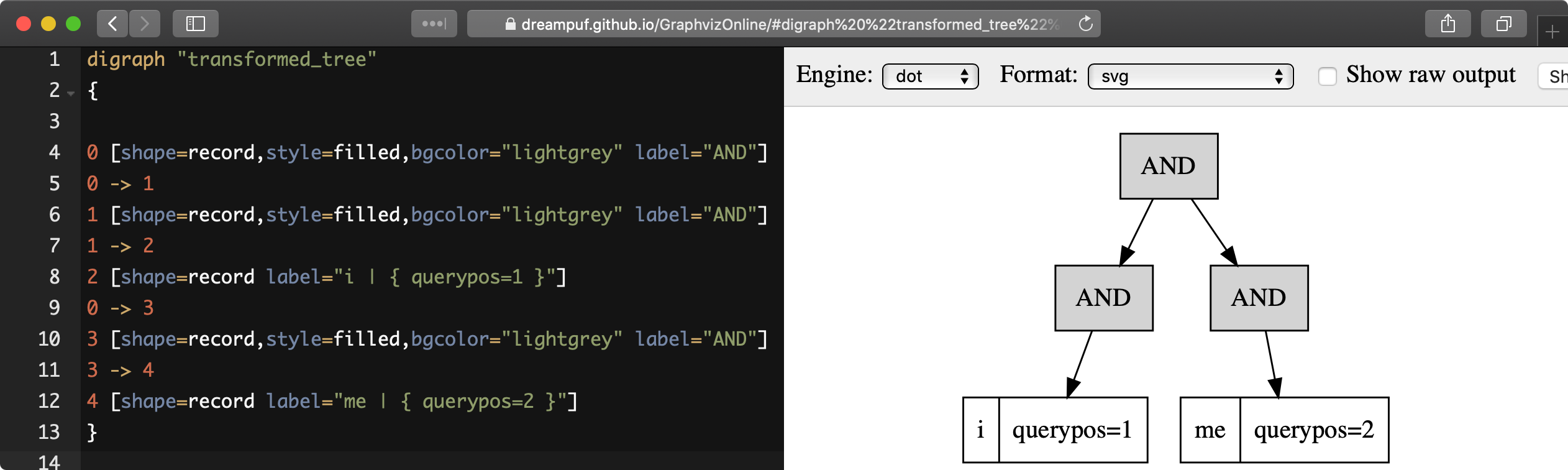
- SQL
EXPLAIN QUERY tbl 'i me' option format=dot\GEXPLAIN QUERY tbl 'i me' option format=dot\G
*************************** 1. row ***************************
Variable: transformed_tree
Value: digraph "transformed_tree"
{
0 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
0 -> 1
1 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
1 -> 2
2 [shape=record label="i | { querypos=1 }"]
0 -> 3
3 [shape=record,style=filled,bgcolor="lightgrey" label="AND"]
3 -> 4
4 [shape=record label="me | { querypos=2 }"]
}When expression ranker is used, it is possible to expose the values of the calculated factors using PACKEDFACTORS().
The function returns:
- the values of document level factors (like bm25, field_mask, doc_word_count)
- list with each field that returned a hit (like lcs, hit_count, word_count, sum_idf, min_hit_pos etc.)
- list with each keyword from the query and their tf and idf values
The values can be used to understand why certain documents get scored lower or higher in a search or to improve the existing ranking expression.
