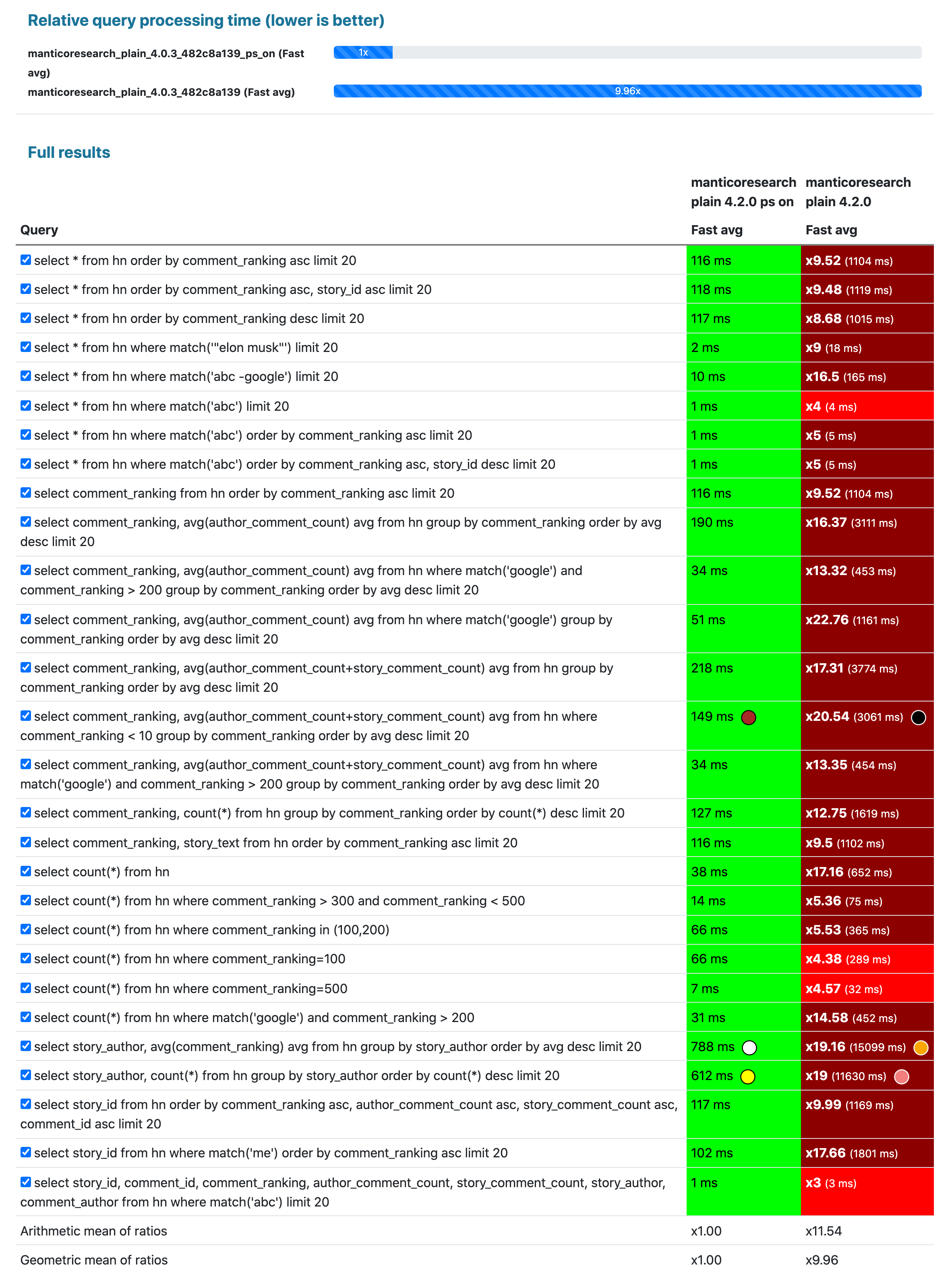
- Pseudo-sharding support for real-time indexes and full-text queries. In previous release we added limited pseudo sharding support. Starting from this version you can get all benefits of the pseudo sharding and your multi-core processor by just enabling searchd.pseudo_sharding. The coolest thing is that you don't need to do anything with your indexes or queries for that, just enable it and if you have free CPU it will be used to lower your response time. It supports plain and real-time indexes for full-text, filtering and analytical queries. For example, here is how enabling pseudo sharding can make most queries' response time in average about 10x lower on Hacker news curated comments dataset multiplied 100 times (116 million docs in a plain index).
- Debian Bullseye is now supported.
- PQ transactions are now atomic and isolated. Previously PQ transactions support was limited. It enables much faster REPLACE into PQ, especially when you need to replace a lot of rules at once. Performance details:
- 4.0.2
- 4.2.0
It takes 48 seconds to insert 1M PQ rules and 406 seconds to REPLACE just 40K in 10K batches.
root@perf3 ~ # mysql -P9306 -h0 -e "drop table if exists pq; create table pq (f text, f2 text, j json, s string) type='percolate';"; date; for m in `seq 1 1000`; do (echo -n "insert into pq (id,query,filters,tags) values "; for n in `seq 1 1000`; do echo -n "(0,'@f (cat | ( angry dog ) | (cute mouse)) @f2 def', 'j.json.language=\"en\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; [ $n != 1000 ] && echo -n ","; done; echo ";")|mysql -P9306 -h0; done; date; mysql -P9306 -h0 -e "select count(*) from pq"
Wed Dec 22 10:24:30 AM CET 2021
Wed Dec 22 10:25:18 AM CET 2021
+----------+
| count(*) |
+----------+
| 1000000 |
+----------+
root@perf3 ~ # date; (echo "begin;"; for offset in `seq 0 10000 30000`; do n=0; echo "replace into pq (id,query,filters,tags) values "; for id in `mysql -P9306 -h0 -NB -e "select id from pq limit $offset, 10000 option max_matches=1000000"`; do echo "($id,'@f (tiger | ( angry bear ) | (cute panda)) @f2 def', 'j.json.language=\"de\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; n=$((n+1)); [ $n != 10000 ] && echo -n ","; done; echo ";"; done; echo "commit;") > /tmp/replace.sql; date
Wed Dec 22 10:26:23 AM CET 2021
Wed Dec 22 10:26:27 AM CET 2021
root@perf3 ~ # time mysql -P9306 -h0 < /tmp/replace.sql
real 6m46.195s
user 0m0.035s
sys 0m0.008s- optimize_cutoff is now available as a configuration option in section
searchd. It's useful when you want to limit the RT chunks count in all your indexes to a particular number globally. - Commit 00874743 accurate count(distinct ...) and FACET ... distinct over several local physical indexes (real-time/plain) with identical fields set/order.
- PR #598 bigint support for
YEAR()and other timestamp functions. - Commit 8e85d4bc Adaptive rt_mem_limit. Previously Manticore Search was collecting exactly up to
rt_mem_limitof data before saving a new disk chunk to disk, and while saving was still collecting up to 10% more (aka double-buffer) to minimize possible insert suspension. If that limit was also exhausted, adding new documents was blocked until the disk chunk was fully saved to disk. The new adaptive limit is built on the fact that we have auto-optimize now, so it's not a big deal if disk chunks do not fully respectrt_mem_limitand start flushing a disk chunk earlier. So, now we collect up to 50% ofrt_mem_limitand save that as a disk chunk. Upon saving we look at the statistics (how much we've saved, how many new documents have arrived while saving) and recalculate the initial rate which will be used next time. For example, if we saved 90 million documents, and another 10 million docs arrived while saving, the rate is 90%, so we know that next time we can collect up to 90% ofrt_mem_limitbefore starting flushing another disk chunk. The rate value is calculated automatically from 33.3% to 95%. - Issue #628 unpack_zlib for PostgreSQL source. Thank you, Dmitry Voronin for the contribution.
- Commit 6d54cf2b
indexer -vand--version. Previously you could still see indexer's version, but-v/--versionwere not supported. - Issue #662 infinit mlock limit by default when Manticore is started via systemd.
- Commit 63c8cd05 spinlock -> op queue for coro rwlock.
- Commit 41130ce3 environment variable
MANTICORE_TRACK_RT_ERRORSuseful for debugging RT segments corruption.
- Binlog version was increased, binlog from previous version won't be replayed, so make sure you stop Manticore Search cleanly during upgrade: no binlog files should be in
/var/lib/manticore/binlog/exceptbinlog.metaafter stopping the previous instance. - Commit 3f659f36 new column "chain" in
show threads option format=all. It shows stack of some task info tickets, most useful for profiling needs, so if you are parsingshow threadsoutput be aware of the new column. searchd.workerswas obsoleted since 3.5.0, now it's deprecated, if you still have it in your configuration file it will trigger a warning on start. Manticore Search will start, but with a warning.- If you use PHP and PDO to access Manticore you need to do
PDO::ATTR_EMULATE_PREPARES
- ❗Issue #650 Manticore 4.0.2 slower than Manticore 3.6.3. 4.0.2 was faster than previous versions in terms of bulk inserts, but significantly slower for single document inserts. It's been fixed in 4.2.0.
- ❗Commit 22f4141b RT index could get corrupted under intensive REPLACE load, or it could crash
- Commit 03be91e4 fixed average at merging groupers and group N sorter; fixed merge of aggregates
- Commit 2ea575d3
indextool --checkcould crash - Commit 7ec76d4a RAM exhaustion issue caused by UPDATEs
- Commit 658a727e daemon could hang on INSERT
- Commit 46e42b9b daemon could hang on shutdown
- Commit f8d7d517 daemon could crash on shutdown
- Commit 733accf1 daemon could hang on crash
- Commit f7f8bd8c daemon could crash on startup trying to rejoin cluster with invalid nodes list
- Commit 14015561 distributed index could get completely forgotten in RT mode in case it couldn't resolve one of its agents on start
- Issue #683 attr bit(N) engine='columnar' fails
- Issue #682 create table fails, but leaves dir
- Issue #663 Config fails with: unknown key name 'attr_update_reserve'
- Issue #632 Manticore crash on batch queries
- Issue #679 Batch queries causing crashes again with v4.0.3
- Commit f7f8bd8c fixed daemon crash on startup trying to re-join cluster with invalid nodes list
- Issue #643 Manticore 4.0.2 does not accept connections after batch of inserts
- Issue #635 FACET query with ORDER BY JSON.field or string attribute could crash
- Issue #634 Crash SIGSEGV on query with packedfactors
- Commit 41657f15 morphology_skip_fields was not supported by create table
-
Full support of Manticore Columnar Library. Previously Manticore Columnar Library was supported only for plain indexes. Now it's supported:
- in real-time indexes for
INSERT,REPLACE,DELETE,OPTIMIZE - in replication
- in
ALTER - in
indextool --check
- in real-time indexes for
-
Automatic indexes compaction (Issue #478). Finally, you don't have to call OPTIMIZE manually or via a crontask or other kind of automation. Manticore now does it for you automatically and by default. You can set default compaction threshold via optimize_cutoff global variable.
-
Chunk snapshots and locks system revamp. These changes may be invisible from outside at first glance, but they improve the behaviour of many things happening in real-time indexes significantly. In a nutshell, previously most Manticore data manipulation operations relied on locks heavily, now we use disk chunk snapshots instead.
-
Significantly faster bulk INSERT performance into a real-time index. For example on Hetzner's server AX101 with SSD, 128 GB of RAM and AMD's Ryzen™ 9 5950X (16*2 cores) with 3.6.0 you could get 236K docs per second inserted into a table with schema
name text, email string, description text, age int, active bit(1)(defaultrt_mem_limit, batch size 25000, 16 concurrent insert workers, 16 million docs inserted overall). In 4.0.2 the same concurrency/batch/count gives 357K docs per second. -
ALTER can add/remove a full-text field (in RT mode). Previously it could only add/remove an attribute.
-
🔬 Experimental: pseudo-sharding for full-scan queries - allows to parallelize any non-full-text search query. Instead of preparing shards manually you can now just enable new option searchd.pseudo_sharding and expect up to
CPU coreslower response time for non-full-text search queries. Note it can easily occupy all existing CPU cores, so if you care not only about latency, but throughput too - use it with caution.
- Linux Mint and Ubuntu Hirsute Hippo are supported via APT repository
- faster update by id via HTTP in big indexes in some cases (depends on the ids distribution)
- 671e65a2 - added caching to lemmatizer-uk
- 3.6.0
- 4.0.2
time curl -X POST -d '{"update":{"index":"idx","id":4611686018427387905,"doc":{"mode":0}}}' -H "Content-Type: application/x-ndjson" http://127.0.0.1:6358/json/bulk
real 0m43.783s
user 0m0.008s
sys 0m0.007s- custom startup flags for systemd. Now you don't need to start searchd manually in case you need to run Manticore with some specific startup flag
- new function LEVENSHTEIN() which calculates Levenshtein distance
- added new searchd startup flags
--replay-flags=ignore-trx-errorsand--replay-flags=ignore-all-errorsso one can still start searchd if the binlog is corrupted - Issue #621 - expose errors from RE2
- more accurate COUNT(DISTINCT) for distributed indexes consisting of local plain indexes
- FACET DISTINCT to remove duplicates when you do faceted search
- exact form modifier doesn't require morphology now and works for indexes with infix/prefix search enabled
- the new version can read older indexes, but the older versions can't read Manticore 4's indexes
- removed implicit sorting by id. Sort explicitly if required
charset_table's default value changes from0..9, A..Z->a..z, _, a..z, U+410..U+42F->U+430..U+44F, U+430..U+44F, U+401->U+451, U+451tonon_cjkOPTIMIZEhappens automatically. If you don't need it make sure to setauto_optimize=0in sectionsearchdin the configuration file- Issue #616
ondisk_attrs_defaultwere deprecated, now they are removed - for contributors: we now use Clang compiler for Linux builds as according to our tests it can build a faster Manticore Search and Manticore Columnar Library
- if max_matches is not specified in a search query it gets updated implicitly with the lowest needed value for the sake of performance of the new columnar storage. It can affect metric
totalin SHOW META, but nottotal_foundwhich is the actual number of found documents.
- make sure you a stop Manticore 3 cleanly:
- no binlog files should be in
/var/lib/manticore/binlog/(onlybinlog.metashould be in the directory) - otherwise the indexes Manticore 4 can't reply binlogs for won't be run
- no binlog files should be in
- the new version can read older indexes, but the older versions can't read Manticore 4's indexes, so make sure you make a backup if you want to be able to rollback the new version easily
- if you run a replication cluster make sure you:
- stop all your nodes first cleanly
- and then start the node which was stopped last with
--new-cluster(run toolmanticore_new_clusterin Linux). - read about restarting a cluster for more details
- Lots of replication issues have been fixed:
- Commit 696f8649 - fixed crash during SST on joiner with active index; added sha1 verify at joiner node at writing file chunks to speed up index loading; added rotation of changed index files at joiner node on index load; added removal of index files at joiner node when active index gets replaced by a new index from donor node; added replication log points at donor node for sending files and chunks
- Commit b296c55a - crash on JOIN CLUSTER in case the address is incorrect
- Commit 418bf880 - while initial replication of a large index the joining node could fail with
ERROR 1064 (42000): invalid GTID, (null), the donor could become unresponsive while another node was joining - Commit 6fd350d2 - hash could be calculated wrong for a big index which could result in replication failure
- Issue #615 - replication failed on cluster restart
- Issue #574 -
indextool --helpdoesn't display parameter--rotate - Issue #578 - searchd high CPU usage while idle after ca. a day
- Issue #587 - flush .meta immediately
- Issue #617 - manticore.json gets emptied
- Issue #618 - searchd --stopwait fails under root. It also fixes systemctl behaviour (previously it was showing failure for ExecStop and didn't wait long enough for searchd to stop properly)
- Issue #619 - INSERT/REPLACE/DELETE vs SHOW STATUS.
command_insert,command_replaceand others were showing wrong metrics - Issue #620 -
charset_tablefor a plain index had a wrong default value - Commit 8f753688 - new disk chunks don't get mlocked
- Issue #607 - Manticore cluster node crashes when unable to resolve a node by name
- Issue #623 - replication of updated index can lead to undefined state
- Commit ca03d228 - indexer could hang on indexing a plain index source with a json attribute
- Commit 53c75305 - fixed not equal expression filter at PQ index
- Commit ccf94e02 - fixed select windows at list queries above 1000 matches.