- SQL
SELECT id, PACKEDFACTORS() FROM test1 WHERE MATCH('test one') OPTION ranker=expr('1')\G id: 1
packedfactors(): bm25=569, bm25a=0.617197, field_mask=2, doc_word_count=2,
field1=(lcs=1, hit_count=2, word_count=2, tf_idf=0.152356,
min_idf=-0.062982, max_idf=0.215338, sum_idf=0.152356, min_hit_pos=4,
min_best_span_pos=4, exact_hit=0, max_window_hits=1, min_gaps=2,
exact_order=1, lccs=1, wlccs=0.215338, atc=-0.003974),
word0=(tf=1, idf=-0.062982),
word1=(tf=1, idf=0.215338)
1 row in set (0.00 sec)Queries may be automatically optimized if OPTION boolean_simplify=1 is specified. Some transformations performed by this optimization include:
- Excess brackets: ((A | B) | C) becomes ( A | B | C ); ((A B) C) becomes ( A B C )
- Excess AND NOT: ((A !N1) !N2) becomes (A !(N1 | N2))
- Common NOT: ((A !N) | (B !N)) becomes ((A|B) !N)
- Common Compound NOT: ((A !(N AA)) | (B !(N BB))) becomes (((A|B) !N) | (A !AA) | (B !BB)) if the cost of evaluating N is greater than the added together costs of evaluating A and B
- Common subterm: ((A (N | AA)) | (B (N | BB))) becomes (((A|B) N) | (A AA) | (B BB)) if the cost of evaluating N is greater than the added together costs of evaluating A and B
- Common keywords: (A | "A B"~N) becomes A; ("A B" | "A B C") becomes "A B"; ("A B"~N | "A B C"~N) becomes ("A B"~N)
- Common phrase: ("X A B" | "Y A B") becomes ("("X"|"Y") A B")
- Common AND NOT: ((A !X) | (A !Y) | (A !Z)) becomes (A !(X Y Z))
- Common OR NOT: ((A !(N | N1)) | (B !(N | N2))) becomes (( (A !N1) | (B !N2) ) !N)
Note that optimizing the queries consumes CPU time, so for simple queries -or for hand-optimized queries- you'll do better with the default
boolean_simplify=0value. Simplifications are often better for complex queries, or algorithmically generated queries.
Queries like "-dog", which implicitly include all documents from the collection, can not be evaluated. This is both for technical and performance reasons. Technically, Manticore does not always keep a list of all IDs. Performance-wise, when the collection is huge (ie. 10-100M documents), evaluating such queries could take very long.
When you run a query via SQL over mysql protocol as a result you get the requested columns back or empty result set in case nothing is found.
- SQL
SELECT * FROM tbl;+------+------+--------+
| id | age | name |
+------+------+--------+
| 1 | 25 | joe |
| 2 | 25 | mary |
| 3 | 33 | albert |
+------+------+--------+
3 rows in set (0.00 sec)In addition to that you can use SHOW META call to see additional meta-information about the latest query.
- SQL
SELECT id,story_author,comment_author FROM hn_small WHERE story_author='joe' LIMIT 3; SHOW META;++--------+--------------+----------------+
| id | story_author | comment_author |
+--------+--------------+----------------+
| 152841 | joe | SwellJoe |
| 161323 | joe | samb |
| 163735 | joe | jsjenkins168 |
+--------+--------------+----------------+
3 rows in set (0.01 sec)
+----------------+-------+
| Variable_name | Value |
+----------------+-------+
| total | 3 |
| total_found | 20 |
| total_relation | gte |
| time | 0.010 |
+----------------+-------+
4 rows in set (0.00 sec)In some cases, e.g. when you do faceted search you can get multiple result sets as a response to your SQL query.
- SQL
SELECT * FROM tbl WHERE MATCH('joe') FACET age;+------+------+
| id | age |
+------+------+
| 1 | 25 |
+------+------+
1 row in set (0.00 sec)
+------+----------+
| age | count(*) |
+------+----------+
| 25 | 1 |
+------+----------+
1 row in set (0.00 sec)In case of a warning the result set will include a warning flag and you can see the warning using SHOW WARNINGS.
- SQL
SELECT * from tbl where match('"joe"/3'); show warnings;+------+------+------+
| id | age | name |
+------+------+------+
| 1 | 25 | joe |
+------+------+------+
1 row in set, 1 warning (0.00 sec)
+---------+------+--------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+--------------------------------------------------------------------------------------------+
| warning | 1000 | quorum threshold too high (words=1, thresh=3); replacing quorum operator with AND operator |
+---------+------+--------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)If your query fails you will get an error:
- SQL
SELECT * from tbl where match('@surname joe');ERROR 1064 (42000): index idx: query error: no field 'surname' found in schemaVia HTTP JSON iterface query result is sent as a JSON document. Example:
{
"took":10,
"timed_out": false,
"hits":
{
"total": 2,
"hits":
[
{
"_id": "1",
"_score": 1,
"_source": { "gid": 11 }
},
{
"_id": "2",
"_score": 1,
"_source": { "gid": 12 }
}
]
}
}took: time in milliseconds it took to execute the searchtimed_out: if the query timed out or nothits: search results. has the following properties:total: total number of matching documentshits: an array containing matches
Query result can also include query profile information, see Query profile.