SELECT * FROM pq ORDER BY id desc LIMIT 1000 , 100 OPTION max_matches=1100was not working previously - Commit a0483fe9 - HTTPS request to Manticore could cause warning like "max packet size(8388608) exceeded"
- Issue #648 - Manticore 3 could hang after a few updates of string attributes
Maintenance release before Manticore 4
- Support for Manticore Columnar Library for plain indexes. New setting columnar_attrs for plain indexes
- Support for Ukrainian Lemmatizer
- Fully revised histograms. When building an index Manticore also builds histograms for each field in it, which it then uses for faster filtering. In 3.6.0 the algorithm was fully revised and you can get a higher performance if you have a lot of data and do a lot of filtering.
- tool
manticore_new_cluster [--force]useful for restarting a replication cluster via systemd - --drop-src for
indexer --merge - new mode
blend_mode='trim_all' - added support for escaping JSON path with backticks
- indextool --check can work in RT mode
- FORCE/IGNORE INDEX(id) for SELECT/UPDATE
- chunk id for a merged disk chunk is now unique
- indextool --check-disk-chunk CHUNK_NAME
- faster JSON parsing, our tests show 3-4% lower latency on queries like
WHERE json.a = 1 - non-documented command
DEBUG SPLITas a prerequisite for automatic sharding/rebalancing
- Issue #584 - inaccurate and unstable FACET results
- Issue #506 - Strange behavior when using MATCH: those who suffer from this issue need to rebuild the index as the problem was on the phase of building an index
- Issue #387 - intermittent core dump when running query with SNIPPET() function
- Stack optimizations useful for processing complex queries:
- Issue #469 - SELECT results in CRASH DUMP
- e8420cc7 - stack size detection for filter trees
- Issue #461 - Update using the IN condition does not take effect correctly
- Issue #464 - SHOW STATUS immediately after CALL PQ returns - Issue #481 - Fixed static binary build
- Issue #502 - bug in multi-queries
- Issue #514 - Unable to use unusual names for columns when use 'create table'
- Commit d1dbe771 - daemon crash on replay binlog with update of string attribute; set binlog version to 10
- Commit 775d0555 - fixed expression stack frame detection runtime (test 207)
- Commit 4795dc49 - percolate index filter and tags were empty for empty stored query (test 369)
- Commit c3f0bf4d - breaks of replication SST flow at network with long latency and high error rate (different data centers replication); updated replication command version to 1.03
- Commit ba2d6619 - joiner lock cluster on write operations after join into cluster (test 385)
- Commit de4dcb9f - wildcards matching with exact modifier (test 321)
- Commit 6524fc6a - docid checkpoints vs docstore
- Commit f4ab83c2 - Inconsistent indexer behavior when parsing invalid xml
- Commit 7b727e22 - Stored percolate query with NOTNEAR runs forever (test 349)
- Commit 812dab74 - wrong weight for phrase starting with wildcard
- Commit 1771afc6 - percolate query with wildcards generate terms without payload on matching causes interleaved hits and breaks matching (test 417)
- Commit aa0d8c2b - fixed calculation of 'total' in case of parallelized query
- Commit 18d81b3c - crash in Windows with multiple concurrent sessions at daemon
- Commit 84432f23 - some index settings could not be replicated
- Commit 93411fe6 - On high rate of adding new events netloop sometimes freeze because of atomic 'kick' event being processed once for several events a time and loosing actual actions from them status of the query, not the server status
- Commit d805fc12 - New flushed disk chunk might be lost on commit
- Commit 63cbf008 - inaccurate 'net_read' in profiler
- Commit f5379bb2 - Percolate issue with arabic (right to left texts)
- Commit 49eeb420 - id not picked correctly on duplicate column name
- Commit refactoring of network events to fix a crash in rare cases
- e8420cc7 fix in
indextool --dumpheader - Commit ff716353 - TRUNCATE WITH RECONFIGURE worked wrong with stored fields
- New binlog format: you need to make a clean stop of Manticore before upgrading
- Index format slightly changes: the new version can read you existing indexes fine, but if you decide to downgrade from 3.6.0 to an older version the newer indexes will be unreadable
- Replication format change: don't replicate from an older version to 3.6.0 and vice versa, switch to the new version on all your nodes at once
reverse_scanis deprecated. Make sure you don't use this option in your queries since 3.6.0 since they will fail otherwise- As of this release we don't provide builds for RHEL6, Debian Jessie and Ubuntu Trusty any more. If it's mission critical for you to have them supported contact us
- No more implicit sorting by id. If you rely on it make sure to update your queries accordingly
- Search option
reverse_scanhas been deprecated
- New Python, Javascript and Java clients are generally available now and are well documented in this manual.
- automatic drop of a disk chunk of a real-time index. This optimization enables dropping a disk chunk automatically when OPTIMIZing a real-time index when the chunk is obviously not needed any more (all the documents are suppressed). Previously it still required merging, now the chunk can be just dropped instantly. The cutoff option is ignored, i.e. even if nothing is actually merged an obsoleted disk chunk gets removed. This is useful in case you maintain retention in your index and delete older documents. Now compacting such indexes will be faster.
- standalone NOT as an option for SELECT
- Issue #453 New option indexer.ignore_non_plain=1 is useful in case you run
indexer --alland have not only plain indexes in the configuration file. Withoutignore_non_plain=1you'll get a warning and a respective exit code. - SHOW PLAN ... OPTION format=dot and EXPLAIN QUERY ... OPTION format=dot enable visualization of full-text query plan execution. Useful for understanding complex queries.
indexer --verboseis deprecated as it never added anything to the indexer output- For dumping watchdog's backtrace signal
USR2is now to be used instead ofUSR1
- Issue #423 cyrillic char period call snippets retain mode don't highlight
- Issue #435 RTINDEX - GROUP N BY expression select = fatal crash
- Commit 2b3b62bd searchd status shows Segmentation fault when in cluster
- Commit 9dd25c19 'SHOW INDEX index.N SETTINGS' doesn't address chunks >9
- Issue #389 Bug that crashes Manticore
- Commit fba16617 Converter creates broken indexes
- Commit eecd61d8 stopword_step=0 vs CALL SNIPPETS()
- Commit ea6850e4 count distinct returns 0 at low max_matches on a local index
- Commit 362f27db When using aggregation stored texts are not returned in hits
- OPTIMIZE reduces disk chunks to a number of chunks ( default is
2* No. of cores) instead of a single one. The optimal number of chunks can be controlled by cutoff option. - NOT operator can be now used standalone. By default it is disabled since accidental single NOT queries can be slow. It can be enabled by setting new searchd directive not_terms_only_allowed to
0. - New setting max_threads_per_query sets how many threads a query can use. If the directive is not set, a query can use threads up to the value of threads.
Per
SELECTquery the number of threads can be limited with OPTION threads=N overriding the globalmax_threads_per_query. - Percolate indexes can be now be imported with IMPORT TABLE.
- HTTP API
/searchreceives basic support for faceting/grouping by new query nodeaggs.
- If no replication listen directive is declared, the engine will try to use ports after the defined 'sphinx' port, up to 200.
listen=...:sphinxneeds to be explicit set for SphinxSE connections or SphinxAPI clients.- SHOW INDEX STATUS outputs new metrics:
killed_documents,killed_rate,disk_mapped_doclists,disk_mapped_cached_doclists,disk_mapped_hitlistsanddisk_mapped_cached_hitlists. - SQL command
statusnow outputsQueue\ThreadsandTasks\Threads.
dist_threadsis completely deprecated now, searchd will log a warning if the directive is still used.
The official Docker image is now based on Ubuntu 20.04 LTS
Besides the usual manticore package, you can also install Manticore Search by components:
manticore-server- providessearchd, config and service filesmanticore-tools- provides auxiliary tools (indexer,indextooletc.)manticore-icudata- provides ICU data file for icu morphology usagemanticore-dev(DEB) ormanticore-devel(RPM) - provides dev headers for UDFs
- Commit 2a474dc1 Crash of daemon at grouper at RT index with different chunks
- Commit 57a19e5a Fastpath for empty remote docs
- Commit 07dd3f31 Expression stack frame detection runtime
- Commit 08ae357c Matching above 32 fields at percolate indexes
- Commit 16b9390f Replication listen ports range
- Commit 5fa671af Show create table on pq
- Commit 54d133b6 HTTPS port behavior
- Commit fdbbe524 Mixing docstore rows when replacing
- Commit afb53f64 Switch TFO unavailable message level to 'info'
- Commit 59d94cef Crash on strcmp invalid use
- Commit 04af0349 Adding index to cluster with system (stopwords) files
- Commit 50148b4e Merge indexes with large dictionaries; RT optimize of large disk chunks
- Commit a2adf158 Indextool can dump meta from current version
- Commit 69f6d5f7 Issue in group order in GROUP N
- Commit 24d5d80f Explicit flush for SphinxSE after handshake
- Commit 31c4d78a Avoid copy of huge descriptions when not necessary
- Commit 2959e2ca Negative time in show threads
- Commit f0b35710 Token filter plugin vs zero position deltas
- Commit a49e5bc1 Change 'FAIL' to 'WARNING' on multiple hits
-
This release took so long, because we were working hard on changing multitasking mode from threads to coroutines. It makes configuration simpler and queries parallelization much more straightforward: Manticore just uses given number of threads (see new setting threads) and the new mode makes sure it's done in the most optimal way.
-
Changes in highlighting:
- any highlighting that works with several fields (
highlight({},'field1, field2') orhighlightin json queries) now applies limits per-field by default. - any highlighting that works with plain text (
highlight({}, string_attr)orsnippet()now applies limits to the whole document. - per-field limits can be switched to global limits by
limits_per_field=0option (1by default). - allow_empty is now
0by default for highlighting via HTTP JSON.
- any highlighting that works with several fields (
-
The same port can now be used for http, https and binary API (to accept connections from a remote Manticore instance).
listen = *:mysqlis still required for connections via mysql protocol. Manticore now detects automatically the type of client trying to connect to it except for MySQL (due to restrictions of the protocol). -
In RT mode a field can now be text and string attribute at the same time - GitHub issue #331.
In plain mode it's called
sql_field_string. Now it's available in RT mode for real-time indexes too. You can use it as shown in the example:create table t(f string attribute indexed); insert into t values(0,'abc','abc'); select * from t where match('abc'); +---------------------+------+ | id | f | +---------------------+------+ | 2810845392541843463 | abc | +---------------------+------+ 1 row in set (0.01 sec) mysql> select * from t where f='abc'; +---------------------+------+ | id | f | +---------------------+------+ | 2810845392541843463 | abc | +---------------------+------+ 1 row in set (0.00 sec)
- You can now highlight string attributes.
- SSL and compression support for SQL interface
- Support of mysql client
statuscommand. - Replication can now replicate external files (stopwords, exceptions etc.).
- Filter operator
inis now available via HTTP JSON interface. expressionsin HTTP JSON.- You can now change
rt_mem_limiton the fly in RT mode, i.e. can doALTER ... rt_mem_limit=<new value>. - You can now use separate CJK charset tables:
chinese,japaneseandkorean. - thread_stack now limits maximum thread stack, not initial.
- Improved
SHOW THREADSoutput. - Display progress of long
CALL PQinSHOW THREADS. - cpustat, iostat, coredump can be changed during runtime with SET.
SET [GLOBAL] wait_timeout=NUMimplemented ,
- Index format has been changed. Indexes built in 3.5.0 cannot be loaded by Manticore version < 3.5.0, but Manticore 3.5.0 understands older formats.
INSERT INTO PQ VALUES()(i.e. without providing column list) previously expected exactly(query, tags)as the values. It's been changed to(id,query,tags,filters). The id can be set to 0 if you want it to be auto-generated.allow_empty=0is a new default in highlighting via HTTP JSON interface.- Only absolute paths are allowed for external files (stopwords, exceptions etc.) in
CREATE TABLE/ALTER TABLE.
ram_chunks_countwas renamed toram_chunk_segments_countinSHOW INDEX STATUS.workersis obsolete. There's only one workers mode now.dist_threadsis obsolete. All queries are as much parallel as possible now (limited bythreadsandjobs_queue_size).max_childrenis obsolete. Use threads to set the number of threads Manticore will use (set to the # of CPU cores by default).queue_max_lengthis obsolete. Instead of that in case it's really needed use jobs_queue_size to fine-tune internal jobs queue size (unlimited by default).- All
/json/*endpoints are now available w/o/json/, e.g./search,/insert,/delete,/pqetc. fieldmeaning "full-text field" was renamed to "text" indescribe.3.4.2:
mysql> describe t; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | field | indexed stored | +-------+--------+----------------+3.5.0:
mysql> describe t; +-------+--------+----------------+ | Field | Type | Properties | +-------+--------+----------------+ | id | bigint | | | f | text | indexed stored | +-------+--------+----------------+- Cyrillic
иdoesn't map toiinnon_cjkcharset_table (which is a default) as it affected Russian stemmers and lemmatizers too much. read_timeout. Use network_timeout instead which controls both reading and writing.
- Ubuntu Focal 20.04 official package
- deb package name changed from
manticore-bintomanticore
- Issue #351 searchd memory leak
- Commit ceabe44f Tiny read out of bounds in snippets
- Commit 1c3e84a3 Dangerous write into local variable for crash queries
- Commit 26e094ab Tiny memory leak of sorter in test 226
- Commit d2c7f86a Huge memory leak in test 226
- Commit 0dd80122 Cluster shows the nodes are in sync, but
count(*)shows different numbers - Commit f1c1ac3f Cosmetic: Duplicate and sometimes lost warning messages in the log
- Commit f1c1ac3f Cosmetic: (null) index name in log
- Commit 359dbd30 Cannot retrieve more than 70M results
- Commit 19f328ee Can't insert PQ rules with no-columns syntax
- Commit bf685d5d Misleading error message when inserting a document to an index in a cluster
- Commit 2cf18c83
/json/replaceandjson/updatereturn id in exponent form - Issue #324 Update json scalar properties and mva in the same query
- Commit d38409eb
hitless_wordsdoesn't work in RT mode - Commit 5813d639
ALTER RECONFIGUREin rt mode should be disallowed - Commit 5813d639
rt_mem_limitgets reset to 128M after searchd restart - highlight() sometimes hangs
- Commit 7cd878f4 Failed to use U+code in RT mode
- Commit 2b213de4 Failed to use wildcard at wordforms at RT mode
- Commit e9d07e68 Fixed
SHOW CREATE TABLEvs multiple wordform files - Commit fc90a84f JSON query without "query" crashes searchd
- Manticore official docker couldn't index from mysql 8
- Commit 23e05d32 HTTP /json/insert requires id
- Commit bd679af0
SHOW CREATE TABLEdoesn't work for PQ - Commit bd679af0
CREATE TABLE LIKEdoesn't work properly for PQ - Commit 5eacf28f End of line in settings in show index status
- Commit cb153228 Empty title in "highlight" in HTTP JSON response
- Issue #318
CREATE TABLE LIKEinfix error - Commit 9040d22c RT crashes under load
- cd512c7d Lost crash log on crash at RT disk chunk
- Issue #323 Import table fails and closes the connection
- Commit 6275316a
ALTER reconfigurecorrupts a PQ index - Commit 9c1d221e Searchd reload issues after change index type
- Commit 71e2b5bb Daemon crashes on import table with missed files
- Issue #322 Crash on select using multiple indexes, group by and ranker = none
- Commit c3f58490
HIGHLIGHT()doesn't higlight in string attributes - Issue #320
FACETfails to sort on string attribute - Commit 4f1a1f25 Error in case of missing data dir
- Commit 04f4ddd4 access_* are not supported in RT mode
- Commit 1c0616a2 Bad JSON objects in strings: 1.