Each match in the hits array has the following properties:
_id: match id_score: match weight, calculated by ranker_source: an array containing the attributes of this match
By default all attributes are returned in the _source array. You can use the _source property in the request payload to select the fields you want to be included in the result set. Example:
{
"index":"test",
"_source":"attr*",
"query": { "match_all": {} }
}You can specify the attributes which you want to include in the query result as a string ("_source": "attr*") or as an array of strings ("_source": [ "attr1", "attri*" ]"). Each entry can be an attribute name or a wildcard (*, % and ? symbols are supported).
You can also explicitly specify which attributes you want to include and which to exclude from the result set using the includes and excludes properties:
"_source":
{
"includes": [ "attr1", "attri*" ],
"excludes": [ "*desc*" ]
}An empty list of includes is interpreted as “include all attributes” while an empty list of excludes does not match anything. If an attribute matches both the includes and excludes, then the excludes win.
WHERE is an SQL clause which works for both fulltext matching and additional filtering. The following operators are available:
- Comparison operators
<, > <=, >=, =, <>, BETWEEN, IN, IS NULL - Boolean operators
AND, OR, NOT
MATCH('query') is supported and maps to fulltext query.
{col_name | expr_alias} [NOT] IN @uservar condition syntax is supported. Refer to SET syntax for a description of global user variables.
If you prefer HTTP JSON interface you can also do filtering. It looks more complex that in SQL, but can be recommended for the cases when you need to prepare a query in a programmatic manner, for example as a result of a form in your application filled out by the user.
Here's an example of several filters in a bool query.
This is a fulltext query that matches all the documents containing product in any field. These documents must have a price greater or equal than 500 (gte) and less or equal than 1000 (lte). All of these documents must not have a revision less than 15 (lt).
- JSON
POST /search
{
"index": "test1",
"query": {
"bool": {
"must": [
{ "match" : { "_all" : "product" } },
{ "range": { "price": { "gte": 500, "lte": 1000 } } }
],
"must_not": {
"range": { "revision": { "lt": 15 } }
}
}
}
}bool query matches documents matching boolean combinations of other queries and/or filters. Queries and filters must be specified in must, should or must_not sections and can be nested.
- JSON
POST /search
{
"index":"test1",
"query": {
"bool": {
"must": [
{ "match": {"_all":"keyword"} },
{ "range": { "revision": { "gte": 14 } } }
]
}
}
}Queries and filters specified in the must section must match the documents. If several fulltext queries or filters are specified, all of them. This is the equivalent of AND queries in SQL. Note, if you want to match against an array (multi-value attribute) you can specify the attribute multiple times and if only all the queried values are found in the array the result will be positive, e.g.:
"must": [
{"equals" : { "product_codes": 5 }},
{"equals" : { "product_codes": 6 }}
]Note also, it may be better in terms of performance to use:
{"in" : { "all(product_codes)": [5,6] }}(see details below).
Queries and filters specified in the should section should match the documents. If some queries are specified in must or must_not, should queries are ignored. On the other hand, if there are no queries other than should, then at least one of these queries must match a document for it to match the bool query. This is the equivalent of OR queries. Note, if you want to match against an array (multi-value attribute) you can specify the attribute multiple times, e.g.:
"should": [
{"equals" : { "product_codes": 7 }},
{"equals" : { "product_codes": 8 }}
]Note also, it may be better in terms of performance to use:
{"in" : { "any(product_codes)": [7,8] }}(see details below).
Queries and filters specified in the must_not section must not match the documents. If several queries are specified under must_not, the document matches if none of them match.
- JSON
POST /search
{
"index":"t",
"query": {
"bool": {
"should": [
{
"equals": {
"b": 1
}
},
{
"equals": {
"b": 3
}
}
],
"must": [
{
"equals": {
"a": 1
}
}
],
"must_not": {
"equals": {
"b": 2
}
}
}
}
}A bool query can be nested inside another bool so you can make more complex queries. To make a nested boolean query just use another bool instead of must, should or must_not. Here is how this query:
a = 2 and (a = 10 or b = 0)should be presented in JSON.