CALL PQreturns "Bad JSON objects in strings: 1" when the json is greater than some value. - Commit 32f943d6 RT-mode inconsistency. In some cases I can't drop the index since it's unknown and can't create it since the directory is not empty.
- Issue #319 Crash on select
- Commit 22a28dd7
max_xmlpipe2_field= 2M returned warning on 2M field - Issue #342 Query conditions execution bug
- Commit dd8dcab2 Simple 2 terms search finds a document containing only one term
- Commit 90919e62 It was impossible in PQ to match a json with capital letters in keys
- Commit 56da086a Indexer crashes on csv+docstore
- Issue #363 using
[null]in json attr in centos 7 causes corrupted inserted data - Major Issue #345 Records not being inserted, count() is random, "replace into" returns OK
- max_query_time slows down SELECTs too much
- Issue #352 Master-agent communication fails on Mac OS
- Issue #328 Error when connecting to Manticore with Connector.Net/Mysql 8.0.19
- Commit daa760d2 Fixed escaping of \0 and optimized performance
- Commit 9bc5c01a Fixed count distinct vs json
- Commit 4f89a965 Fixed drop table at other node failed
- Commit 952af5a5 Fix crashes on tightly running call pq
- Commit 2ffe2d26 fix RT index from old version fails to index data
- server works in 2 modes: rt-mode and plain-mode
- rt-mode requires data_dir and no index definition in config
- in plain-mode indexes are defined in config; no data_dir allowed
- replication available only in rt-mode
- charset_table defaults to non_cjk alias
- in rt-mode full-text fields are indexed and stored by default
- full-text fields in rt-mode renamed from 'field' to 'text'
- ALTER RTINDEX is renamed to ALTER TABLE
- TRUNCATE RTINDEX is renamed to TRUNCATE TABLE
- stored-only fields
- SHOW CREATE TABLE, IMPORT TABLE
- much faster lockless PQ
- /sql can execute any type of SQL statement in mode=raw
- alias mysql for mysql41 protocol
- default state.sql in data_dir
- Commit a5333644 fix crash on wrong field syntax in highlight()
- Commit 7fbb9f2e fix crash of server on replicate RT index with docstore
- Commit 24a04687 fix crash on highlight to index with infix or prefix option and to index wo stored fields enabled
- Commit 3465c1ce fix false error about empty docstore and dock-id lookup for empty index
- Commit a707722e fix #314 SQL insert command with trailing semicolon
- Commit 95628c9b removed warning on query word(s) mismatch
- Commit b8601b41 fix queries in snippets segmented via ICU
- Commit 5275516c fix find/add race condition in docstore block cache
- Commit f06ef97a fix mem leak in docstore
- Commit a7258ba8 fix #316 LAST_INSERT_ID returns empty on INSERT
- Commit 1ebd5bf8 fix #317 json/update HTTP endpoint to support array for MVA and object for JSON attribute
- Commit e426950a fix rash of indexer dumping rt without explicit id
- Parallel Real-Time index searching
- EXPLAIN QUERY command
- configuration file without index definitions (alpha version)
- CREATE/DROP TABLE commands (alpha version)
- indexer --print-rt - can read from a source and print INSERTs for a Real-Time index
- Updated to Snowball 2.0 stemmers
- LIKE filter for SHOW INDEX STATUS
- improved memory usage for high max_matches
- SHOW INDEX STATUS adds ram_chunks_count for RT indexes
- lockless PQ
- changed LimitNOFILE to 65536
- Commit 9c33aab8 added check of index schema for duplicate attributes #293
- Commit a0085f94 fix crash in hitless terms
- Commit 68953740 fix loose docstore after ATTACH
- Commit d6f696ed fix docstore issue in distributed setup
- Commit bce2b7ec replace FixedHash with OpenHash in sorter
- Commit e0baf739 fix attributes with duplicated names at index definition
- Commit ca81114b fix html_strip in HIGHLIGHT()
- Commit 493a5e91 fix passage macro in HIGHLIGHT()
- Commit a82d41c7 fix double buffer issues when RT index creates small or large disk chunk
- Commit a404c85d fix event deletion for kqueue
- Commit 8bea0f6f fix save of disk chunk for large value of rt_mem_limit of RT index
- Commit 8707f039 fix float overflow on indexing
- Commit a56434ce fix insert document with negative ID into RT index fails with error now
- Commit bbebfd75 fix crash of server on ranker fieldmask
- Commit 3809cc1b fix crash on using query cache
- Commit dc2a585b fix crash on using RT index RAM segments with parallel inserts
- Autoincrement ID for RT indexes
- Highlight support for docstore via new HIGHLIGHT() function, available also in HTTP API
- SNIPPET() can use special function QUERY() which returns current MATCH query
- new field_separator option for highlighting functions.
- lazy fetch of stored fields for remote nodes (can significantly increase performance)
- strings and expressions don't break anymore multi-query and FACET optimizations
- RHEL/CentOS 8 build now uses mysql libclient from mariadb-connector-c-devel
- ICU data file is now shipped with the packages, icu_data_dir removed
- systemd service files include 'Restart=on-failure' policy
- indextool can now check real-time indexes online
- default conf is now /etc/manticoresearch/manticore.conf
- service on RHEL/CentOS renamed to 'manticore' from 'searchd'
- removed query_mode and exact_phrase snippet's options
- Commit 6ae474c7 fix crash on SELECT query over HTTP interface
- Commit 59577513 fix RT index saves disk chunks but does not mark some documents deleted
- Commit e861f0fc fix crash on search of multi index or multi queries with dist_threads
- Commit 440991fc fix crash on infix generation for long terms with wide utf8 codepoints
- Commit 5fd599b4 fix race at adding socket to IOCP
- Commit cf10d7d3 fix issue of bool queries vs json select list
- Commit 996de77f fix indextool check to report wrong skiplist offset, check of doc2row lookup
- Commit 6e3fc9e8 fix indexer produces bad index with negative skiplist offset on large data
- Commit faed3220 fix JSON converts only numeric to string and JSON string to numeric conversion at expressions
- Commit 53319720 fix indextool exit with error code in case multiple commands set at command line
- Commit 795520ac fix #275 binlog invalid state on error no space left on disk
- Commit 2284da5e fix #279 crash on IN filter to JSON attribute
- Commit ce2e4b47 fix #281 wrong pipe closing call
- Commit 535589ba fix server hung at CALL PQ with recursive JSON attribute encoded as string
- Commit a5fc8a36 fix advancing beyond the end of the doclist in multiand node
- Commit a3628617 fix retrieving of thread public info
- Commit f8d2d7bb fix docstore cache locks
- Document storage
- new directives stored_fields, docstore_cache_size, docstore_block_size, docstore_compression, docstore_compression_level
- improved SSL support
- non_cjk built-in charset updated
- disabled UPDATE/DELETE statements logging a SELECT in query log
- RHEL/CentOS 8 packages
- Commit 301a806b1 fix crash on replace document in disk chunk of RT index
- Commit 46c1cad8f fix #269 LIMIT N OFFSET M
- Commit 92a46edaa fix DELETE statements with id explicitly set or id list provided to skip search
- Commit 8ca78c138 fix wrong index after event removed at netloop at windowspoll poller
- Commit 603631e2b fix float roundup at JSON via HTTP
- Commit 62f64cb9e fix remote snippets to check empty path first; fixing windows tests
- Commit aba274c2c fix reload of config to work on windows same way as on linux
- Commit 6b8c4242e fix #194 PQ to work with morphology and stemmers
- Commit 174d31290 fix RT retired segments management
- Experimental SSL support for HTTP API
- field filter for CALL KEYWORDS
- max_matches for /json/search
- automatic sizing of default Galera gcache.size
- improved FreeBSD support
- Commit 0a1a2c81 fixed replication of RT index into node where same RT index exists and has different path
- Commit 4adc0752 fix flush rescheduling for indexes without activity
- Commit d6c00a6f improve rescheduling of flushing RT/PQ indexes
- Commit d0a7c959 fix #250 index_field_lengths index option for TSV and CSV piped sources
- Commit 1266d548 fix indextool wrong report for block index check on empty index
- Commit 553ca73c fix empty select list at Manticore SQL query log
- Commit 56c85844 fix indexer -h/--help response
- replication for RealTime indexes
- ICU tokenizer for chinese
- new morphology option icu_chinese
- new directive icu_data_dir
- multiple statements transactions for replication
- LAST_INSERT_ID() and @session.last_insert_id
- LIKE 'pattern' for SHOW VARIABLES
- Multiple documents INSERT for percolate indexes
- Added time parsers for config
- internal task manager
- mlock for doc and hit lists components
- jail snippets path
- RLP library support dropped in favor of ICU; all rlp* directives removed
- updating document ID with UPDATE is disabled
- Commit f0472223 fix defects in concat and group_concat
- Commit b08147ee fix query uid at percolate index to be BIGINT attribute type
- Commit 4cd85afa do not crash if failed to prealloc a new disk chunk
- Commit 1a551227 add missing timestamp data type to ALTER
- Commit f3a8e096 fix crash of wrong mmap read
- Commit 44757711 fix hash of clusters lock in replication
- Commit ff476df9 fix leak of providers in replication
- Commit 58dcbb77 fix #246 undefined sigmask in indexer
- Commit 3dd8278e fix race in netloop reporting
- Commit a02aae05 zero gap for HA strategies rebalancer
- added mmap readers for docs and hit lists
- /sql HTTP endpoint response is now the same as /json/search response
- new directives access_plain_attrs, access_blob_attrs, access_doclists, access_hitlists
- new directive server_id for replication setups
- removed HTTP /search endpoint
- read_buffer, ondisk_attrs, ondisk_attrsdefault, mlock (replaced by `access*` directives)
- Commit 849c16e1 allow attribute names starting with numbers in select list
- Commit 48e6c302 fixed MVAs in UDFs, fixed MVA aliasing
- Commit 055586a9 fixed #187 crash when using query with SENTENCE
- Commit 93bf52f2 fixed #143 support () around MATCH()
- Commit 599ee79c fixed save of cluster state on ALTER cluster statement
- Commit 230c321e fixed crash of server on ALTER index with blob attributes
- Commit 5802b85a fixed #196 filtering by id
- Commit 25d2dabd discard searching on template indexes
- Commit 2a30d5b4 fixed id column to have regular bigint type at SQL reply
- New index storage. Non-scalar attributes are not limited anymore to 4GB size per index
- attr_update_reserve directive
- String,JSON and MVAs can be updated using UPDATE
- killlists are applied at index load time
- killlist_target directive
- multi AND searches speedup
- better average performance and RAM usage
- convert tool for upgrading indexes made with 2.x
- CONCAT() function
- JOIN CLUSTER cluster AT 'nodeaddress:port'
- ALTER CLUSTER posts UPDATE nodes
- node_address directive
- list of nodes printed in SHOW STATUS
- in case of indexes with killists, server doesn't rotate indexes in order defined in conf, but follows the chain of killlist targets
- order of indexes in a search no longer defines the order in which killlists are applied
- Document IDs are now signed big integers
- docinfo (always extern now), inplace_docinfo_gap, mva_updates_pool
- Galera replication for percolate indexes
- OPTION morphology
Cmake minimum version is now 3.13. Compiling requires boost and libssl development libraries.
- Commit 6967fedb fixed crash on many stars at select list for query into many distributed indexes
- Commit 36df1a40 fixed #177 large packet via Manticore SQL interface
- Commit 57932aec fixed #170 crash of server on RT optimize with MVA updated
- Commit edb24b87 fixed server crash on binlog removed due to RT index remove after config reload on SIGHUP
- Commit bd3e66e0 fixed mysql handshake auth plugin payloads
- Commit 6a217f6e fixed #172 phrase_boundary settings at RT index
- Commit 3562f652 fixed #168 deadlock at ATTACH index to itself
- Commit 250b3f0e fixed binlog saves empty meta after server crash
- Commit 4aa6c69a fixed crash of server due to string at sorter from RT index with disk chunks
- SUBSTRING_INDEX()
- SENTENCE and PARAGRAPH support for percolate queries
- systemd generator for Debian/Ubuntu; also added LimitCORE to allow core dumping
- Commit 84fe7405 fixed crash of server on match mode all and empty full text query
- Commit daa88b57 fixed crash on deleting of static string
- Commit 22078537 fixed exit code when indextool failed with FATAL
- Commit 0721696d fixed #109 no matches for prefixes due to wrong exact form check
- Commit 8af81011 fixed #161 reload of config settings for RT indexes
- Commit e2d59277 fixed crash of server on access of large JSON string
- Commit 75cd1342 fixed PQ field at JSON document altered by index stripper causes wrong match from sibling field
- Commit e2f77543 fixed crash of server at parse JSON on RHEL7 builds
- Commit 3a25a580 fixed crash of json unescaping when slash is on the edge
- Commit be9f4978 fixed option 'skip_empty' to skip empty docs and not warn they're not valid json
- Commit 266e0e7b fixed #140 output 8 digits on floats when 6 is not enough to be precise
- Commit 3f6d2389 fixed empty jsonobj creation
- Commit f3c7848a fixed #160 empty mva outputs NULL instead of an empty string
- Commit 0afa2ed0 fixed fail to build without pthread_getname_np
- Commit 9405fccd fixed crash on server shutdown with thread_pool workers
- Distributed indexes for percolate indexes
- CALL PQ new options and changes:
- skip_bad_json
- mode (sparsed/sharded)
- json documents can be passed as a json array
- shift
- Column names 'UID', 'Documents', 'Query', 'Tags', 'Filters' were renamed to 'id', 'documents', 'query', 'tags', 'filters'
- DESCRIBE pq TABLE
- SELECT FROM pq WHERE UID is not possible any more, use 'id' instead
- SELECT over pq indexes is on par with regular indexes (e.g. you can filter rules via REGEX())
- ANY/ALL can be used on PQ tags
- expressions have auto-conversion for JSON fields, not requiring explicit casting
- built-in 'non_cjk' charset_table and 'cjk' ngram_chars
- built-in stopwords collections for 50 languages
- multiple files in a stopwords declaration can also be separated by comma
- CALL PQ can accept JSON array of documents
- Commit a4e19af fixed csjon-related leak
- Commit 28d8627 fixed crash because of missed value in json
- Commit bf4e9ea fixed save of empty meta for RT index
- Commit 33b4573 fixed lost form flag (exact) for sequence of lemmatizer
- Commit 6b95d48 fixed string attrs > 4M use saturate instead of overflow
- Commit 621418b fixed crash of server on SIGHUP with disabled index
- Commit 3f7e35d fixed server crash on simultaneous API session status commands
- Commit cd9e4f1 fixed crash of server at delete query to RT index with field filters
- Commit 9376470 fixed crash of server at CALL PQ to distributed index with empty document
- Commit 8868b20 fixed cut Manticore SQL error message larger 512 chars
- Commit de9deda fixed crash on save percolate index without binlog
- Commit 2b219e1 fixed http interface is not working in OSX
- Commit e92c602 fixed indextool false error message on check of MVA
- Commit 238bdea fixed write lock at FLUSH RTINDEX to not write lock whole index during save and on regular flush from rt_flush_period
- Commit c26a236 fixed ALTER percolate index stuck waiting search load
- Commit 9ee5703 fixed max_children to use default amount of thread_pool workers for value of 0
- Commit 5138fc0 fixed error on indexing of data into index with index_token_filter plugin along with stopwords and stopword_step=0
- Commit 2add3d3 fixed crash with absent lemmatizer_base when still using aot lemmatizers in index definitions
- REGEX function
- limit/offset for json API search
- profiler points for qcache
- Commit eb3c768 fixed crash of server on FACET with multiple attribute wide types
- Commit d915cf6 fixed implicit group by at main select list of FACET query
- Commit 5c25dc2 fixed crash on query with GROUP N BY
- Commit 85d30a2 fixed deadlock on handling crash at memory operations
- Commit 85166b5 fixed indextool memory consumption during check
- Commit 58fb031 fixed gmock include not needed anymore as upstream resolve itself
- SHOW THREADS in case of remote distributed indexes prints the original query instead of API call
- SHOW THREADS new option
format=sphinxqlprints all queries in SQL format - SHOW PROFILE prints additional
clone_attrsstage
- Commit 4f15571 fixed failed to build with libc without malloc_stats, malloc_trim
- Commit f974f20 fixed special symbols inside words for CALL KEYWORDS result set
- Commit 0920832 fixed broken CALL KEYWORDS to distributed index via API or to remote agent
- Commit fd686bf fixed distributed index agent_query_timeout propagate to agents as max_query_time
- Commit 4ffa623 fixed total documents counter at disk chunk got affected by OPTIMIZE command and breaks weight calculation
- Commit dcaf4e0 fixed multiple tail hits at RT index from blended
- Commit eee3817 fixed deadlock at rotation
- sort_mode option for CALL KEYWORDS
- DEBUG on VIP connection can perform 'crash