- JSON
a = 2 and (a = 10 or b = 0)
POST /search
{
"index":"t",
"query": {
"bool": {
"must": [
{
"equals": {
"a": 2
}
},
{
"bool": {
"should": [
{
"equals": {
"a": 10
}
},
{
"equals": {
"b": 0
}
}
]
}
}
]
}
}
}More complex query:
(a = 1 and b = 1) or (a = 10 and b = 2) or (b = 0)- JSON
(a = 1 and b = 1) or (a = 10 and b = 2) or (b = 0)
POST /search
{
"index":"t",
"query": {
"bool": {
"should": [
{
"bool": {
"must": [
{
"equals": {
"a": 1
}
},
{
"equals": {
"b": 1
}
}
]
}
},
{
"bool": {
"must": [
{
"equals": {
"a": 10
}
},
{
"equals": {
"b": 2
}
}
]
}
},
{
"bool": {
"must": [
{
"equals": {
"b": 0
}
}
]
}
}
]
}
}
}Queries in SQL format (query_string) can also be used in bool queries.
- JSON
POST /search
{
"index": "test1",
"query": {
"bool": {
"must": [
{ "query_string" : "product" },
{ "query_string" : "good" }
]
}
}
}Equality filters are the simplest filters that work with integer, float and string attributes.
- JSON
POST /search
{
"index":"test1",
"query": {
"equals": { "price": 500 }
}
}Filter equals can be applied to a multi-value attribute and you can use:
any()which will be positive if the attribute has at least one value which equals to the queried value;all()which will be positive if the attribute has a single value and it equals to the queried value
- JSON
POST /search
{
"index":"test1",
"query": {
"equals": { "any(price)": 100 }
}
}Set filters check if attribute value is equal to any of the values in the specified set.
Set filters support integer, string and multi-value attributes.
- JSON
POST /search
{
"index":"test1",
"query": {
"in": {
"price": [1,10,100]
}
}
}When applied to a multi-value attribute you can use:
any()(equivalent to no function) which will be positive if there's at least one match between the attribute values and the queried values;all()which will be positive if all the attribute values are in the queried set
- JSON
POST /search
{
"index":"test1",
"query": {
"in": {
"all(price)": [1,10]
}
}
}Range filters match documents that have attribute values within a specified range.
Range filters support the following properties:
gte: greater than or equal togt: greater thanlte: less than or equal tolt: less than
- JSON
POST /search
{
"index":"test1",
"query": {
"range": {
"price": {
"gte": 500,
"lte": 1000
}
}
}
}geo_distance filters are used to filter the documents that are within a specific distance from a geo location.
Specifies the pin location, in degrees. Distances are calculated from this point.
Specifies the attributes that contain latitude and longitude.
Specifies distance calculation function. Can be either adaptive or haversine. adaptive is faster and more precise, for more details see GEODIST(). Optional, defaults to adaptive.
Specifies the maximum distance from the pin locations. All documents within this distance match. The distance can be specified in various units. If no unit is specified, the distance is assumed to be in meters. Here is a list of supported distance units:
- Meter:
mormeters - Kilometer:
kmorkilometers - Centimeter:
cmorcentimeters - Millimeter:
mmormillimeters - Mile:
miormiles - Yard:
ydoryards - Feet:
ftorfeet - Inch:
inorinch - Nautical mile:
NM,nmiornauticalmiles
location_anchor and location_source properties accept the following latitude/longitude formats:
- an object with lat and lon keys:
{ "lat": "attr_lat", "lon": "attr_lon" } - a string of the following structure:
"attr_lat, attr_lon" - an array with the latitude and longitude in the following order:
[attr_lon, attr_lat]
Latitude and longitude are specified in degrees.
- Basic example
- Advanced example
POST /search
{
"index":"test",
"query": {
"geo_distance": {
"location_anchor": {"lat":49, "lon":15},
"location_source": {"attr_lat, attr_lon"},
"distance_type": "adaptive",
"distance":"100 km"
}
}
}geo_distance can be used as a filter in bool queries along with matches or other attribute filters.
POST /search
{
"index": "geodemo",
"query": {
"bool": {
"must": [
{
"match": {
"*": "station"
}
},
{
"equals": {
"state_code": "ENG"
}
},
{
"geo_distance": {
"distance_type": "adaptive",
"location_anchor": {
"lat": 52.396,
"lon": -1.774
},
"location_source": "latitude_deg,longitude_deg",
"distance": "10000 m"
}
}
]
}
}
}