' for intentional SIGEGV action on server - DEBUG can perform 'malloc_stats' for dumping malloc stats in searchd.log 'malloc_trim' to perform a malloc_trim()
- improved backtrace is gdb is present on the system
- Commit 0f3cc33 fixed crash or hfailure of rename on Windows
- Commit 1455ba2 fixed crashes of server on 32-bit systems
- Commit ad3710d fixed crash or hung of server on empty SNIPPET expression
- Commit b36d792 fixed broken non progressive optimize and fixed progressive optimize to not create kill-list for oldest disk chunk
- Commit 34b0324 fixed queue_max_length bad reply for SQL and API at thread pool worker mode
- Commit ae4b320 fixed crash on adding full-scan query to PQ index with regexp or rlp options set
- Commit f80f8d5 fixed crash when call one PQ after another
- Commit 9742f5f refactor AcquireAccum
- Commit 39e5bc3 fixed leak of memory after call pq
- Commit 21bcc6d cosmetic refactor (c++11 style c-trs, defaults, nullptrs)
- Commit 2d69039 fixed memory leak on trying to insert duplicate into PQ index
- Commit 5ed92c4 fixed crash on JSON field IN with large values
- Commit 4a5262e fixed crash of server on CALL KEYWORDS statement to RT index with expansion limit set
- Commit 552646b fixed invalid filter at PQ matches query;
- Commit 204f521 introduce small obj allocator for ptr attrs
- Commit 25453e5 refactor ISphFieldFilter to refcounted flavour
- Commit 1366ee0 fixed ub/sigsegv when using strtod on non-terminated strings
- Commit 94bc6fc fixed memory leak in json resultset processing
- Commit e78e9c9 fixed read over the end of mem block applying attribute add
- Commit fad572f fixed refactor CSphDict for refcount flavour
- Commit fd841a4 fixed leak of AOT internal type outside
- Commit 5ee7f20 fixed memory leak tokenizer management
- Commit 116c5f1 fixed memory leak in grouper
- Commit 56fdbc9 special free/copy for dynamic ptrs in matches (memory leak grouper)
- Commit b1fc161 fixed memory leak of dynamic strings for RT
- Commit 517b9e8 refactor grouper
- Commit b1fc161 minor refactor (c++11 c-trs, some reformats)
- Commit 7034e07 refactor ISphMatchComparator to refcounted flavour
- Commit b1fc161 privatize cloner
- Commit efbc051 simplify native little-endian for MVA_UPSIZE, DOCINFO2ID_T, DOCINFOSETID
- Commit 6da0df4 add valgrind support to to ubertests
- Commit 1d17669 fixed crash because race of 'success' flag on connection
- Commit 5a09c32 switch epoll to edge-triggered flavour
- Commit 5d52868 fixed IN statement in expression with formatting like at filter
- Commit bd8b3c9 fixed crash at RT index on commit of document with large docid
- Commit ce656b8 fixed argless options in indextool
- Commit 08c9507 fixed memory leak of expanded keyword
- Commit 30c75a2 fixed memory leak of json grouper
- Commit 6023f26 fixed leak of global user vars
- Commit 7c138f1 fixed leakage of dynamic strings on early rejected matches
- Commit 9154b18 fixed leakage on length(
) - Commit 43fca3a fixed memory leak because strdup() in parser
- Commit 71ff777 fixed refactor expression parser to accurate follow refcounts
- compatibility with MySQL 8 clients
- TRUNCATE WITH RECONFIGURE
- retired memory counter on SHOW STATUS for RT indexes
- global cache of multi agents
- improved IOCP on Windows
- VIP connections for HTTP protocol
- Manticore SQL DEBUG command which can run various subcommands
- shutdown_token - SHA1 hash of password needed to invoke
shutdownusing DEBUG command - new stats to SHOW AGENT STATUS (_ping, _has_perspool, _need_resolve)
- --verbose option of indexer now accept [debugvv] for printing debug messages
- Commit 390082 removed wlock at optimize
- Commit 4c3376 fixed wlock at reload index settings
- Commit b5ea8d fixed memory leak on query with JSON filter
- Commit 930e83 fixed empty documents at PQ result set
- Commit 53deec fixed confusion of tasks due to removed one
- Commit cad9b9 fixed wrong remote host counting
- Commit 90008c fixed memory leak of parsed agent descriptors
- Commit 978d83 fixed leak in search
- Commit 019394 cosmetic changes on explicit/inline c-trs, override/final usage
- Commit 943e29 fixed leak of json in local/remote schema
- Commit 02dbdd fixed leak of json sorting col expr in local/remote schema
- Commit c74d0b fixed leak of const alias
- Commit 6e5b57 fixed leak of preread thread
- Commit 39c740 fixed stuck on exit because of stucked wait in netloop
- Commit adaf97 fixed stuck of 'ping' behaviour on change HA agent to usual host
- Commit 32c40e separate gc for dashboard storage
- Commit 511a3c fixed ref-counted ptr fix
- Commit 32c40e fixed indextool crash on unexistent index
- Commit 156edc fixed output name of exceeding attr/field in xmlpipe indexing
- Commit cdac6d fixed default indexer's value if no indexer section in config
- Commit e61ec0 fixed wrong embedded stopwords in disk chunk by RT index after server restart
- Commit 5fba49 fixed skip phantom (already closed, but not finally deleted from the poller) connections
- Commit f22ae3 fixed blended (orphaned) network tasks
- Commit 46890e fixed crash on read action after write
- Commit 03f9df fixed searchd crashes when running tests on windows
- Commit e9255e fixed handle EINPROGRESS code on usual connect()
- Commit 248b72 fixed connection timeouts when working with TFO
- improved wildcards performance on matching multiple documents at PQ
- support for fullscan queries at PQ
- support for MVA attributes at PQ
- regexp and RLP support for percolate indexes
- Commit 688562 fixed loose of query string
- Commit 0f1770 fixed empty info at SHOW THREADS statement
- Commit 53faa3 fixed crash on matching with NOTNEAR operator
- Commit 26029a fixed error message on bad filter to PQ delete
- reduced number of syscalls to avoid Meltdown and Spectre patches impact
- internal rewrite of local index management
- remote snippets refactor
- full configuration reload
- all node connections are now independent
- proto improvements
- Windows communication switched from wsapoll to IO completion ports
- TFO can be used for communication between master and nodes
- SHOW STATUS now outputs to server version and mysql_version_string
- added
docs_idoption for documents called in CALL PQ. - percolate queries filter can now contain expressions
- distributed indexes can work with FEDERATED
- dummy SHOW NAMES COLLATE and
SET wait_timeout(for better ProxySQL compatibility)
- Commit 5bcff0 fixed added not equal to tags of PQ
- Commit 9ebc58 fixed added document id field to JSON document CALL PQ statement
- Commit 8ae0e5 fixed flush statement handlers to PQ index
- Commit c24b15 fixed PQ filtering on JSON and string attributes
- Commit 1b8bdd fixed parsing of empty JSON string
- Commit 1ad8a0 fixed crash at multi-query with OR filters
- Commit 69b898 fixed indextool to use config common section (lemmatizer_base option) for commands (dumpheader)
- Commit 6dbeaf fixed empty string at result set and filter
- Commit 39c4eb fixed negative document id values
- Commit 266b70 fixed word clip length for very long words indexed
- Commit 47823b fixed matching multiple documents of wildcard queries at PQ
- MySQL FEDERATED engine support
- MySQL packets return now SERVER_STATUS_AUTOCOMMIT flag, adds compatibility with ProxySQL
- listen_tfo - enable TCP Fast Open connections for all listeners
- indexer --dumpheader can dump also RT header from .meta file
- cmake build script for Ubuntu Bionic
- Commit 355b116 fixed invalid query cache entries for RT index;
- Commit 546e229 fixed index settings got lost next after seamless rotation
- Commit 0c45098 fixed fixed infix vs prefix length set; added warning on unsupportedinfix length
- Commit 80542fa fixed RT indexes auto-flush order
- Commit 705d8c5 fixed result set schema issues for index with multiple attributes and queries to multiple indexes
- Commit b0ba932 fixed some hits got lost at batch insert with document duplicates
- Commit 4510fa4 fixed optimize failed to merge disk chunks of RT index with large documents count
- jemalloc at compilation. If jemalloc is present on system, it can be enabled with cmake flag
-DUSE_JEMALLOC=1
- Commit 85a6d7e fixed log expand_keywords option into Manticore SQL query log
- Commit caaa384 fixed HTTP interface to correctly process query with large size
- Commit e386d84 fixed crash of server on DELETE to RT index with index_field_lengths enable
- Commit cd538f3 fixed cpustats searchd cli option to work with unsupported systems
- Commit 8740fd6 fixed utf8 substring matching with min lengths defined
- improved Percolate Queries performance in case of using NOT operator and for batched documents.
- percolate_query_call can use multiple threads depending on dist_threads
- new full-text matching operator NOTNEAR/N
- LIMIT for SELECT on percolate indexes
- expand_keywords can accept 'start','exact' (where 'star,exact' has same effect as '1')
- ranged-main-query for joined fields which uses the ranged query defined by sql_query_range
- Commit 72dcf66 fixed crash on searching ram segments; deadlock on save disk chunk with double buffer; deadlock on save disk chunk during optimize
- Commit 3613714 fixed indexer crash on xml embedded schema with empty attribute name
- Commit 48d7e80 fixed erroneous unlinking of not-owned pid-file
- Commit a5563a4 fixed orphaned fifos sometimes left in temp folder
- Commit 2376e8f fixed empty FACET result set with wrong NULL row
- Commit 4842b67 fixed broken index lock when running server as windows service
- Commit be35fee fixed wrong iconv libs on mac os
- Commit 83744a9 fixed wrong count(*)
- agent_retry_count in case of agents with mirrors gives the value of retries per mirror instead of per agent, the total retries per agent being agent_retry_count*mirrors.
- agent_retry_count can now be specified per index, overriding global value. An alias mirror_retry_count is added.
- a retry_count can be specified in agent definition and the value represents retries per agent
- Percolate Queries are now in HTTP JSON API at /json/pq.
- Added -h and -v options (help and version) to executables
- morphology_skip_fields support for Real-Time indexes
- Commit a40b079 fixed ranged-main-query to correctly work with sql_range_step when used at MVA field
- Commit f2f5375 fixed issue with blackhole system loop hung and blackhole agents seems disconnected
- Commit 84e1f54 fixed query id to be consistent, fixed duplicated id for stored queries
- Commit 1948423 fixed server crash on shutdown from various states
- Commit 9a706b Commit 3495fd7 timeouts on long queries
- Commit 3359bcd8 refactored master-agent network polling on kqueue-based systems (Mac OS X, BSD).
- HTTP JSON: JSON queries can now do equality on attributes, MVA and JSON attributes can be used in inserts and updates, updates and deletes via JSON API can be performed on distributed indexes
- Percolate Queries
- Removed support for 32-bit docids from the code. Also removed all the code that converts/loads legacy indexes with 32-bit docids.
- Morphology only for certain fields . A new index directive morphology_skip_fields allows defining a list of fields for which morphology does not apply.
- expand_keywords can now be a query runtime directive set using the OPTION statement
- Commit 0cfae4c fixed crash on debug build of server (and m.b. UB on release) when built with rlp
- Commit 324291e fixed RT index optimize with progressive option enabled that merges kill-lists with wrong order
- Commit ac0efee minor crash on mac
- lots of minor fixes after thorough static code analysis
- other minor bugfixes
In this release we've changed internal protocol used by masters and agents to speak with each other. In case you run Manticoresearch in a distributed environment with multiple instances make sure your first upgrade agents, then the masters.
- JSON queries on HTTP API protocol. Supported search, insert, update, delete, replace operations. Data manipulation commands can be also bulked, also there are some limitations currently as MVA and JSON attributes can't be used for inserts, replaces or updates.
- RELOAD INDEXES command
- FLUSH LOGS command
- SHOW THREADS can show progress of optimize, rotation or flushes.
- GROUP N BY work correctly with MVA attributes
- blackhole agents are run on separate thread to not affect master query anymore
- implemented reference count on indexes, to avoid stalls caused by rotations and high load
- SHA1 hashing implemented, not exposed yet externally
- fixes for compiling on FreeBSD, macOS and Alpine
- Commit 989752b filter regression with block index
- Commit b1c3864 rename PAGE_SIZE -> ARENA_PAGE_SIZE for compatibility with musl
- Commit f2133cc disable googletests for cmake < 3.1.0
- Commit f30ec53 failed to bind socket on server restart
- Commit 0807240 fixed crash of server on shutdown
- Commit 3e3acc3 fixed show threads for system blackhole thread
- Commit 262c3fe Refactored config check of iconv, fixes building on FreeBSD and Darwin
- OR operator in WHERE clause between attribute filters
- Maintenance mode ( SET MAINTENANCE=1)
- CALL KEYWORDS available on distributed indexes
- Grouping in UTC
- query_log_mode for custom log files permissions
- Field weights can be zero or negative
- max_query_time can now affect full-scans
- added net_wait_tm, net_throttle_accept and net_throttle_action for network thread fine tuning (in case of workers=thread_pool)
- COUNT DISTINCT works with facet searches
- IN can be used with JSON float arrays
- multi-query optimization is not broken anymore by integer/float expressions
- SHOW META shows a
multiplierrow when multi-query optimization is used
Manticore Search is built using cmake and the minimum gcc version required for compiling is 4.7.2.
- Manticore Search runs under
manticoreuser. - Default data folder is now
/var/lib/manticore/. - Default log folder is now
/var/log/manticore/. - Default pid folder is now
/var/run/manticore/.
- Commit a58c619 fixed SHOW COLLATION statement that breaks java connector
- Commit 631cf4e fixed crashes on processing distributed indexes; added locks to distributed index hash; removed move and copy operators from agent
- Commit 942bec0 fixed crashes on processing distributed indexes due to parallel reconnects
- Commit e5c1ed2 fixed crash at crash handler on store query to server log
- Commit 4a4bda5 fixed a crash with pooled attributes in multiqueries
- Commit 3873bfb fixed reduced core size by prevent index pages got included into core file
- Commit 11e6254 fixed searchd crashes on startup when invalid agents are specified
- Commit 4ca6350 fixed indexer reports error in sql_query_killlist query
- Commit 123a9f0 fixed fold_lemmas=1 vs hit count
- Commit cb99164 fixed inconsistent behavior of html_strip
- Commit e406761 fixed optimize rt index loose new settings; fixed optimize with sync option lock leaks;
- Commit 86aeb82 fixed processing erroneous multiqueries
- Commit 2645230 fixed result set depends on multi-query order
- Commit 72395d9 fixed server crash on multi-query with bad query
- Commit f353326 fixed shared to exclusive lock
- Commit 3754785 fixed server crash for query without indexes
- Commit 29f360e fixed dead lock of server
- Manticore branding